I found this little problem the other day: there’s this server that runs for a while and then falls over. It’s then restarted by its startup script and the whole process repeats itself. This doesn’t sound that bad as it isn’t business critical although there is a significant loss of data, so I decided to take a closer look and to find out exactly what’s going wrong. The first thing to note is that the server passes all it’s unit tests and a whole bunch of integration tests. It runs well in all test environments using test data, so what’s going wrong in production? It’s easy to guess that in production it’s probably under a heavier load than test, or than had been allowed for in its design, and therefore it’s running out of resources, but what resources and where? That’s the tricky question.
In order to demonstrate how to investigate this problem, the first thing to do is to write some leaky sample code and I’m going to use the Producer Consumer pattern to do this because I can demonstrate the big problem with it.
To demonstrate leaky code 1 I need, as usual, I need a highly contrived scenario and in this scenario imagine that you work for a stockbroker on a system that records their sales of stocks and shares in a database. Orders are taken and placed in queue by a simple thread. Another thread then picks up the order from the queue and writes it to the database. The
Order POJO is very straight forward and looks like this:
public class Order {
private final int id;
private final String code;
private final int amount;
private final double price;
private final long time;
private final long[] padding;
/**
* @param id
* The order id
* @param code
* The stock code
* @param amount
* the number of shares
* @param price
* the price of the share
* @param time
* the transaction time
*/
public Order(int id, String code, int amount, double price, long time) {
super();
this.id = id;
this.code = code;
this.amount = amount;
this.price = price;
this.time = time;
// This just makes the Order object bigger so that
// the example runs out of heap more quickly.
this.padding = new long[3000];
Arrays.fill(padding, 0, padding.length - 1, -2);
}
public int getId() {
return id;
}
public String getCode() {
return code;
}
public int getAmount() {
return amount;
}
public double getPrice() {
return price;
}
public long getTime() {
return time;
}
}The Order POJO is part of a simple Spring application, which has three key abstractions that create a new thread when Spring calls their start() methods.
The first of these is OrderFeed. It’s run() method creates a new dummy order and places it on the queue. It then sleeps for a moment before creating the next order.
public class OrderFeed implements Runnable {
private static Random rand = new Random();
private static int id = 0;
private final BlockingQueue<Order> orderQueue;
public OrderFeed(BlockingQueue<Order> orderQueue) {
this.orderQueue = orderQueue;
}
/**
* Called by Spring after loading the context. Start producing orders
*/
public void start() {
Thread thread = new Thread(this, "Order producer");
thread.start();
}
/** The main run loop */
@Override
public void run() {
while (true) {
Order order = createOrder();
orderQueue.add(order);
sleep();
}
}
private Order createOrder() {
final String[] stocks = { "BLND.L", "DGE.L", "MKS.L", "PSON.L", "RIO.L", "PRU.L",
"LSE.L", "WMH.L" };
int next = rand.nextInt(stocks.length);
long now = System.currentTimeMillis();
Order order = new Order(++id, stocks[next], next * 100, next * 10, now);
return order;
}
private void sleep() {
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}The second class is OrderRecord, which is responsible for taking orders from the queue and writing them to the database. The problem is that it takes significantly longer to write the orders to the database then it does to produce them. This is demonstrated by the long, 1 second, sleep in my recordOrder(…) method.
public class OrderRecord implements Runnable {
private final BlockingQueue<Order> orderQueue;
public OrderRecord(BlockingQueue<Order> orderQueue) {
this.orderQueue = orderQueue;
}
public void start() {
Thread thread = new Thread(this, "Order Recorder");
thread.start();
}
@Override
public void run() {
while (true) {
try {
Order order = orderQueue.take();
recordOrder(order);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* Record the order in the database
*
* This is a dummy method
*
* @param order
* The order
* @throws InterruptedException
*/
public void recordOrder(Order order) throws InterruptedException {
TimeUnit.SECONDS.sleep(1);
}
}The result is obvious: the OrderRecord thread just can’t keep up and the queue will get longer and longer until the JVM runs out of heap space and falls over. That’s the big problem with the Producer Consumer pattern: the consumer has to be able to keep up with the producer.
Just to prove his point I’ve added a third class OrderMonitor, which prints the queue size every couple of seconds so that you can see things going wrong.
public class OrderQueueMonitor implements Runnable {
private final BlockingQueue<Order> orderQueue;
public OrderQueueMonitor(BlockingQueue<Order> orderQueue) {
this.orderQueue = orderQueue;
}
public void start() {
Thread thread = new Thread(this, "Order Queue Monitor");
thread.start();
}
@Override
public void run() {
while (true) {
try {
TimeUnit.SECONDS.sleep(2);
int size = orderQueue.size();
System.out.println("Queue size is:" + size);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}Just to complete the line-up I’ve included the Spring context below:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd"
default-init-method="start"
default-destroy-method="destroy">
<bean id="theQueue" class="java.util.concurrent.LinkedBlockingQueue"/>
<bean id="orderProducer" class="com.captaindebug.producerconsumer.problem.OrderRecord">
<constructor-arg ref="theQueue"/>
</bean>
<bean id="OrderRecorder" class="com.captaindebug.producerconsumer.problem.OrderFeed">
<constructor-arg ref="theQueue"/>
</bean>
<bean id="QueueMonitor" class="com.captaindebug.producerconsumer.problem.OrderQueueMonitor">
<constructor-arg ref="theQueue"/>
</bean>
</beans>The next thing to do is to start up the leaky sample code. You can do this by changing to the following directory
/<your-path>/git/captaindebug/producer-consumer/target/classes
…and then by typing the following command:
java -cp /path-to/spring-beans-3.2.3.RELEASE.jar:/path-to/spring-context-3.2.3.RELEASE.jar:/path-to/spring-core-3.2.3.RELEASE.jar:/path-to/slf4j-api-1.6.1-javadoc.jar:/path-to/commons-logging-1.1.1.jar:/path-to/spring-expression-3.2.3.RELEASE.jar:. com.captaindebug.producerconsumer.problem.Main
…where ” path-to” is the path to your jar files
The one thing that I really hate about Java is that fact that it’s SO difficult to run any program from the command line. You have to figure out what the classpath is, what options and properties need setting and what the main class is. Surely, it must be possible to think of a way of simply typing Java programName and the JVM figures out where everything is, especially if we start using convention over configuration: how hard can it be?
You can also monitor the leaky app by attaching a simple jconsole. If you’re running it remotely, then you’ll need to add the following options to the command line above (picking your own port number):
-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9010 -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false
…and if you take a look at the amount of heap used you’ll see it gradually increasing as the queue gets bigger.
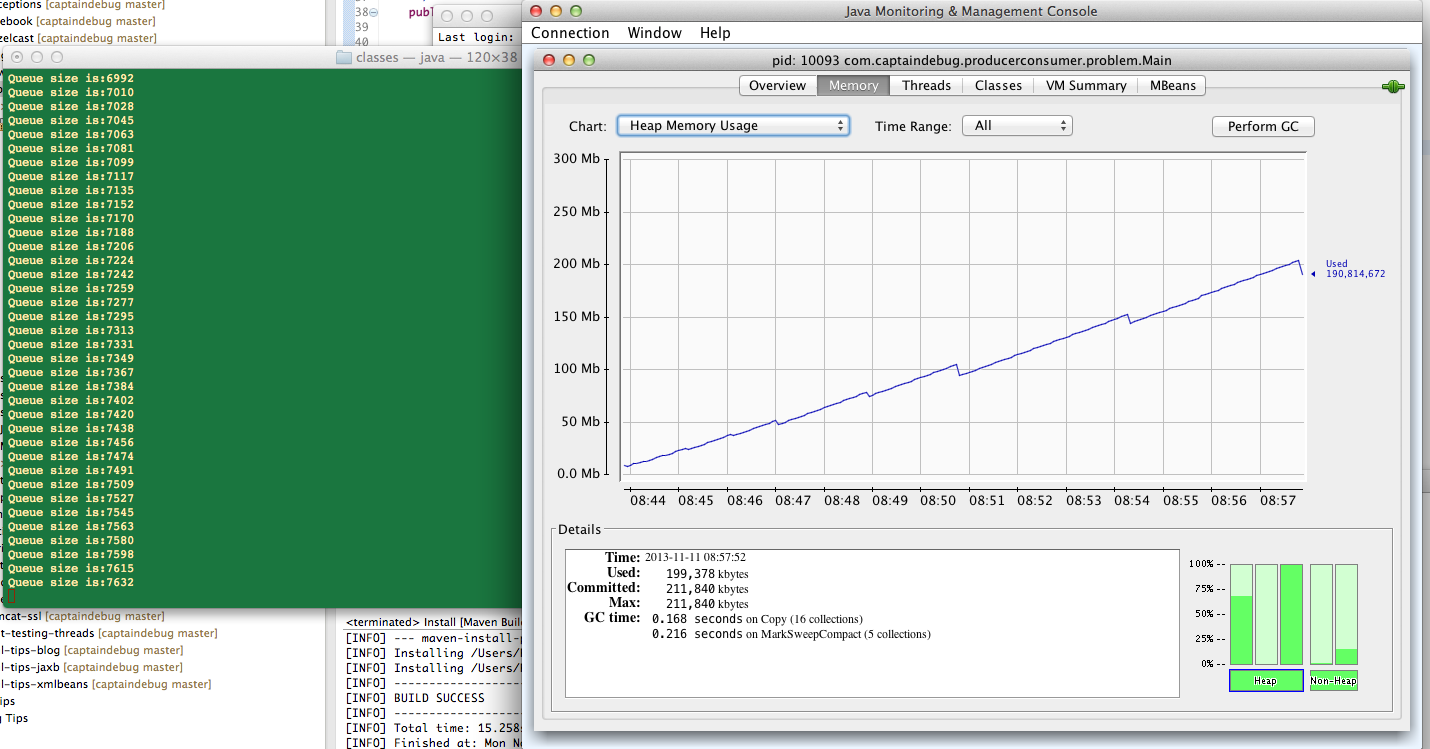
If a kilobyte of memory leaks away, then you’ll probably never spot it; if a giga byte of memory leaks the problem will be obvious. So, all that’s left to do for the moment is to sit back as wait for some memory to leak away before moving on to the next stage of the investigation. More on that next time…
1The source code can be found in my Producer Consumer project on GitHub.

Runing Java programs from the command line is easy, that’s what JAR files were made for, and if your O/S is properly configured you can just executed the jar like any other executable program, you don’t even have to run it as “java -jar program.jar”, you can just type “program.jar” (or run it by icon from the desktop). The manifest inside the jar stores the classpath and references to other jars and resources (you could also re-package everything into the same jar to eliminate the possibility of broken dependencies). You might find Boxer (http://ringlord.com/boxer.html) to be useful for packaging projects,… Read more »
According to my understanding of memory leaks your example does not qualify – if you implement faster consumer(s) than your memory consumption will not increase.
Also in my opinion this example cannot be called “memory leak”? Just look at the “memory leak” definition – it clearly says that “(…)memory which is no longer needed is not released(…)” and “(…)a memory leak may happen when an object is stored in memory but cannot be accessed by the running code(…)”.
Your example does not qualify to be memory leak – this is the fast producer problem and I believe that creating several consumers (or “recorders”) could solve the problem.