Tomasz Nurkiewicz, one of our JCG partners, has recently written a very nice article on how to use async processing in order to increase your server’s throughput. Let’s find out how he did it.
(NOTE: The original post has been slightly edited to improve readability)
It is not a secret that Java servlet containers aren’t particularly suited for handling large amount of concurrent users. Commonly established thread-per-request model effectively limits the number of concurrent connections to the number of concurrently running threads JVM can handle. And because every new thread introduces significant increase of memory footprint and CPU utilization (context switches), handling more than 100-200 concurrent connections seems like a ridiculous idea in Java. At least it was in pre-Servlet 3.0 era.
In this article we will write a scalable and robust file server with throttled speed limit. In a second version, leveraging the Servlet 3.0 asynchronous processing feature, we will be able to handle ten times bigger load using even less threads. No additional hardware required, just few wise design decisions.
Token bucket algorithm
Building a file server, we have to consciously manage our resources, especially network bandwidth. We don’t want a single client to consume the whole traffic, we might even want to throttle the download limit dynamically at runtime, based on user, time of the day, etc. – and of course everything happens during heavy load. Developers love reinventing the wheel, however all our requirements are already addressed by the simple token bucket algorithm.
The explanation in Wikipedia is pretty good, but since we’ll adjust the algorithm a bit for our needs, here’s even simpler description. First there was a bucket. In this bucket there were uniform tokens. Each token is worth 20 kiB (I will be using real values from our application) of raw data. Every time a client asks for a file, the server tries to take one token from the bucket. If it succeeds, he sends 20 kiB to the client. Repeat last two sentences. What if the server fails to obtain the token because the bucket is already empty? He waits.
So where are the tokens coming from? Background process fill the bucket from time to time. Now it becomes clear. If this background process adds 100 new tokens every 100 ms (10 times per second), each worth 20 kiB, the server is capable of sending 20 MiB/s (100 times 20 kiB times 10) max, shared amongst all the clients. Of course if the bucket is full (1000 tokens), new tokens are ignored. This works amazingly well – if bucket is empty, clients are waiting for next bucket filling cycle; and by controlling the bucket capacity we can limit total bandwidth.
Enough talking, our simplistic implementation of token bucket starts with an interface (whole source code is available on GitHub in global-bucket branch):
public interface TokenBucket {
int TOKEN_PERMIT_SIZE = 1024 * 20;
void takeBlocking() throws InterruptedException;
void takeBlocking(int howMany) throws InterruptedException;
boolean tryTake();
boolean tryTake(int howMany);
}
takeBlocking() methods are waiting synchronously for the token to become available, while tryTake() are taking token only if it is available, returning true immediately if taken, false otherwise. Fortunately, the term bucket is just an abstraction: because tokens are indistinguishable, all we need to implement as bucket is an integer counter. But because the bucket is inherently multi-threaded and some waiting is involved, we need more sophisticated mechanism. Semaphore seems to be almost ideal:
@Service
@ManagedResource
public class GlobalTokenBucket extends TokenBucketSupport {
private final Semaphore bucketSize = new Semaphore(0, false);
private volatile int bucketCapacity = 1000;
public static final int BUCKET_FILLS_PER_SECOND = 10;
@Override
public void takeBlocking(int howMany) throws InterruptedException {
bucketSize.acquire(howMany);
}
@Override
public boolean tryTake(int howMany) {
return bucketSize.tryAcquire(howMany);
}
}
Semaphore fits exactly to our requirements. bucketSize represents current amount of tokens in the bucket. bucketCapacity on the other hand limits the bucket maximum size. It is volatile because it can be modified via JMX (visibility):
@ManagedAttribute
public int getBucketCapacity() {
return bucketCapacity;
}
@ManagedAttribute
public void setBucketCapacity(int bucketCapacity) {
isTrue(bucketCapacity >= 0);
this.bucketCapacity = bucketCapacity;
}
As you can see I am using Spring and its support for JMX. Spring framework isn’t absolutely necessary in this application, but it brings some nice features. For instance implementing a background process that periodically fills the bucket looks like this:
@Scheduled(fixedRate = 1000 / BUCKET_FILLS_PER_SECOND)
public void fillBucket() {
final int releaseCount =
min(bucketCapacity / BUCKET_FILLS_PER_SECOND,
bucketCapacity - bucketSize.availablePermits());
bucketSize.release(releaseCount);
}
This code contains major multi-threading bug that we can ignore for the purposes of this article. It is suppose to fill the bucket up to the maximum value – will it always work?
Moreover, here is the XML snippet (applicationContext.xml) required to make @Scheduled annotation work:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-3.0.xsd">
<context:component-scan base-package="com.blogspot.nurkiewicz.download" />
<context:mbean-export/>
<task:annotation-driven scheduler="bucketFillWorker"/>
<task:scheduler id="bucketFillWorker" pool-size="1"/>
</beans>
Having token bucket abstraction and very basic implementation we can develop the actual servlet returning files. I am always returning the same fixed file with size of almost 200 kiB):
@WebServlet(urlPatterns = "/*", name="downloadServletHandler")
public class DownloadServlet extends HttpRequestHandlerServlet {}
@Service
public class DownloadServletHandler implements HttpRequestHandler {
private static final Logger log =
LoggerFactory.getLogger(DownloadServletHandler.class);
@Resource
private TokenBucket tokenBucket;
@Override
public void handleRequest(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar");
final BufferedInputStream input =
new BufferedInputStream(new FileInputStream(file));
try {
response.setContentLength((int) file.length());
sendFile(request, response, input);
} catch (InterruptedException e) {
log.error("Download interrupted", e);
} finally {
input.close();
}
}
private void sendFile(HttpServletRequest request,
HttpServletResponse response, BufferedInputStream input)
throws IOException, InterruptedException {
byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE];
final ServletOutputStream outputStream = response.getOutputStream();
for (int count = input.read(buffer); count > 0; count = input.read(buffer)) {
tokenBucket.takeBlocking();
outputStream.write(buffer, 0, count);
}
}
}
HttpRequestHandlerServlet was used here. As simple as can be: read 20 kiB of file, take the token from the bucket (waiting if unavailable), send chunk to the client, repeat until the end of file.
Believe it or not, this actually works! No matter how many (or how few) clients are concurrently accessing this servlet, total outgoing network bandwidth never exceeds 20 MiB! The algorithm works and I hope you get some basic feeling how to use it. But let’s face it – global limit is way too inflexible and kind of lame – single client can actually consume your whole bandwidth.
So what if we had a separate bucket for each client? Instead of one semaphore – a map? Each client has a separate independent bandwidth limit, so there is no risk of starvation. But there is even more:
some clients might be more privileged, having bigger or no limit at all,
some might be black listed, resulting in connection rejection or very low throughput
banning IPs, requiring authentication, cookie/user agent verification, etc.
we might try to correlate concurrent requests coming from the same client and use the same bucket for all of them to avoid cheating by opening several connections. We might also reject subsequent connections
and much more…
Our bucket interface grows allowing the implementation to take advantage of the new possibilities (see branch per-request-synch):
public interface TokenBucket {
void takeBlocking(ServletRequest req) throws InterruptedException;
void takeBlocking(ServletRequest req, int howMany) throws InterruptedException;
boolean tryTake(ServletRequest req);
boolean tryTake(ServletRequest req, int howMany);
void completed(ServletRequest req);
}
public class PerRequestTokenBucket extends TokenBucketSupport {
private final ConcurrentMap<Long, Semaphore> bucketSizeByRequestNo = new ConcurrentHashMap<Long, Semaphore>();
@Override
public void takeBlocking(ServletRequest req, int howMany) throws InterruptedException {
getCount(req).acquire(howMany);
}
@Override
public boolean tryTake(ServletRequest req, int howMany) {
return getCount(req).tryAcquire(howMany);
}
@Override
public void completed(ServletRequest req) {
bucketSizeByRequestNo.remove(getRequestNo(req));
}
private Semaphore getCount(ServletRequest req) {
final Semaphore semaphore = bucketSizeByRequestNo.get(getRequestNo(req));
if (semaphore == null) {
final Semaphore newSemaphore = new Semaphore(0, false);
bucketSizeByRequestNo.putIfAbsent(getRequestNo(req), newSemaphore);
return newSemaphore;
} else {
return semaphore;
}
}
private Long getRequestNo(ServletRequest req) {
final Long reqNo = (Long) req.getAttribute(REQUEST_NO);
if (reqNo == null) {
throw new IllegalAccessError("Request # not found in: " + req);
}
return reqNo;
}
}
The implementation is very similar (full class here) except that the single semaphore was replaced by map. I am not using request object itself as a map key for various reasons but a unique request number that I am assigning manually when receiving new connection. Calling completed() is very important, otherwise the map would grow continuously leading to memory leak. All in all, the token bucket implementation haven’t changed a lot, also the download servlet is almost the same (except passing request to token bucket). We are now ready for some stress testing!
Throughput Testing
For the testing purposes we will use JMeter with this wonderful set of plugins. During the 20-minute testing session we warm up our server firing up one new thread (concurrent connection) every 6 seconds to reach 100 threads after 10 minutes. For the next ten minutes we will keep 100 concurrent connections to see how stable the server works. Here are the active threads over time:
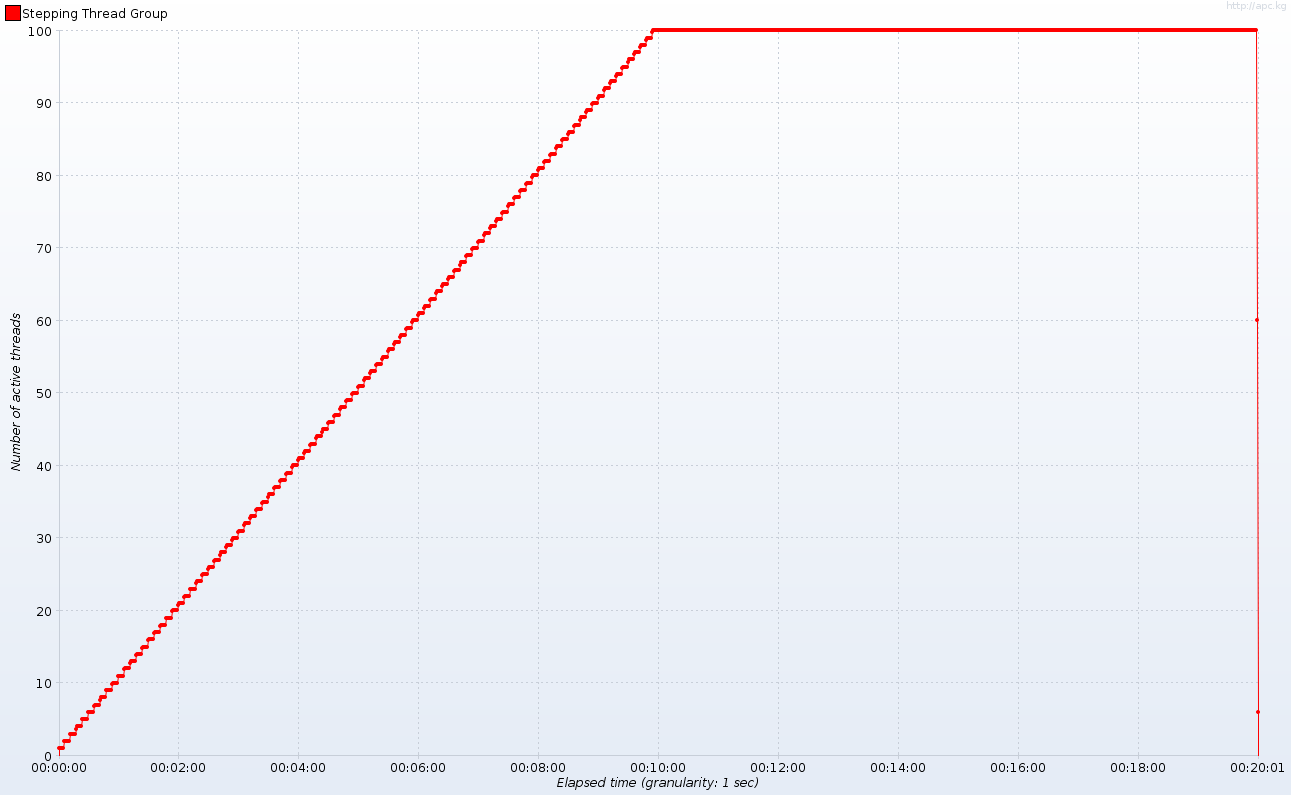
Important note: I artificially lowered the number of HTTP worker threads to 10 in Tomcat (7.0.10 tested). This is a far from real configuration, but I wanted to emphasize some phenomena that occur with high load compared to server capabilities. With default pool size I would need several client machines running distributed JMeter session to generate enough traffic. If you have a server farm or couple of servers in the cloud (as opposed to my 3-year-old laptop), I would be delighted to see the results in more realistic environment.
Remembering how many HTTP worker threads are available in Tomcat, response times over time are far from satisfactory:
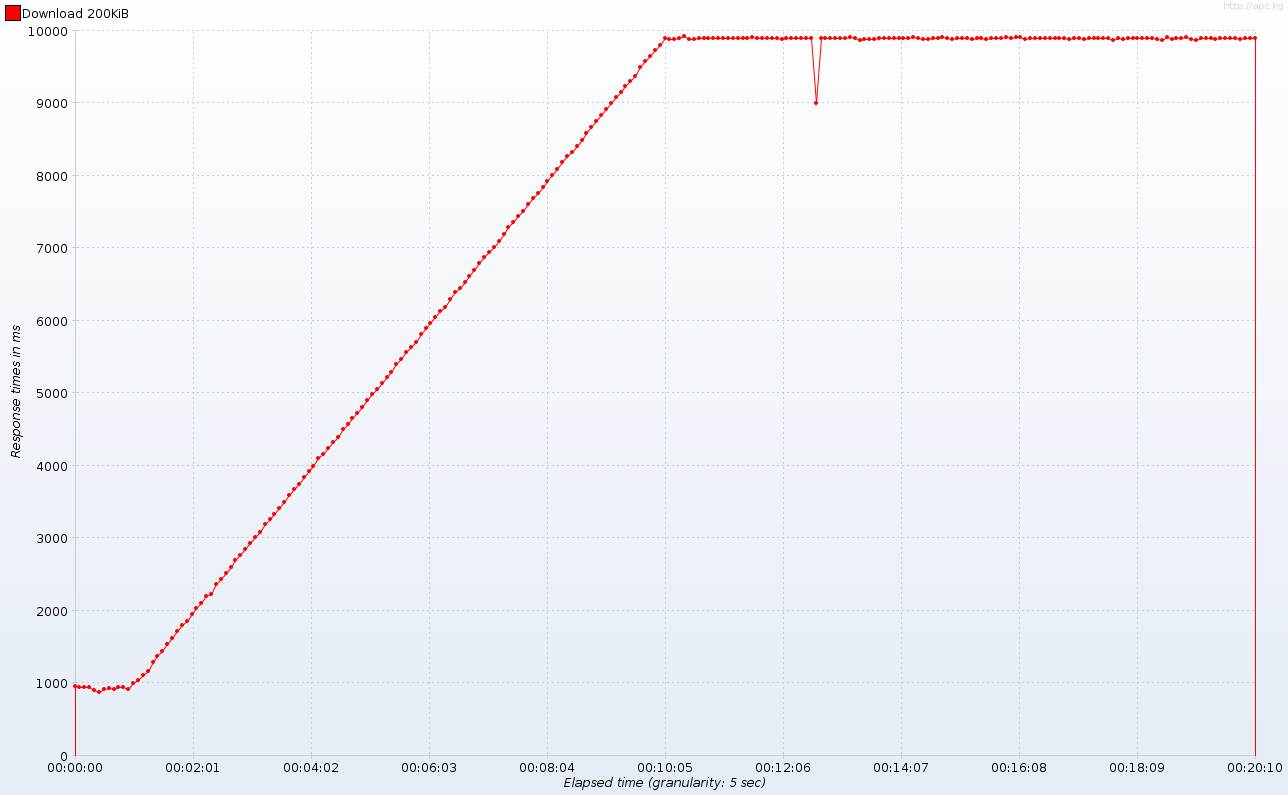
Please note the plateau at the beginning of the test: after about a minute (hint: when the number of concurrent connections exceeds 10) response times are skyrocketing to stabilize at around 10 seconds after 10 minutes (number of concurrent connections reaches one hundred). Once again: the same behavior would occur with 100 worker threads and 1000 concurrent connections – it’s just a matter of scale. The response latencies graph (time between sending request and receiving first lines of response) clears any doubts:
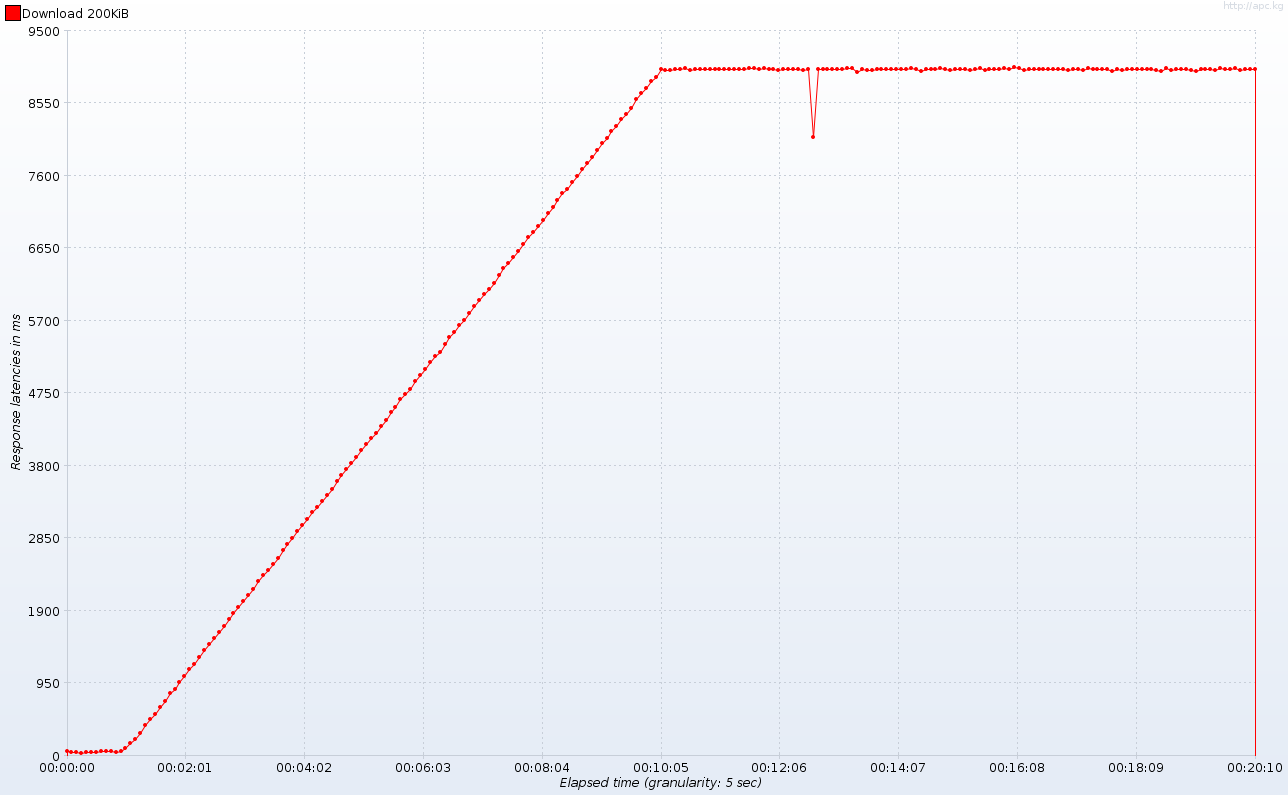
Below the magical number of 10 threads our application responds almost instantly. This is really important for clients as receiving only headers (especially Content-Type and Content-Length) allows them to more accurately inform the user what is going on. So what is the reason of Tomcat waiting with the response? No magic here really. We have only 10 threads and each connection requires one thread, so Tomcat (and any other pre-Servlet 3.0 container) handles 10 clients while the remaining 90 are… queued. The moment one of the 10 lucky ones is done, one connection from the queue is taken. This explains average 9 second latency whilst the servlet needs only 1 second to serve the request (200 kiB with 20 kiB/s limit). If you are still not convinced, Tomcat provides nice JMX indicators showing how many threads are occupied and how many requests are queued:
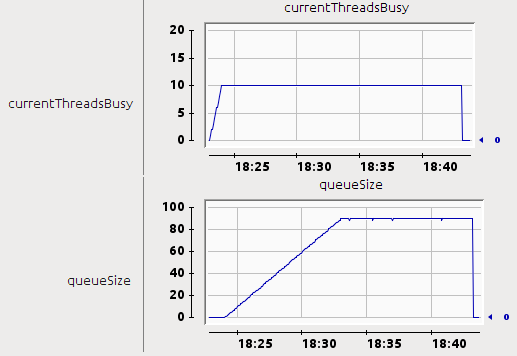
With traditional servlets there is nothing we can do. Throughput is horrible but increasing the total number of threads is not an option (think: from 100 to 1000). But you don’t actually need a profiler to discover that threads aren’t the true bottleneck here. Look carefully at DownloadServletHandler, where do you think most of the time is spent? Reading a file? Sending data back to the client? No, the servlet waits… And then waits even more. Non-productively hanging on semaphore – thankfully CPU is not harmed, but what if it was implemented using busy waiting? Luckily Tomcat 7 finally supports…
Servlet 3.0 asynchronous processing
We are this close to increase our server capacity by an order of magnitude, but some non-trivial changes are required (see master branch). First, download servlet needs to be marked as asynchronous (OK, this is still trivial):
@WebServlet(urlPatterns = "/*", name="downloadServletHandler", asyncSupported = true)
public class DownloadServlet extends HttpRequestHandlerServlet {}
The main change occurs in download handler. Instead of sending the whole file in a loop with lots of waiting (takeBlocking()) involved, we are splitting the loop into separate iterations, each wrapped inside Callable. Now we will utilize a small thread pool that will be shared by all awaiting connections. Each task in the pool is very simple: instead of waiting for a token, it asks for it in a non-blocking fashion (tryTake()). If the token is available, piece of the file is sent to the client (sendChunkWorthOneToken()). If the token is not available (bucket is empty), nothing happens. No matter whether the token was available or not, the task resubmits itself to the queue for further processing (this is essentially very fancy, multi-threaded loop). Because there is only one pool, the task lands at the end of the queue allowing other connections to be served.
@Service
public class DownloadServletHandler implements HttpRequestHandler {
@Resource
private TokenBucket tokenBucket;
@Resource
private ThreadPoolTaskExecutor downloadWorkersPool;
@Override
public void handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
final File file = new File("/home/dev/tmp/ehcache-1.6.2.jar");
response.setContentLength((int) file.length());
final BufferedInputStream input = new BufferedInputStream(new FileInputStream(file));
final AsyncContext asyncContext = request.startAsync(request, response);
downloadWorkersPool.submit(new DownloadChunkTask(asyncContext, input));
}
private class DownloadChunkTask implements Callable<Void> {
private final BufferedInputStream fileInputStream;
private final byte[] buffer = new byte[TokenBucket.TOKEN_PERMIT_SIZE];
private final AsyncContext ctx;
public DownloadChunkTask(AsyncContext ctx, BufferedInputStream fileInputStream) throws IOException {
this.ctx = ctx;
this.fileInputStream = fileInputStream;
}
@Override
public Void call() throws Exception {
try {
if (tokenBucket.tryTake(ctx.getRequest())) {
sendChunkWorthOneToken();
} else
downloadWorkersPool.submit(this);
} catch (Exception e) {
log.error("", e);
done();
}
return null;
}
private void sendChunkWorthOneToken() throws IOException {
final int bytesCount = fileInputStream.read(buffer);
ctx.getResponse().getOutputStream().write(buffer, 0, bytesCount);
if (bytesCount < buffer.length)
done();
else
downloadWorkersPool.submit(this);
}
private void done() throws IOException {
fileInputStream.close();
tokenBucket.completed(ctx.getRequest());
ctx.complete();
}
}
}
I am leaving the details of Servlet 3.0 API, there are plenty of less sophisticated examples throughout the Internet. Just remember to call startAsync() and work with returned AsyncContext instead of plain request and response.
BTW creating a thread pool using Spring is childishly easy (and we get nice thread names as opposed to Executors and ExecutorService):
That’s right, one thread is enough to serve one hundred concurrent clients. See for yourself (the amount of HTTP worker threads is still 10 and yes, the scale is in milliseconds).
Response Times over Time

Response Latencies over Time
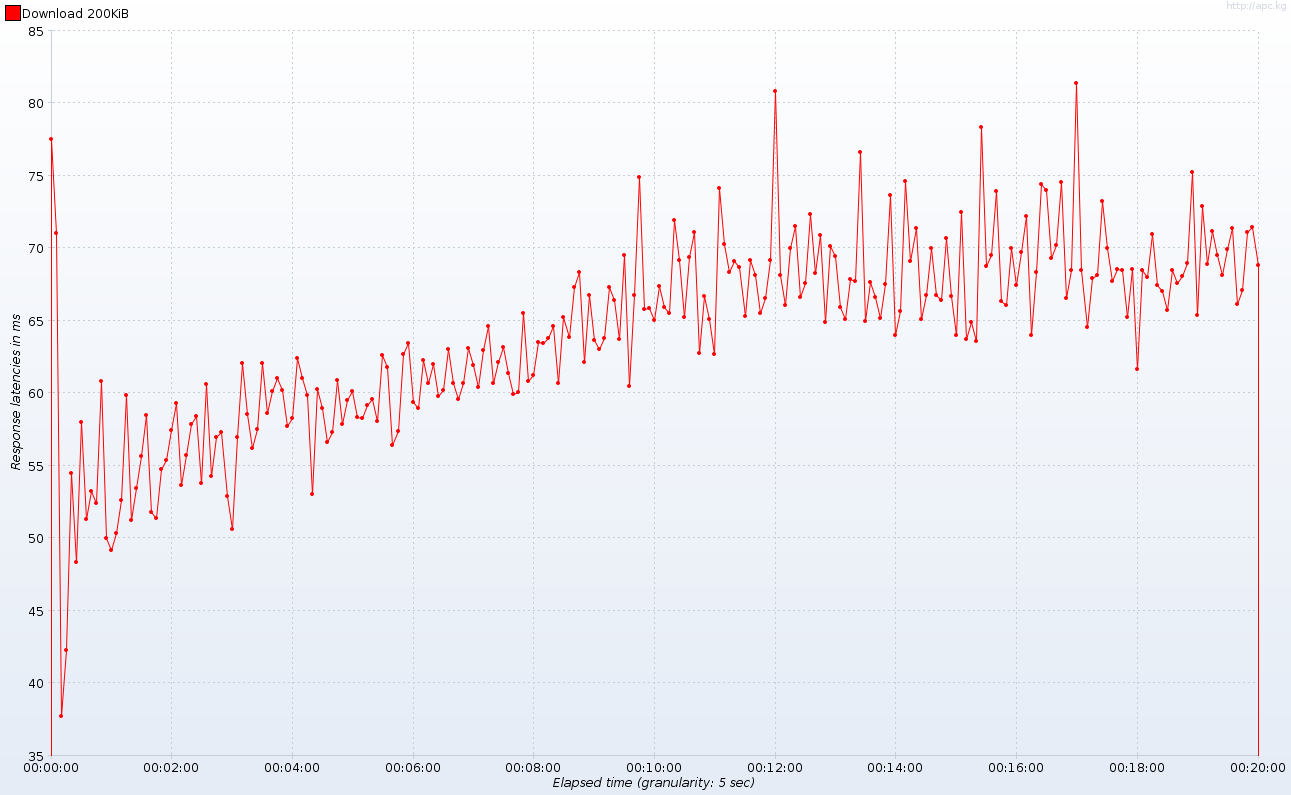
As you can see, response times when one hundred clients are downloading a file concurrently are only about 5% higher compared to the system with almost no load. Also response latencies aren’t particularly harmed by increasing load. I can’t push the server even further due to my limited hardware resources, but I have reasons to believe that this simple application would handle even twice as more connection: both HTTP threads and download worker thread weren’t fully utilized during the whole test. This also means that we have increased our server capacity 10 times without even using all the threads!
Hope you enjoyed this article. Of course not every use case can be scaled so easily, but next time you’ll notice your servlet is mainly waiting – don’t waste HTTP threads and consider servlet 3.0 asynchronous processing. And test, measure and compare! The complete application source codes are available (look at different branches), including JMeter test plan.
Areas of improvement
There are still several places that require attention and improvement. If you want to, don’t hesitate, fork, modify and test:
- While profiling I discovered that in more than 80% of executions DownloadChunkTask does not acquire a token and only reschedules itself. This is an awful waste of CPU time that can be fixed quite easily (how?)
- Consider opening a file and sending content length in a worker thread rather than in an HTTP thread (before starting asynchronous context)
- How can one implement global limit on top of bandwidth limits per request? You have at least couple of choice: either limit the size of download workers pool queue and reject executions or wrap PerRequestTokenBucket with reimplemented GlobalTokenBucket (decorator pattern)
- TokenBucket.tryTake() method does clearly violate Command-query separation principle. Could you suggest how it should look like to follow it? Why it is so hard?
- I am aware that my test constantly reads the same small file, so the I/O performance impact is minimal. But in real life scenario some caching layer would have certainly be applied on top of disk storage. So the difference is not that big (now the application uses very small amount of memory, lots of place for cache).
Lessons Learned
- Loopback interface is not infinitely fast. In fact on my machine localhost was incapable of processing more than 80 MiB/s.
- I don’t use plain request object as a key in bucketSizeByRequestNo. First of all, there are no guarantees on equals() and hashCode() for this interface. And more importantly – read the next point…
- With servlets 3.0 when processing the request you have to call completed() explicitly to flush and close the connection. Obviously after calling this method request and response objects are useless. What wasn’t obvious (and I learned that the hard why) is that Tomcat reuses request objects (pooling) and some of their contents for subsequent connections. This means that the following code is incorrect and dangerous, possibly resulting in accessing/corrupting other requests’ attributes or even session (?!?)
ctx.complete();
ctx.getRequest().getAttribute("SOME_KEY");
That’s it. A very nice tutorial on increasing a server’s throughput by using Servlet 3.0 async processing by Tomasz Nurkiewicz, one of our JCG partners. Don’t forget to share!
Related Articles:

Hey good article but I think you a spreading a myth: “100-200 connection” limit in blocking IO. The “10K problem” with blocking IO was a real problem in the late 90’s maybe early 00’s mostly because of inefficient thread implementations (for instance Linux 2.4 and earlier) but not today. In my previous project we had Tomcat running a conservative 3000 threads per node. The stack space required per thread and the context switching was no issue at all. We had to “down throttle” to 3000 threads because of external dependencies that we could have easily overloaded. Use cases where thread… Read more »
Why XML config?