The classical RHQ setup assumes an agent and agent plugins being present on a machine (‘platform’ in RHQ-speak). Plugins then communicate with the managed resource (e.g. an AS7 server); ask it for metric values or run operations (e.g. ‘reboot’). This article shows an alternative way for monitoring applications at the example of the Ticket Monster application from the JBoss Developer Framework.![]()
![]()
The communication protocol between the plugin and the managed resource is dependent on the capabilities of that resource. If the resource is a java process, JMX is often used. In the case of JBoss AS 7, we use the DMR over http protocol. For
other kinds of resources this could also be file access or jdbc in case of databases. The next picture shows this setup.
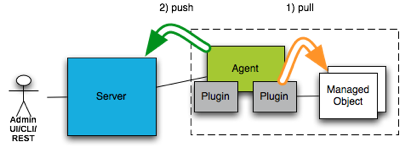
The agent plugin talks to the managed resource and pulls the metrics from it. The agent collects the metrics from multiple resources and then sends them as batches to the RHQ server, where it is stored, processed for alerting and can be viewed in the UI or retrieved via CLI and REST-api.
Extending
The above scenario is of course not limited to infrastructure and can also be used to monitor applications that sit inside e.g. AS7. You can write a plugin that uses the underlying connection to talk to the resource and gather statistics from there (if you build on top of the jmx or as7 plugin, you don’t necessarily need to write java-code). This also means that you need to add hooks to your application that export metrics and make them available in the management model (the MBean-Server in classical jre; the DMR model in AS7), so that the plugin can retrieve them.
Pushing from the application
Another way to monitor application data is to have the application push data to the RHQ-server directly. In this case you still need to have a plugin descriptor in order to define the meta data in the RHQ server (what kinds of resources and metrics exist, what units do the metrics have etc.). In this case you only need to define the descriptor and don’t write java code for the plugin. This works by inheriting from the No-op plugin. In addition to that, you can also just deploy that descriptor as jar-less plugin. The next graphic shows the setup:
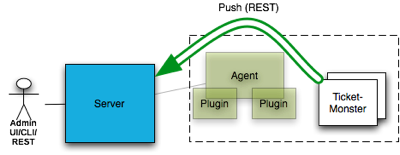
In this scenario you can still have an agent with plugins on the platform, but this is not required (but recommended for basic infrastructure monitoring). On the server side we deploy the ticket-monster plugin descriptor. The TicketMonster application has been augmented to push each booking to the RHQ server as two metrics for total number of tickets sold and the total price of the booking(BookingService.createBooking()).
@Stateless
public class BookingService extends BaseEntityService<Booking> {
@Inject
private RhqClient rhqClient;
public Response createBooking(BookingRequest bookingRequest) {
[…]
// Persist the booking, including cascaded relationships
booking.setPerformance(performance);
booking.setCancellationCode("abc");
getEntityManager().persist(booking);
newBookingEvent.fire(booking);
rhqClient.reportBooking(booking);
return Response.ok().entity(booking)
.type(MediaType.APPLICATION_JSON_TYPE).build();This push happens over a http connection to the REST-api of the RHQ server, which is defined inside the RhqClient singleton bean. In this RhqClient bean we read the rhq.properties file on startup to determine if there should be any reporting at all and how to access the server. If reporting is enabled we try to find the platform we are running on and if the RHQ server does not know about it, create it. On top of the platform we create the TicketMonster instance. This is safe to do multiple times, as would be the platform creation – I am looking for an existing platform where an agent might perhaps already monitor the basic data like cpu usage or disk utilization. The reporting of the metrics then looks like this:
@Asynchronous
public void reportBooking(Booking booking) {
if (reportTo && initialized) {
List<Metric> metrics = new ArrayList<Metric>(2);
Metric m = new Metric("tickets",
System.currentTimeMillis(),
(double) booking.getTickets().size());
metrics.add(m);
m = new Metric("price",
System.currentTimeMillis(),
(double) booking.getTotalTicketPrice());
metrics.add(m);
sendMetrics(metrics, ticketMonsterServerId);
}
}Basically we construct two Metric objects and then send them to the RHQ-Server. The second parameter is the resource id of the TicketMonster server resource in the RHQ-server, which we have obtained from the create-request I’ve mentioned above. A difference to the classical setup where the MeasurementData objects inside RHQ always have a so called schedule id associated is that in the above case we pass the metric name as is appears in the deployment descriptor and let the RHQ server sort out the schedule id.
<metric property="tickets" dataType="measurement"
displayType="summary" description="Total number tickets sold"/>
<metric property="price"
displayType="summary" description="Total selling price"/>And voilà this what the sales look like that are created from the Bot inside TicketMonster:
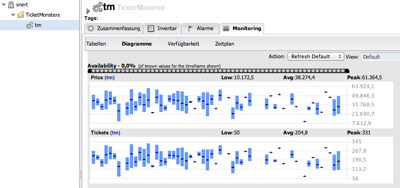
The display interval has been set to ‘last 12 minutes’. If you see a bar, that means that within the timeslot of 12mins/60 slots = 12sec, there were multiple bookings. In this case the bar shows the max and min value, while the little dot inside shows the average (via Rest-Api it is still possible to see the individual values for the last 7 days).
Why would I want to do that?
The question here is of course why would I want to send my business metrics to the RHQ server, that is normally used for my infrastructure monitoring? Because we can! Seriously such business metrics are also able to indicate issues. If e.g. the number of ticket bookings is unusually high or low, this can also be a source of concern and warrants an alert. Take the example of E-Shops that sell electronics and where it happened that someone made a typo and offered laptops that are normally sold at €1300 and are now selling at €130. That news is quickly spread via social networks and sales triple over their normal numbers. Here monitoring the number of laptops sold can be helpful. The other reason is that RHQ with its user concept allows to set up special users that only have (read) access to the TicketMonster resources, but not to other resources inside RHQ. This way it is possible to give the business people access to the metrics from monitoring the ticket sales.
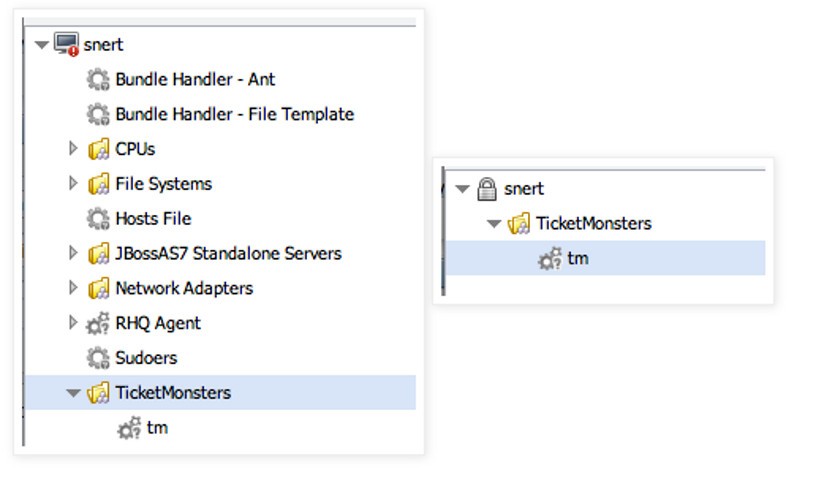
On the left you see the resource tree below the platform ‘snert’ with all the resources as e.g. the ‘rhqadmin’ user sees it. On the right side, you see the tree as a user that only has the right to see the TicketMonster server (™’).
TODOs
The above is a proof of concept to get this started. There are still some things left to do:
- Create sub-resorces for performances and report their booking separately
- Regularly report availability of the TicketMonster server
- Better separate out the internal code that still lives in the
RhqClientclass - Get the above incorporated into TicketMonster propper – currently it lives in my private github repo
- Decide how to better handle an RHQ server that is temporarily unavailable
- Get Forge to create the ‘send metric / … ‘ code automatically when a class or field has some special annotation for this purpose. Same for the creation of new items like Performances in the ™ case.
If you want to try it, you need a current copy of RHQ master — the upcoming RHQ 4.6 release will have some of the changes on RHQ side that are needed. The RHQ 4.6 beta does not yet have them.
Reference: Monitoring the monster with RHQ from our JCG partner Heiko Rupp at the Some things to remember blog.

Hir
I have started working on hyperic HQ.
I could not get why RHQ is preffered over hyperic HQ. Could you please let me know how RHQ is going to be useful .