These boxes with huge cores comes with Non-Uniform Memory Access (NUMA) Architecture. NUMA is an architecture which boosts the performance of memory access for local nodes. These new hardware boxes are divided into different zones called Nodes. These nodes have a certain number of cores alloted with a portion of memory alloted to them. So for the box with 1 TB RAM and 80 Cores, we have 4 nodes each having 20 cores and 256 GB of memory alloted.
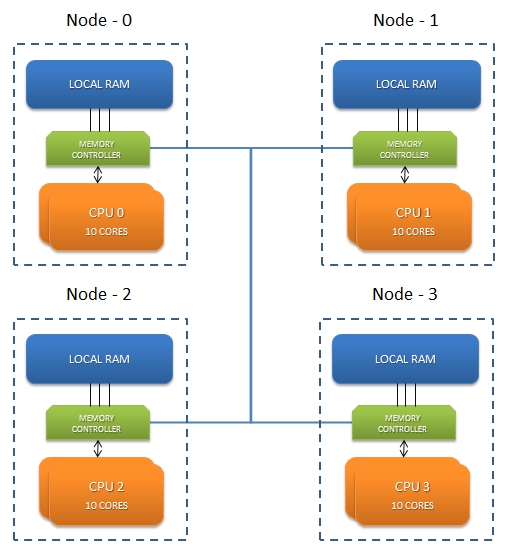
You can check that using command, numactl --hardware
>numactl --hardware available: 4 nodes (0-3) node 0 size: 258508 MB node 0 free: 186566 MB node 1 size: 258560 MB node 1 free: 237408 MB node 2 size: 258560 MB node 2 free: 234198 MB node 3 size: 256540 MB node 3 free: 237182 MB node distances: node 0 1 2 3 0: 10 20 20 20 1: 20 10 20 20 2: 20 20 10 20 3: 20 20 20 10
When JVM starts it starts thread which are scheduled on the cores in some random nodes. Each thread uses its local memory to be fastest as possible. Thread might be in WAITING state at some point and gets rescheduled on CPU. This time its not guaranteed that it will be on same node. Now this time, it has to access a remote memory location which adds latency. Remote memory access is slower, because the instructions has to traverse a interconnect link which introduces additional hops.
Linux command numactl provides a way to bind the process to certain nodes only. It locks a process to a specific node both for execution and memory allocation. If a JVM instance is locked to a single node then the inter node traffic is removed and all memory access will happen on the fast local memory.
numactl --cpunodebind=nodes, -c nodes Only execute process on the CPUs of nodes.
Created a small test which tries to serialize a big object and calculates the transactions per sec and latency.
To execute a java process bound to one node execute
numactl --cpunodebind=0 java -Dthreads=10 -jar serializationTest.jar
Ran this test on two different boxes.
Box A
4 CPU x 10 cores x 2 (hyperthreading) = Total of 80 cores
Nodes: 0,1,2,3
Box B
2 CPU x 10 cores x 2 (hyperthreading) = Total of 40 cores
Nodes: 0,1
CPU Speed : 2.4 Ghz for both.
Default settings are too use all nodes available on boxes.
| Box | NUMA policy | TPS | Latency (Avg) | Latency (Min) |
| A | Default | 261 | 37 | 18 |
| B | Default | 387 | 25 | 5 |
| A | –cpunodebind=0,1 | 405 | 23 | 3 |
| B | –cpunodebind=0 | 1,613 | 5 | 3 |
| A | –cpunodebind=0 | 1,619 | 5 | 3 |
So we can infer that the default settings on Box A with more Nodes is performing low on a ‘CPU-intesive’ test compared to default setting on 2-node Box B. But as we bind the process to only 2 nodes, it performs equally better. Probably, because it has lesser nodes to hop and probability of threads getting rescheduled on same is increased to 50%.
With --cpunodebind=0, it just outperforms all the cases.
NOTE: Above test was run with 10 threads on 10 core.
Test Jar: download
Test Sources: download
Reference: NUMA & Java from our JCG partner Himadri Singh at the Billions & Terabytes blog.
