Practically all server applications require some sort of synchronization between multiple threads. Most of the synchronization work is done for us at the framework level, such as by our web server, DB client or messaging framework. Java and Scala provide a multitude of components to write solid multi-threaded applications. These include object pools, concurrent collections, advanced locks, execution contexts etc..
To better understand these, let’s explore the most synchronization idiom – the Object lock. This mechanism powers the synchronized keyword, making it one of, if not the most popular multi-threading idiom in Java. It is also at the base of many of the more complex patterns we use such as thread and connection pools, concurrent collections and more.
The synchronized keyword is used in two primary contexts:
- as a method modifier to mark a method that it can only be executed by one thread at a time.
- by declaring a code block as a critical section – one that’s only available to a single thread at any given point in time.
Locking Instructions
Fact #1. Synchronized code blocks are implemented using two dedicated bytecode instructions, which are part of the official specification – MonitorEnter and MonitorExit. This differs from other locking mechanisms, such as those found in the java.util.concurrent package, which are implemented (in the case of HotSpot) using a combination of Java code and native calls made through sun.misc.Unsafe.
These instructions operate on an object specified explicitly by the developer in the context of the synchronized block. For synchronized methods the lock is automatically selected to be the “this” variable. For static methods the lock will be placed on the Class object.
Synchronized methods can sometimes cause bad behavior. One example is creating implicit dependencies between different synchronized methods of the same object, as they share the same lock. A worse scenario is declaring synchronized methods in a base class (which might even be a 3rd party class) and then adding new synchronized methods to a derived class. This creates implicit synchronization dependencies across the hierarchy and has the potential of creating throughput issues or even deadlocks. To avoid these, it’s recommended to use a privately held object as a lock to prevent accidental sharing or escapement of locks.
The Compiler and Synchronization
There are two bytecode instructions responsible for synchronization. This is unusual, as most bytecode instructions are independent of each other, usually “communicating” with one another by placing values on the thread’s operand stack. The object to lock is also loaded from the operand stack, previously placed there by either dereferencing a variable, field or invoking a method returning an object.
Fact #2. So what happens if one of the two instructions is called without a respective call to the other? The Java compiler will not produce code that calls MonitorExit without calling MonitorEnter. Even so, from the JVM’s perspective such code is totally valid. The result of such a case would be that the MonitorExit instruction with throw an IllegalMonitorStateException.
A more dangerous case is what would happen if a lock is acquired via MonitorEnter, but isn’t released via a corresponding call to a MonitorExit. In this case the thread owning the lock can cause other threads who are trying to obtain the lock to block indefinitely. It’s worth noting that since the lock is reentrant, the thread owning the lock may continue to happily execute even if it were to reach and reenter the same lock again.
And here’s the catch. To prevent this from happening, the Java compiler generates matching enter and exit instructions in such a way that once execution has entered into a synchronized block or method, it must pass through a matching MonitorExit instruction for the same object. One thing that can throw a wrench into this, is if an exception is thrown within the critical section.
public void hello() {
synchronized (this) {
System.out.println("Hi!, I'm alone here");
}
}Let’s analyze the bytecode –
aload_0 //load this into the operand stack dup //load it again astore_1 //backup this into an implicit variable stored at register 1 monitorenter //pop the value of this from the stack to enter the monitor //the actual critical section getstatic java/lang/System/out Ljava/io/PrintStream; ldc "Hi!, I'm alone here" invokevirtual java/io/PrintStream/println(Ljava/lang/String;)V aload_1 //load the backup of this monitorexit //pop up the var and exit the monitor goto 14 // completed - jump to the end // the added catch clause - we got here if an exception was thrown - aload_1 // load the backup var. monitorexit //exit the monitor athrow // rethrow the exception object, loaded into the operand stack return
The mechanism used by the compiler to prevent the stack from unwinding without going through the MonitorExit instruction is pretty straightforward – the compiler adds an implicit try…catch clause to release the lock and rethrow the exception.
Fact #3. Another question is where is the reference to the locked object stored between the corresponding enter and exit calls. Keep in mind that multiple threads could be executing the same synchronized block concurrently, using different lock objects. If the locked object is the result of a method being invoked, it’s highly unlikely the JVM will execute it again, as it may change the object’s state, or may not even return the same object. The same can be true for a variable or field which might have changed since the monitor was entered.
The monitor variable. To counter this, the compiler adds an implicit local variable to the method to hold the value of the locked object. This is a smart solution, as it imposes fairly minimal overhead on maintaining a reference to the locked object, as opposed to using a concurrent heap structure to map locked objects to threads (a structure which in itself might need synchronization). I first observed this new variable when building Takipi‘s stack analysis algorithm and saw there were unexpected variables popping up in the code.
Notice that all this work is done at the Java compiler level. The JVM is perfectly happy to enter a critical section through a MonitorEnter instruction without exiting it (or vice versa), or use different objects for what should be corresponding enter and exit methods.
Locking at the JVM Level
Let’s take a deeper look now into how locks are actually implemented at the JVM level. For this we’ll be examining the HotSpot SE 7 implementation, as this is VM specific. Since locking can have some pretty adverse implications on code throughput, the JVM has put in place some very strong optimizations to make acquiring and releasing locks as efficient as possible.
Fact #4. One of the strongest mechanisms put in place by the JVM is thread lock biasing. Locking is an intrinsic capability each Java objects has, much like having a system hashcode or a reference to its defining class. This is true regardless of the object’s type (you can even use a primitive array as a lock if you’d like).
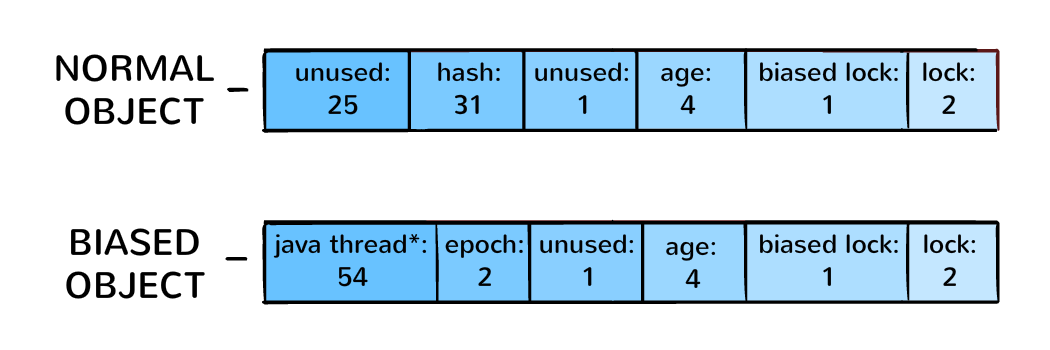
These types of data are stored in each object’s header (also known as the object’s mark). Some of this data that is placed in the object’s header is reserved for describing the object’s locking state. This includes bit flags describing the object’s locking state (i.e. locked / unlocked) and a reference to the thread which currently owns the lock – the thread towards the object is biased.
In order to conserve space within the object header, Java thread objects are allocated in a lower segment of the VM’s heap in order to reduce the address size and save up on bits within each object’s header (54 or 23 bits for 64 and 32 bit JVMs respectively).
For 64 bit –
The Locking Algorithm
When the JVM attempts to acquire a lock on an object it goes through a series of steps ranging from optimistic to the pessimistic.
Fact #5. A lock is acquired by a thread if it succeeds in establishing itself as the object lock’s owner. This is determined by whether the thread is able to install a reference to itself (a pointer to the internal JavaThread object) in the object’s header.
Acquiring the lock. A first attempt to do this is done using a simple compare-and-exchange (CAS) operation. This is very efficient as it can usually translate into a direct CPU instruction (e.g cmpxchg). CAS operations along with an OS specific thread parking routines serve as the building blocks for the object synchronization idiom.
If the lock is either free or has been previously biased toward this thread the lock on the object is obtained for the thread and execution can continue immediately. If the CAS fails the JVM will perform one round of spin locking where the thread parks to effectively put it to sleep between retrying the CAS. If these initial attempts fail (signaling a fairly higher level of contention for the lock) the thread will move itself to a blocked state and enqueue itself in the list of threads vying for the lock and begin a series of spin locks.
After each round of spinning the thread will check for changes in the global state of the JVM, such as the onset of a “stop the world” GC, in which case the thread will need to suspend itself until GC is complete to prevent a case where the lock is obtained and execution continues while a STW GC is being executed.
Releasing the lock. When exiting the critical section through a MonitorExit instruction, the owner thread will try to see if it can wake any of the parked threads which may be waiting for the lock to be released. This process is known as choosing an “heir”. This is meant to increase liveliness, and to prevent a scenario where threads remain parked while the lock has already been released (also known as stranding).
Debugging server multi-threading problems is hard, as they tend to depend on very specific timing and OS heuristics. It was one of the reasons that got us working on Takipi in the first place.

Do you know there is a slight difference between what happens when an instance method is synchronized and when a static method is synchronized.
Read more here – http://netjs.blogspot.com/2015/06/synchronization-in-java-multithreading-synchronizing-thread.html