Previous Chapter: Startup – Self Test
One very important mind set developers will have to adopt and practice is backward and forward compatibility.
Most production system do not consist on just one server, but a cluster of servers. When deploying new piece of code, you do not deploy it to all the servers at once because part of Continuous deployment strategy is zero downtime during deployment. If you deploy to all the servers at once and the deployment require a server restart then all the servers will restart at the same time causing a downtime.
Now think of the following scenario. You write a new code that requires a new field in a DTO and it is written to a database. Now if you deploy your servers gradually you will have a period of time that some servers will have the new code that uses the new field and some will not. The servers that have the new code will send the new field in the DTO and the servers that not yet deployed will not have the new field and will not recognize it.
One more important concept is to avoid deployment dependencies where you have to deploy one set of services before you deploy the other set. If we’ll use our previous example this will even make things worse. Let’s say you work with SOA architecture and you have now clients that send the new field and some clients that do not. Or you deploy the clients that now send the new field but you have not yet deployed the servers that can read them and might break. You might say, well I will not do that and I will first deploy the server that can read the new field and only after that I’ll deploy the client that sends it. However in Continuous deployment as easily as you can deploy new code you can also rollback you code. So even if you deploy first the server and then the client you might now roll back the server without rolling back the client, thus creating again the situation where clients send unknown fields to the server.
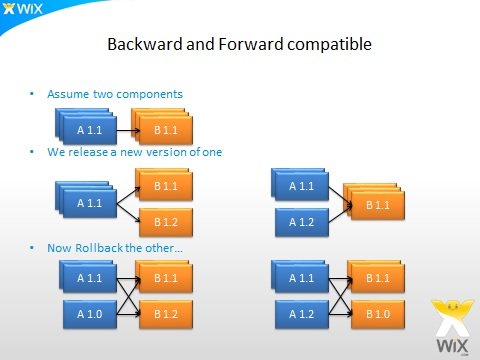
So here comes the next and highly important practice. ALL code has to be backward AND forward compatible. So what that means? In our previous example it is very simple. Old servers have to ignore unknown fields and parameters (this is the forward compatibility), your servers are resilient to API extension. Now new servers that do know how to handle the new field have to also handle old clients that do not send this new field. In our example they can simply use default value in case the clients have not been deployed yet and do not send the new field (This is backward compatibility).
In most cases backward compatibility is easier because it is new code that need to handle old clients. But forward compatibility is sometimes tricky because you have old code running that now need to handle a new use-case it was not designed to handle when it was initially written. If you reach a point where you know your old code cannot handle new data, a simple way of solving that problem is to release an intermediate version that first “teaches” the old code to gracefully handle new data it previously did not know; and after you are confident it works fine you can deploy the new code that actually uses the new data. Now if you need to roll back the new code your intermediate version could handle the pieces of data written by the rolled back code and ignore it gracefully without breaking.
At Wix we had an extreme case were due to a misconfiguration we rolled back our entire production system a whole month back. After we fixed it we realized that even though our system rolled back a whole month back, everything kept working with zero downtime because everything was backward and forward compatible and the servers handled new data written by a code that is newer. You can read more about our continuous rollback here.
