The database plugin in IntelliJ IDEA is a useful tool to work with data in databases. As long as we got a JDBC driver to connect to the database we can configure a data source. And then we can run queries, inspect the contents of tables and change data with the database tool window. It is not uncommon to have multiple data sources, for example development and test environment databases, which will have the same tables. When we open the tables or run queries we don’t have a visual feedback to see to which data source such a table belongs. To have a visual feedback we can colorize our data source. This means we assign a color to a data source and when we open a table from that data source the tab color in the editor window will have a different color than other tabs or the background color of the data source objects have a color.
To add a color to a data source we must open the database tool window and right click on a data source. We select the option Color Settings… from the popup window:
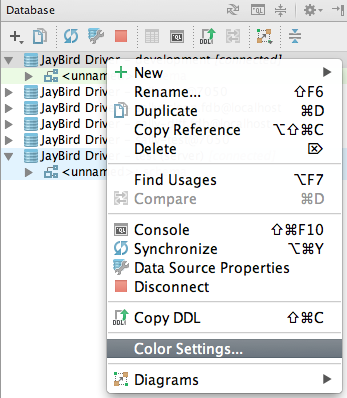
Next a new dialog opens where we can select a color:
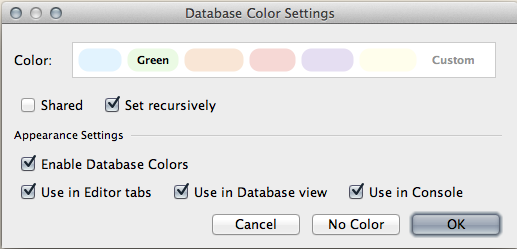
We can make a selection for one of the predefined colors or create a custom color we want to use. Also we can select in the Appearance Settings where in IntelliJ IDEA the colored data source must appear. We click on the OK button to save our settings. We can repeat these steps for other data sources and given them different colors.
Once we have added color to our data source we can see for example in the tabs of our editor window the different colors:
![]()
Or when we open the data sources in the database tool window to get a list of all objects in the data source:
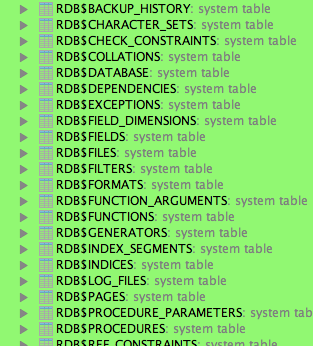
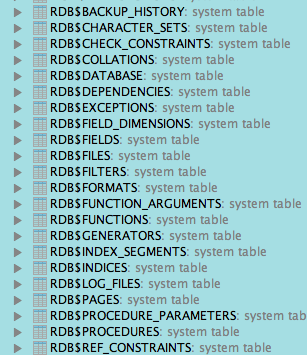
Even we open a dialog to see recently changed files we can see the colorized data source objects:
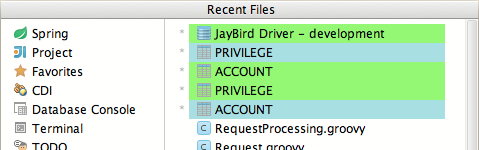
Sample with IntelliJ IDEA 13.1.1
| Reference: | Coloring Different Data Sources in IntelliJ IDEA from our JCG partner Hubert Ikkink at the JDriven blog. |
