There has been a lot of hype about the buzzword “web scale“, and people are going through lengths of reorganising their application architecture to get their systems to “scale”.
But what is scaling, and how can we make sure that we can scale?
Different aspects of scaling
The hype mentioned above is mostly about scaling load, i.e. to make sure that a system that works for 1 user will also work well for 10 users, or 100 users, or millions. Ideally, your system is as “stateless” as possible such that the few pieces of state that really remain can be transferred and transformed on any processing unit in your network. When load is your problem, latency is probably not, so it’s OK if individual requests take 50-100ms. This is often also referred to as scaling out
An entirely different aspect of scaling is about scaling performance, i.e. to make sure that an algorithm that works for 1 piece of information will also work well for 10 pieces, or 100 pieces, or millions. Whether this type of scaling is feasible is best described by Big O Notation. Latency is the killer when scaling performance. You want to do everything possible to keep all calculation on a single machine. This is often also referred to as scaling up
If there was anything like free lunch (there isn’t), we could indefinitely combine scaling up and out. Anyway, today, we’re going to look at some very easy ways to improve things on the performance side.
Big O Notation
Java 7’s ForkJoinPool as well as Java 8’s parallel Stream help parallelising stuff, which is great when you deploy your Java program onto a multi-core processor machine. The advantage of such parallelism compared to scaling across different machines on your network is the fact that you can almost completely eliminate latency effects, as all cores can access the same memory.
But don’t be fooled by the effect that parallelism has! Remember the following two things:
- Parallelism eats up your cores. This is great for batch processing, but a nightmare for asynchronous servers (such as HTTP). There are good reasons why we’ve used the single-thread servlet model in the past decades. So parallelism only helps when scaling up.
- Parallelism has no effect on your algorithm’s Big O Notation. If your algorithm is
O(n log n), and you let that algorithm run onccores, you will still have anO(n log n / c)algorithm, ascis an insignificant constant in your algorithm’s complexity. You will save wall-clock time, but not reduce complexity!
The best way to improve performance, of course, is by reducing algorithm complexity. The killer is achieve O(1) or quasi-O(1), of course, for instance a HashMap lookup. But that is not always possible, let alone easy.
If you cannot reduce your complexity, you can still gain a lot of performance if you tweak your algorithm where it really matters, if you can find the right spots. Assume the following visual representation of an algorithm:
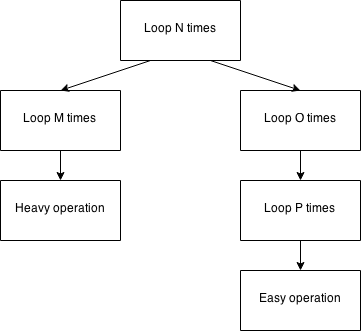
The overall complexity of the algorithm is O(N3), or O(N x O x P) if we want to deal with individual orders of magnitude. However, when profiling this code, you might find a funny scenario:
- On your development box, the left branch (
N -> M -> Heavy operation) is the only branch that you can see in your profiler, because the values forOandPare small in your development sample data. - On production, however, the right branch (
N -> O -> P -> Easy operationor also N.O.P.E.) is really causing trouble. Your operations team might have figured this out using AppDynamics, or DynaTrace, or some similar software.
Without production data, you might quickly jump to conclusions and optimise the “heavy operation”. You ship to production and your fix has no effect.
There are no golden rules to optimisation apart from the facts that:
- A well-designed application is much easier to optimise
- Premature optimisation will not solve any performance problems, but make your application less well-designed, which in turn makes it harder to be optimised
Enough theory. Let’s assume that you have found the right branch to be the issue. It may well be that a very easy operation is blowing up in production, because it is called lots and lots of times (if N, O, and P are large). Please read this article in the context of there being a problem at the leaf node of an inevitable O(N3) algorithm. These optimisations won’t help you scale. They’ll help you save your customer’s day for now, deferring the difficult improvement of the overall algorithm until later!
Here are the top 10 easy performance optimisations in Java:
1. Use StringBuilder
This should be your default in almost all Java code. Try to avoid the + operator. Sure, you may argue that it is just syntax sugar for a StringBuilder anyway, as in:
String x = "a" + args.length + "b";
… which compiles to
0 new java.lang.StringBuilder [16] 3 dup 4 ldc <String "a"> [18] 6 invokespecial java.lang.StringBuilder(java.lang.String) [20] 9 aload_0 [args] 10 arraylength 11 invokevirtual java.lang.StringBuilder.append(int) : java.lang.StringBuilder [23] 14 ldc <String "b"> [27] 16 invokevirtual java.lang.StringBuilder.append(java.lang.String) : java.lang.StringBuilder [29] 19 invokevirtual java.lang.StringBuilder.toString() : java.lang.String [32] 22 astore_1 [x]
But what happens, if later on, you need to amend your String with optional parts?
String x = "a" + args.length + "b";
if (args.length == 1)
x = x + args[0];You will now have a second StringBuilder, that just needlessly consumes memory off your heap, putting pressure on your GC. Write this instead:
StringBuilder x = new StringBuilder("a");
x.append(args.length);
x.append("b");
if (args.length == 1);
x.append(args[0]);Takeaway
In the above example, it is probably completely irrelevant if you’re using explicit StringBuilder instances, or if you rely on the Java compiler creating implicit instances for you. But remember, we’re in the N.O.P.E. branch. Every CPU cycle that we’re wasting on something as stupid as GC or allocating a StringBuilder‘s default capacity, we’re wasting N x O x P times.
As a rule of thumb, always use a StringBuilder rather than the + operator. And if you can, keep the StringBuilder reference across several methods, if your String is more complex to build. This is what jOOQ does when you generate a complex SQL statement. There is only one StringBuilder that “traverses” your whole SQL AST (Abstract Syntax Tree)
And for crying out loud, if you still have StringBuffer references, do replace them by StringBuilder. You really hardly ever need to synchronize on a string being created.
2. Avoid regular expressions
Regular expressions are relatively cheap and convenient. But if you’re in the N.O.P.E. branch, they’re about the worst thing you can do. If you absolutely must use regular expressions in computation-intensive code sections, at least cache the Pattern reference instead of compiling it afresh all the time:
static final Pattern HEAVY_REGEX =
Pattern.compile("(((X)*Y)*Z)*");But if your regular expression is really silly like
String[] parts = ipAddress.split("\\.");… then you really better resort to ordinary char[] or index-based manipulation. For example this utterly unreadable loop does the same thing:
int length = ipAddress.length();
int offset = 0;
int part = 0;
for (int i = 0; i < length; i++) {
if (i == length - 1 ||
ipAddress.charAt(i + 1) == '.') {
parts[part] =
ipAddress.substring(offset, i + 1);
part++;
offset = i + 2;
}
}… which also shows why you shouldn’t do any premature optimisation. Compared to the split() version, this is unmaintainable.
Challenge: The clever ones among your readers might find even faster algorithms.
Takeaway
Regular expressions are useful, but they come at a price. If you’re deep down in a N.O.P.E. branch, you must avoid regular expressions at all costs. Beware of a variety of JDK String methods, that use regular expressions, such as String.replaceAll(), or String.split().
Use a popular library like Apache Commons Lang instead, for your String manipulation.
3. Do not use iterator()
Now, this advice is really not for general use-cases, but only applicable deep down in a N.O.P.E. branch. Nonetheless, you should think about it. Writing Java-5 style foreach loops is convenient. You can just completely forget about looping internals, and write:
for (String value : strings) {
// Do something useful here
}However, every time you run into this loop, if strings is an Iterable, you will create a new Iterator instance. If you’re using an ArrayList, this is going to be allocating an object with 3 ints on your heap:
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
int expectedModCount = modCount;
// ...Instead, you can write the following, equivalent loop and “waste” only a single int value on the stack, which is dirt cheap:
int size = strings.size();
for (int i = 0; i < size; i++) {
String value : strings.get(i);
// Do something useful here
}… or, if your list doesn’t really change, you might even operate on an array version of it:
for (String value : stringArray) {
// Do something useful here
}Takeaway
Iterators, Iterable, and the foreach loop are extremely useful from a writeability and readability perspective, as well as from an API design perspective. However, they create a small new instance on the heap for each single iteration. If you run this iteration many many times, you want to make sure to avoid creating this useless instance, and write index-based iterations instead.
Discussion
Some interesting disagreement about parts of the above (in particular replacing Iterator usage by access-by-index) has been discussed on Reddit here.
4. Don’t call that method
Some methods are simple expensive. In our N.O.P.E. branch example, we don’t have such a method at the leaf, but you may well have one. Let’s assume your JDBC driver needs to go through incredible trouble to calculate the value of ResultSet.wasNull(). Your homegrown SQL framework code might look like this:
if (type == Integer.class) {
result = (T) wasNull(rs,
Integer.valueOf(rs.getInt(index)));
}
// And then...
static final <T> T wasNull(ResultSet rs, T value)
throws SQLException {
return rs.wasNull() ? null : value;
}This logic will now call ResultSet.wasNull() every time you get an int from the result set. But the getInt() contract reads:
Returns: the column value; if the value is SQL NULL, the value returned is 0
Thus, a simple, yet possibly drastic improvement to the above would be:
static final <T extends Number> T wasNull(
ResultSet rs, T value
)
throws SQLException {
return (value == null ||
(value.intValue() == 0 && rs.wasNull()))
? null : value;
}So, this is a no-brainer:
Takeaway
Don’t call expensive methods in an algorithms “leaf nodes”, but cache the call instead, or avoid it if the method contract allows it.
5. Use primitives and the stack
The above example is from jOOQ, which uses a lot of generics, and thus is forced to use wrapper types for byte, short, int, and long – at least before generics will be specialisable in Java 10 and project Valhalla. But you may not have this constraint in your code, so you should take all measures to replace:
// Goes to the heap Integer i = 817598;
… by this:
// Stays on the stack int i = 817598;
Things get worse when you’re using arrays:
// Three heap objects!
Integer[] i = { 1337, 424242 };… by this:
// One heap object.
int[] i = { 1337, 424242 };Takeaway
When you’re deep down in your N.O.P.E. branch, you should be extremely wary of using wrapper types. Chances are that you will create a lot of pressure on your GC, which has to kick in all the time to clean up your mess.
A particularly useful optimisation might be to use some primitive type and create large, one-dimensional arrays of it, and a couple of delimiter variables to indicate where exactly your encoded object is located on the array.
An excellent library for primitive collections, which are a bit more sophisticated than your average int[] is trove4j, which ships with LGPL.
Exception
There is an exception to this rule: boolean and byte have few enough values to be cached entirely by the JDK. You can write:
Boolean a1 = true; // ... syntax sugar for: Boolean a2 = Boolean.valueOf(true); Byte b1 = (byte) 123; // ... syntax sugar for: Byte b2 = Byte.valueOf((byte) 123);
The same is true for low values of the other integer primitive types, including char, short, int, long.
But only if you’re auto-boxing them, or calling TheType.valueOf(), not when you call the constructor!
Never call the constructor on wrapper types, unless you really want a new instance
This fact can also help you write a sophisticated, trolling April Fool’s joke for your co-workers
Off heap
Of course, you might also want to experiment with off-heap libraries, although they’re more of a strategic decision, not a local optimisation.
An interesting article on that subject by Peter Lawrey and Ben Cotton is: OpenJDK and HashMap… Safely Teaching an Old Dog New (Off-Heap!) Tricks
6. Avoid recursion
Modern functional programming languages like Scala encourage the use of recursion, as they offer means of optimising tail-recursing algorithms back into iterative ones. If your language supports such optimisations, you might be fine. But even then, the slightest change of algorithm might produce a branch that prevents your recursion from being tail-recursive. Hopefully the compiler will detect this! Otherwise, you might be wasting a lot of stack frames for something that might have been implemented using only a few local variables.
Takeaway
There’s not much to say about this apart from: Always prefer iteration over recursion when you’re deep down the N.O.P.E. branch
7. Use entrySet()
When you want to iterate through a Map, and you need both keys and values, you must have a very good reason to write the following:
for (K key : map.keySet()) {
V value : map.get(key);
}… rather than the following:
for (Entry<K, V> entry : map.entrySet()) {
K key = entry.getKey();
V value = entry.getValue();
}When you’re in the N.O.P.E. branch, you should be wary of maps anyway, because lots and lots of O(1) map access operations are still lots of operations. And the access isn’t free either. But at least, if you cannot do without maps, use entrySet() to iterate them! The Map.Entry instance is there anyway, you only need to access it.
Takeaway
Always use entrySet() when you need both keys and values during map iteration.
8. Use EnumSet or EnumMap
There are some cases where the number of possible keys in a map is known in advance – for instance when using a configuration map. If that number is relatively small, you should really consider using EnumSet or EnumMap, instead of regular HashSet or HashMap instead. This is easily explained by looking at EnumMap.put():
private transient Object[] vals;
public V put(K key, V value) {
// ...
int index = key.ordinal();
vals[index] = maskNull(value);
// ...
}The essence of this implementation is the fact that we have an array of indexed values rather than a hash table. When inserting a new value, all we have to do to look up the map entry is ask the enum for its constant ordinal, which is generated by the Java compiler on each enum type. If this is a global configuration map (i.e. only one instance), the increased access speed will help EnumMap heavily outperform HashMap, which may use a bit less heap memory, but which will have to run hashCode() and equals() on each key.
Takeaway
Enum and EnumMap are very close friends. Whenever you use enum-like structures as keys, consider actually making those structures enums and using them as keys in EnumMap.
9. Optimise your hashCode() and equals() methods
If you cannot use an EnumMap, at least optimise your hashCode() and equals() methods. A good hashCode() method is essential because it will prevent further calls to the much more expensive equals() as it will produce more distinct hash buckets per set of instances.
In every class hierarchy, you may have popular and simple objects. Let’s have a look at jOOQ’s org.jooq.Table implementations.
The simplest and fastest possible implementation of hashCode() is this one:
// AbstractTable, a common Table base implementation:
@Override
public int hashCode() {
// [#1938] This is a much more efficient hashCode()
// implementation compared to that of standard
// QueryParts
return name.hashCode();
}… where name is simply the table name. We don’t even consider the schema or any other property of the table, as the table names are usually distinct enough across a database. Also, the name is a string, so it has already a cached hashCode() value inside.
The comment is important, because AbstractTable extends AbstractQueryPart, which is a common base implementation for any AST (Abstract Syntax Tree) element. The common AST element does not have any properties, so it cannot make any assumptions an optimised hashCode() implementation. Thus, the overridden method looks like this:
// AbstractQueryPart, a common AST element
// base implementation:
@Override
public int hashCode() {
// This is a working default implementation.
// It should be overridden by concrete subclasses,
// to improve performance
return create().renderInlined(this).hashCode();
}In other words, the whole SQL rendering workflow has to be triggered to calculate the hash code of a common AST element.
Things get more interesting with equals()
// AbstractTable, a common Table base implementation:
@Override
public boolean equals(Object that) {
if (this == that) {
return true;
}
// [#2144] Non-equality can be decided early,
// without executing the rather expensive
// implementation of AbstractQueryPart.equals()
if (that instanceof AbstractTable) {
if (StringUtils.equals(name,
(((AbstractTable<?>) that).name))) {
return super.equals(that);
}
return false;
}
return false;
}First thing: Always (not only in a N.O.P.E. branch) abort every equals() method early, if:
this == argumentthis "incompatible type" argument
Note that the latter condition includes argument == null, if you’re using instanceof to check for compatible types. We’ve blogged about this before in 10 Subtle Best Practices when Coding Java.
Now, after aborting comparison early in obvious cases, you might also want to abort comparison early when you can make partial decisions. For instance, the contract of jOOQ’s Table.equals() is that for two tables to be considered equal, they must be of the same name, regardless of the concrete implementation type. For instance, there is no way these two items can be equal:
com.example.generated.Tables.MY_TABLEDSL.tableByName("MY_OTHER_TABLE")
If the argument cannot be equal to this, and if we can check that easily, let’s do so and abort if the check fails. If the check succeeds, we can still proceed with the more expensive implementation from super. Given that most objects in the universe are not equal, we’re going to save a lot of CPU time by shortcutting this method.
some objects are more equal than others
In the case of jOOQ, most instances are really tables as generated by the jOOQ source code generator, whose equals() implementation is even further optimised. The dozens of other table types (derived tables, table-valued functions, array tables, joined tables, pivot tables, common table expressions, etc.) can keep their “simple” implementation.
10. Think in sets, not in individual elements
Last but not least, there is a thing that is not Java-related but applies to any language. Besides, we’re leaving the N.O.P.E. branch as this advice might just help you move from O(N3) to O(n log n), or something like that.
Unfortunately, many programmers think in terms of simple, local algorithms. They’re solving a problem step by step, branch by branch, loop by loop, method by method. That’s the imperative and/or functional programming style. While it is increasingly easy to model the “bigger picture” when going from pure imperative to object oriented (still imperative) to functional programming, all these styles lack something that only SQL and R and similar languages have:
Declarative programming.
In SQL (and we love it, as this is the jOOQ blog) you can declare the outcome you want to get from your database, without making any algorithmic implications whatsoever. The database can then take all the meta data available into consideration (e.g. constraints, keys, indexes, etc.) to figure out the best possible algorithm.
In theory, this has been the main idea behind SQL and relational calculus from the beginning. In practice, SQL vendors have implemented highly efficient CBOs (Cost-Based Optimisers) only since the last decade, so stay with us in the 2010’s when SQL will finally unleash its full potential (it was about time!)
But you don’t have to do SQL to think in sets. Sets / collections / bags / lists are available in all languages and libraries. The main advantage of using sets is the fact that your algorithms will become much much more concise. It is so much easier to write:
SomeSet INTERSECT SomeOtherSet
rather than:
// Pre-Java 8
Set result = new HashSet();
for (Object candidate : someSet)
if (someOtherSet.contains(candidate))
result.add(candidate);
// Even Java 8 doesn't really help
someSet.stream()
.filter(someOtherSet::contains)
.collect(Collectors.toSet());Some may argue that functional programming and Java 8 will help you write easier, more concise algorithms. That’s not necessarily true. You can translate your imperative Java-7-loop into a functional Java-8 Stream collection, but you’re still writing the very same algorithm. Writing a SQL-esque expression is different. This…
SomeSet INTERSECT SomeOtherSet
… can be implemented in 1000 ways by the implementation engine. As we’ve learned today, perhaps it is wise to transform the two sets into EnumSet automatically, before running the INTERSECT operation. Perhaps we can parallelise this INTERSECT without making low-level calls to Stream.parallel()
Conclusion
In this article, we’ve talked about optimisations done on the N.O.P.E. branch, i.e. deep down in a high-complexity algorithm. In our case, being the jOOQ developers, we have interest in optimising our SQL generation:
- Every query is generated only on a single
StringBuilder - Our templating engine actually parses characters, instead of using regular expressions
- We use arrays wherever we can, especially when iterating over listeners
- We stay clear of JDBC methods that we don’t have to call
- etc…
jOOQ is at the “bottom of the food chain”, because it’s the (second-)last API that is being called by our customers’ applications before the call leaves the JVM to enter the DBMS. Being at the bottom of the food chain means that every line of code that is executed in jOOQ might be called N x O x P times, so we must optimise eagerly.
Your business logic is not deep down in the N.O.P.E. branch. But your own, home-grown infrastructure logic may be (custom SQL frameworks, custom libraries, etc.) Those should be reviewed according to the rules that we’ve seen today. For instance, using Java Mission Control or any other profiler.
| Reference: | Top 10 Easy Performance Optimisations in Java from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |

Nice post! What do you think about using static methods? Is it true that they stay always in heap and they’re never collected by GC?
Greetings
What do you mean by “methods staying in heap”? Methods aren’t independent objects – they belong to a class