Hello and welcome to a post in which I intend to show you how to create your own implementation of drools and jBPM persistence. I’ve worked on an infinispan based persistence scheme for drools objects and I learnt a lot in the process. It’s my intention to give you a few pointers if you wish to do something of the sort.
Why?
If you’re reading this, you probably already have a “why” to redefine the persistence scheme that drools uses, but it’s good to go over some good reasons to do something like this. The most important thing is that you might consider the JPA persistence scheme designed for drools doesn’t meet your needs for one or more reasons. Some of the most common I’ve found are these:
The given model is not enough for my design:Current objects created to persist the drools components (sessions, process instances, work items and so on) currently are as small as possible to allow the best performance on the database, and most of the operational data is stored in byte arrays mapped to blob objects. This scheme is enough for the drools and jBPM runtime to function, but it might not be enough for your domain. You might want to keep the runtime information in a scheme that is easier to query from outside tools, and to do that you would need to enrich the data model, and even create one of your own.
The persistence I’m using is not compatible with JPA: There are a lot of persistence implementations out there that no longer use databases as we once knew (distributed caches, key value storages, NoSQL databases) and the model usually needs extra mappings and special treatment when persisting in such storages. To do so, sometimes JPA is not our cup of tea
I need to load special entities from different sources every time a drools component is loaded: When we have complex objects and/or external databases, sometimes we want new models to relate in a special way to the objects we have. Maybe we want to make sure our sessions are binded to our model in a special way because it makes sense to our business model. To do so we would have to alter the model
How?
In order to make our own persistence scheme for our sessions, we need to understand clearly how the JPA scheme is built, to use it as a template to build our own. This class diagram shows how the JPA persistence scheme for the knowledge session is implemented:
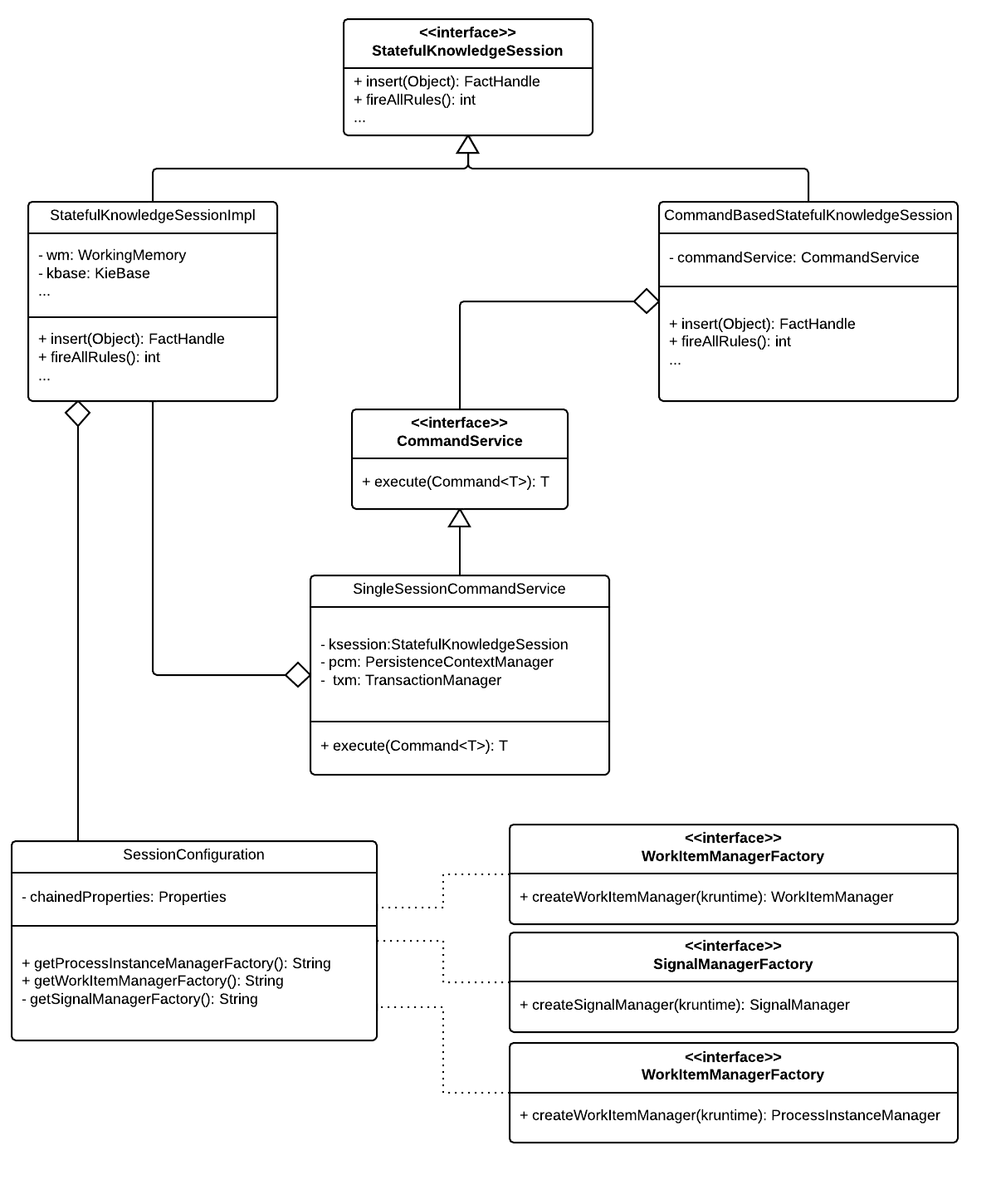
Looks complicated, right? Don’t worry. We’ll go step by step to understand how it works.
First of all, you can see that we have two implementations of the StatefulKnowledgeSession (or KieSession, if you’re using Drools 6). The one that does all the “drools magic” is StatefulKnoweldgeSessionImpl, and the one we will be using is CommandBasedStatefulKnowledgeSession. It has nothing to do with persistence, but it helps a lot with it by surrounding every method call with a command object and deriving its execution to a command service. So, for example, if you call the fireAllRules method to this type of session, it will create a FireAllRulesCommand object and give it to another class to execute.
This command based implementation allows us to do exactly the thing we need to implement persistence on a drools environment: It lets us implement actions before and after every method call done to the session. That’s where the SingleSessionCommandService
class comes in handy: This command service contains a StatefulKnowledgeSessionImpl and a PersistenceContextManager. Every time a command has to be executed, this class creates or loads a SessionInfo object and tells the persistence context to save it with all the state of the StatefulKnowledgeSessionImpl.
That’s the most complicated part: the one that implements the session persistence. Persistence of pretty much everything else is done easily through a set of given interfaces that provide methods to implement how to load everything else related to a session (process instances, work items and signals). As long as you create a proper manager and its factory, you can delegate on them to store anything to anywhere (or do anything you want, for that matter).
So, after seeing all the components, it’s a good time to start thinking of how to create our own implementation. For this example, we’ve created an Infinispan based persistence scheme and we will show you all the steps we took to do it.
Step 1: (re)define the model
Most of the time when we want to persist drools objects in our way, we might want to do it with a gist of your own. Even if we don’t wish to change the model, we might need to add special annotations to the model to work with your storage framework. Another reason might be that you want to store all facts in a special way to cross-query them with some other legacy system. You can literally do this redefinition any way you want, as long as you understand that whatever model you create, the persistence scheme will serialize and deserialize it every time you call a method on the knowledge session, so always try to keep it simple.
Here’s the model we created for this case:
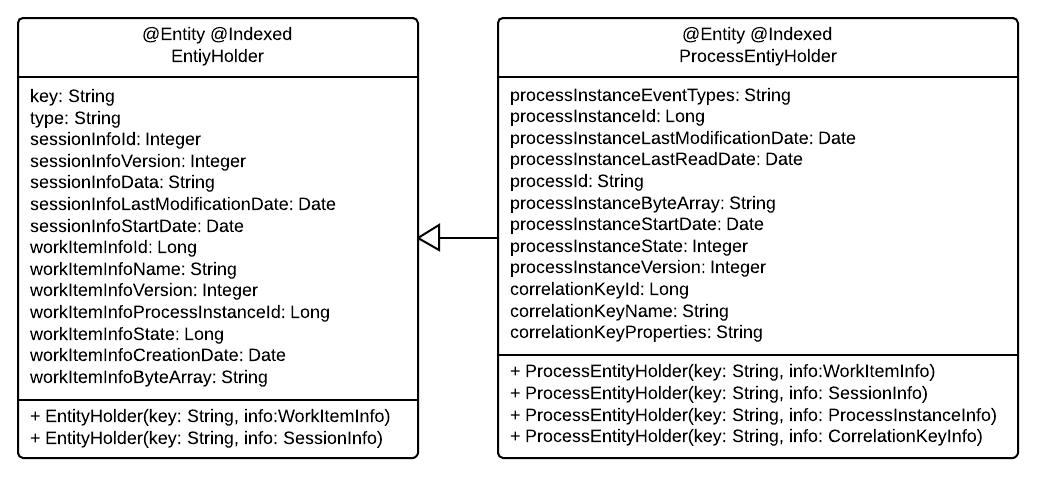
Nothing too fancy, just a flattened model for all things drools related. We weren’t too imaginative with this model, because we just wanted to show you that you can change it if you want to.
One thing to notice in this model is that we are still saving all the internal data of these objects pretty much the same way as it is stored for the JPA persistence. The only difference is that JPA stores it in a Blob, and we store it in a Base64 encrypted string. If you wish to change the way that byte array is generated and read, you have to create your own implementations of these interfaces:
- org.kie.api.marshalling.Marshaller for knowledge sessions
- org.jbpm.marshalling.impl.ProcessInstanceMarshaller for process instances
But providing an example of that would take way too much time and perhaps even a whole book to explain, so we’ll skip it.
Step 2: Implementing the PersistenceContext
For some cases, redefining the PersistenceContext and the PersistenceContextManager would be enough to implement all your persistence requirements. The PersistenceContext is an object in charge of persisting work items and session objects by implementing methods to persist them, query them by ID and removing them from a particular storage implementation. The PersistenceContextManager is in charge of creating the PersistenceContext, either once for all the application or on a per-command basis. The comand service will use it to persist the session and its objects when needed.
In our case we implemented a PersistenceContext and a PersistenceContextManager using an Infinispan cache as storage. The different PersistenceContextManager instances will have access to all configuration objects through the Environment variable. We’ve used the already defined keys in Environment to store our Infinispan related objects:
- EnvironmentName.ENTITY_MANAGER_FACTORY is used to store an Infinispan based CacheManager
- EnvironmentName.APP_SCOPED_ENTITY_MANAGER and EnvironmentName.CMD_SCOPED_ENTITY_MANAGER will point to an Infinispan Cache object.
You can see that code here:

At this point we have some very important steps to redefining our drools persistence. Now we need to know how to configure our knowledge sessions to work with this components.
Step 3: Creating managers for our work items, process instances and signals
Now that we have our persistence contexts, we need to teach the session how to use them properly. The knowledge session has a few managers that can be configured that allow you to modify or alter the default behaviour. These managers are:
- org.kie.api.runtime.process.WorkItemManager: It manages when a work item is executed, connects it with the proper handler, and notifies the process instance when the work item is completed.
- org.jbpm.process.instance.event.SignalManager: It manages when a signal is sent to or from a process. Since process instances might be passivated, it needs to
- org.jbpm.process.instance.ProcessInstanceManager: It manages the actions to be taken when a process instance is created, started, modified or completed.
JPA implementation of these interfaces already work with a persistence context manager, so most of the times you won’t need to extend them. However, with Infinispan, we have to make sure the process instance is persisted more often than with JPA, so we had to implement them differently.
Once you have these instances, you will need to create a factory for each type of manager.The interface names are the same, except with the suffix “Factory”. Each receives a knowledge session as parameter, from which you can get the Environment object and all other configurations.
Step 4: Configuring the knowledge session
Now that we have our different managers created, we will need to tell our knowledge sessions to use them. To do so you need to create a CommandBasedStatefulKnowledgeSession instance with a SingleSessionCommandService instance. The SingleSessionCommandService, as its name describes, is a class to execute commands against one session at a time. SingleSessionCommandService’s constructor receives all parameters needed to create a proper session and execute commands against it in a way that it becomes persistent. Those parameters are:
- KieBase: the knowledge base with the knowledge definitions for our session runtime.
- KieSessionConfiguration: Where we configure the manager factories to create and dispose of work items, process instances and signals.
- Environment: A bag of variables for any other purpose, where we will configure our persistence context mananager objects.
- sessionId (optional): If present, this parameter looks for an already existing session in the storage. Otherwise, it creates a new one.
Also, in our example, we’re using Infinispan, which is not a reference based storage, but a value based storage. This means that once you say to infinispan to store a value, it will store a copy of it and not the actual object. Some things in drools persistence are managed to be stored through reference based storages, meaning you can tell the framework to persist an object, change its attributes, and see those changes stored in the database after committing the transaction. With infinispan, this wouldn’t happen, so you have to implement an update of the cache values after the command execution is finished. Luckily for us, the SingleSessionCommandService allows us to do this by implementing an Interceptor.
Interceptors are basically your own command service to wrap the default one. You can tell each command to add more behaviour before or after each execution. Here’s a couple of diagrams to explain how it works:
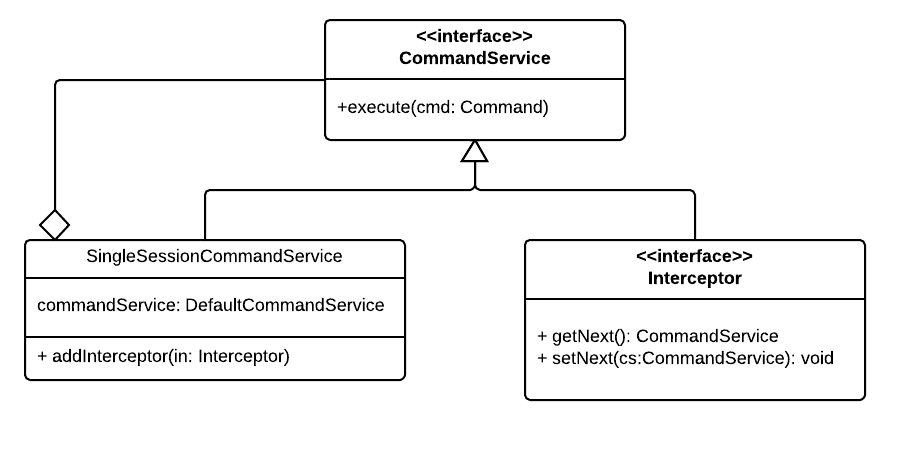
As you can see, the SingleSessionCommandService allows for a command service instance to actually invoke the command’s execute method. And thanks to the interceptor extension of the command service, we can add as many as we want in chain, allowing us to have something like the next sequence diagram executing every time a command needs execution:
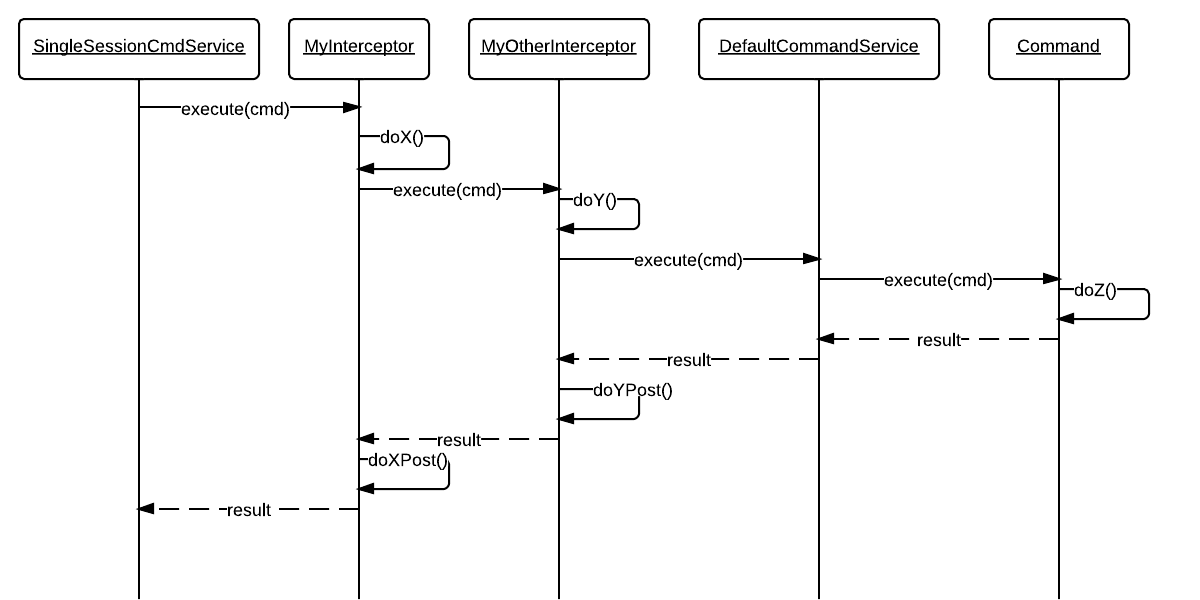
In our case, we created a couple of these interceptors and added them to the SingleSessionCommandService. One makes sure any changes done to a session object are stored after finishing the command. The other one allows us to do the same with process instance objects.
Overall, this is how we need to create our knowledge sessions at this point to actually use infinispan as a persistence scheme:
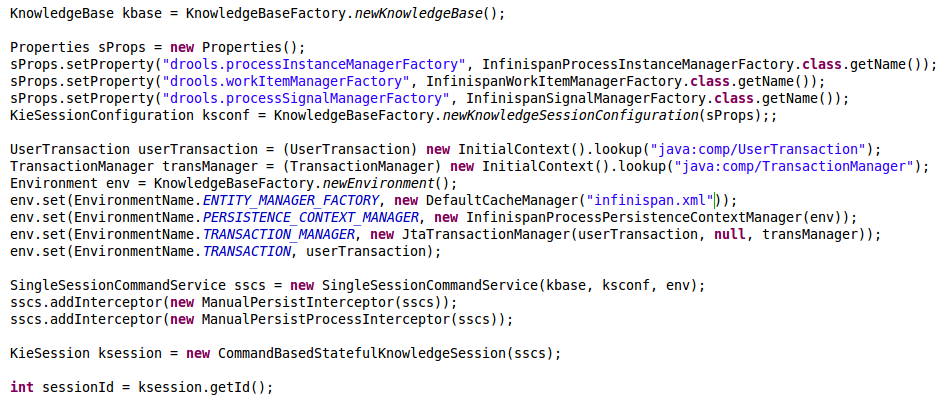
Complicated, right? Don’t worry. There’s yet another couple of classes to make it easier to configure.
Step 4: Creating our own initiation service
Yes, we could write that ton of code every time we want to create our own customized persistent knowledge sessions. It’s a free world (for the most part). But you can also wrap this implementation in a single class with two exposed methods:
- One to create a new session
- One to load a previously existing session
And creates all the configuration internally, merging it whenever you wish to change one or more things. Drools provides an interface to serve as a contract for this called org.kie.api.persistence.jpa.KieStoreServices
We created our own implementation of this interface and also a static class to access it, called InfinispanKnowledgeService. This allows us to be able to create the session like this:

Conclusion
Drools persistence can seem complicated to understand and to get working, let alone to implement it in your own way. However, I hope this shows a bit of demystification to those who need to implement drools persistence in a special way, or were even wondering if it is possible to do so in any other way than JPA.
Also, if you wish to see the modifications done to make it work, see these three pull requests:
- https://github.com/droolsjbpm/droolsjbpm-build-bootstrap/pull/38
- https://github.com/droolsjbpm/drools/pull/198
- https://github.com/droolsjbpm/jbpm/pull/166
A feature request to add this features to Drools is specified in this JIRA ticket. Feel free to upvote it if you wish to have it as part of the core drools project!
