The Split-Brain Problem in Plain English — And the Three Ways Your Distributed Cache Handles It Wrong
Redis Sentinel, Hazelcast, and Infinispan all have split-brain documentation. None of them tell you what your Java code silently observes when it happens. Let’s fix that.
A split-brain is one of those distributed systems concepts that every engineer nods at but very few have actually traced all the way down to application code. In short: a network partition divides your cache cluster into two (or more) islands that can no longer communicate with each other. Both islands continue operating independently, both accepting reads and writes, and — depending on your tool’s configuration — neither island may have any idea that the other still exists. When the network heals and the cluster reunites, the two islands often carry conflicting versions of the same keys. Something has to win and something has to lose.
The official documentation for Redis Sentinel, Hazelcast, and Infinispan all describe this scenario in terms of cluster topology and merge policies. What they describe much less precisely is what your Java application is actually observing while the split is active — and what silently happens to data your code believed it had written successfully. That gap is where production incidents live. This article fills it.
Throughout, we’ll look at each tool from the perspective of a Java application developer reading from and writing to the cache. Not from the perspective of an operations engineer watching Sentinel logs or Hazelcast member counts.
What a split-brain actually means for your application code
Start with a concrete mental model. You have a cache cluster of three nodes — call them A, B, and C — all replicating the same data. A network fault severs the link between A and the pair {B, C}. Node A is now isolated; B and C can still see each other. You have two partitions: a minority partition of one and a majority partition of two.
Here is the critical point that documentation glosses over: your Java application’s cache clients are still connected to both partitions simultaneously. Some application instances — depending on their load balancer, connection pool, or sticky routing — are talking to A. Others are talking to B or C. Both groups believe they are using a healthy, authoritative cache.
As a result, two things happen in parallel that your application code has absolutely no visibility into:
- Divergent reads: different application instances reading the same key receive different values, because A’s copy and B/C’s copy are now evolving independently.
- Divergent writes: both partitions accept writes to the same key, potentially overwriting each other’s changes in ways that depend entirely on which partition “wins” during the subsequent merge — a decision made asynchronously, without your application’s knowledge.
The Google SRE Book’s treatment of distributed consensus describes this clearly: “each side incorrectly elects a master and accepts writes and deletions, leading to a split-brain scenario and data corruption.” The word “incorrectly” is doing a lot of work there. From each partition’s local perspective, everything looks correct. The incorrectness is only visible from the outside — and from the application’s perspective, there is no outside.
Every cache tool’s response to a split-brain is ultimately a choice between Consistency and Availability as described by the CAP theorem. CP tools refuse writes on the minority side to preserve a single source of truth. AP tools keep serving both sides to stay available, accepting that divergence will need reconciliation later. Most tools offer both modes via configuration — but critically, the default is often not what you’d choose if you understood the tradeoffs.
Mistake #1: Trusting that Sentinel always prevents a dual-master
Redis Sentinel is a monitoring and automatic failover system, not a consensus protocol. It requires a quorum of Sentinel instances to agree that the master is down before promoting a replica. With three Sentinels and a quorum of two, the majority partition can safely promote a new master. So far, so good.
The problem is the window between when the partition forms and when Sentinel completes the failover. During this window — which is governed by sentinel down-after-milliseconds and can run from seconds to minutes — the original master is still running in the minority partition and still accepting writes. Any Java application instance connected to it is writing to a node that is about to be demoted. When it is demoted, all writes made to it since the partition began are silently discarded. From the application’s perspective, those writes returned successfully. They are gone without a trace.
This is not a bug in Sentinel. Salvatore Sanfilippo, Redis’s creator, confirmed this explicitly: “Sentinel is not good to handle complex net splits with minimal data loss. Just this was never the goal.” Redis uses asynchronous replication — replicas lag behind the master — so some data loss during failover is an accepted design trade-off, not a defect.
What your Java code observes during a split with a default Sentinel setup:
// Thread A — connected to old master (minority partition)
cache.set("order:99", "CONFIRMED"); // returns OK — write accepted
// Thread B — connected to new master (majority partition, post-failover)
String status = cache.get("order:99"); // returns null or stale "PENDING"
// Thread A's write never arrived here
// After partition heals — old master demoted, becomes replica
// Old master syncs from new master via REPLICAOF — wipes its own divergent data
cache.get("order:99"); // now returns stale "PENDING" everywhere
// Thread A's "CONFIRMED" write is gone
Redis provides a partial mitigation via min-replicas-to-write (formerly min-slaves-to-write). When set, the master refuses write commands unless at least N replicas are connected with acceptable replication lag. An isolated master with no connected replicas will start returning errors on write — which is far preferable to silently accepting writes that will be lost. The corresponding configuration looks like this:
# redis.conf — tell the master to refuse writes if isolated min-replicas-to-write 1 min-replicas-max-lag 10
This does not eliminate the window of data loss — it closes it faster. Your Java code will start seeing write failures instead of silent successes. That is strictly better: a write failure is an observable signal; a silently lost write is not. From the application layer, you should be prepared to catch RedisException on write operations during failover windows and route them to a retry queue or dead-letter store rather than assuming success.
Mistake #2: Relying on the default merge policy to preserve your writes
Hazelcast is an in-process distributed cache — your Java code and the cache node run in the same JVM. When a network partition forms, each partition continues to function as an independent Hazelcast cluster. Both sides hold state. Both sides accept writes. The Hazelcast documentation describes this clearly: a background task periodically searches for split clusters; when it detects one, the smaller cluster merges into the larger, with merge policies resolving per-key conflicts.
The problem for application developers is twofold. First, this merge is asynchronous and happens well after the network heals — there is no notification to your code that a merge is in progress or that the value you just read may be about to be overwritten. Second, the Jepsen analysis of Hazelcast found that for all data structures other than IMap (such as ISet, IList, IQueue, and AtomicReference), writes to the losing partition are simply discarded during the merge — there is no merge policy applied at all. Those updates are gone.
For IMap, merge policies do apply, but the built-in policies all have gaps. The default PutIfAbsentMergePolicy only adds keys that don’t exist on the surviving side — if both partitions wrote conflicting values to the same key, the surviving side’s version wins unconditionally. LatestUpdateMergePolicy uses wall-clock timestamps, which means any clock skew between nodes can cause a logically earlier write to win. What your Java code observes during and after a Hazelcast split:
// Before split: cluster has members M1, M2, M3
IMap<String, Integer> inventory = hz.getMap("inventory");
inventory.put("SKU-42", 100);
// Network partition: {M1} isolated from {M2, M3}
// Code running on M1 (minority)
inventory.put("SKU-42", 95); // sold 5 units, returns normally
// Code running on M2/M3 (majority)
inventory.put("SKU-42", 88); // sold 12 units, returns normally
// Network heals — M1 merges into {M2, M3}
// With LatestUpdateMergePolicy: whichever write had the later wall-clock time wins
// If M1's clock was ahead: 95 survives — 12 units of sales are invisibly lost
int actual = inventory.get("SKU-42"); // 95 — but real inventory should be 83
The correct application-layer response here is to never use a distributed cache as the authoritative store for quantities that must be exact. Hazelcast’s FencedLock primitive, which uses the Raft consensus algorithm and is explicitly designed to resist split-brain, provides monotonic fencing tokens that you can use to protect writes to external systems. For the cache itself, split-brain protection (configured via minimum cluster size) will cause operations on the minority partition to throw SplitBrainProtectionException rather than silently succeed — again, a failure you can handle is better than a silent corruption you cannot.
// hazelcast.xml — refuse operations if partition drops below 2 members
<split-brain-protection name="two-member-quorum"
enabled="true">
<minimum-cluster-size>2</minimum-cluster-size>
</split-brain-protection>
<map name="inventory">
<split-brain-protection-ref>two-member-quorum</split-brain-protection-ref>
</map>
With this in place, writes to the minority partition fail with a SplitBrainProtectionException rather than producing divergent state that silently corrupts during the merge. Your Java application should catch this exception and treat it as a cache unavailability event — fall through to the source of record rather than retrying against a partitioned cache.
Mistake #3: Running ALLOW_READ_WRITES and calling it “high availability”
Infinispan takes the most explicit and configurable approach to partition handling of the three tools. It exposes three strategies via the partition-handling configuration element, and the choice maps directly onto the CP-vs-AP tradeoff:
| Strategy | Reads during partition | Writes during partition | Consistency guarantee |
|---|---|---|---|
ALLOW_READ_WRITES | Allowed (may be stale) | Allowed on both sides | None — divergence possible |
ALLOW_READS | Allowed (may be stale) | Refused on minority | Partial — reads may be stale |
DENY_READ_WRITES | Refused on minority | Refused on minority | Strong — errors instead of stale data |
The critical fact that the Red Hat Data Grid documentation confirms: the default partition handling strategy is ALLOW_READ_WRITES. This means that by default, Infinispan chooses availability over consistency. Both partitions accept reads and writes with no restrictions. Each partition may see different data. Upon merge, conflicts are resolved by the configured EntryMergePolicy — and the default merge policy is PREFERRED_ALWAYS, meaning the entry from the preferred partition wins and the losing partition’s version is discarded, silently.
What your Java code observes under the default configuration:
// Both partitions running ALLOW_READ_WRITES (default)
// App instance on partition A
cache.put("session:user7", sessionDataV2); // succeeds — no exception
// App instance on partition B (simultaneously)
cache.put("session:user7", sessionDataV3); // succeeds — no exception
// Partition heals — merge runs PREFERRED_ALWAYS policy
// partition B was larger, so B's entries are "preferred"
cache.get("session:user7"); // returns sessionDataV3
// sessionDataV2 is gone, never acknowledged as lost
The application never sees an exception. The application never sees a warning. It writes, reads, and receives clean responses — while internally, half its writes to the losing partition are queued for silent discard.
The fix is explicit strategy selection. For any cache holding data where consistency matters more than uptime, configure DENY_READ_WRITES. Your Java code will then receive AvailabilityException on the minority partition during a split, which is exactly the kind of observable failure that lets you fall back to a database read or a circuit breaker:
<!-- infinispan.xml — choose consistency over silent corruption -->
<distributed-cache name="sessions">
<partition-handling when-split="DENY_READ_WRITES"
merge-policy="PREFERRED_NON_NULL" />
</distributed-cache>
For caches where stale reads are acceptable but divergent writes are not — think: read-heavy product catalogues — ALLOW_READS is the middle ground. It keeps reads available across both partitions (accepting that some clients may see older data) while refusing writes on the minority side, preventing divergence.
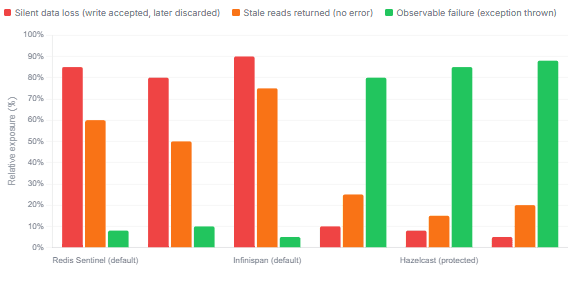
What each tool exposes to your Java code during an active split-brain (default config)
What your application code must do regardless of which tool you use
Configuring your cache tool correctly is a necessary first step. It is not sufficient. The infrastructure can be perfectly configured and you can still lose data if the application layer makes optimistic assumptions about cache writes. Here are three safeguards that apply across all three tools.
Write-through with version tokens, not write-behind
If your application writes to the cache and considers the data committed without also writing to a durable store, a split-brain will produce invisible data loss. The correct pattern for any data that matters is write-through: the cache and the database are updated in the same logical operation, and success is not acknowledged until both confirm the write. The cache then serves as a read-through accelerator, not the source of truth. This is especially critical for Hazelcast in-process deployments, where it is tempting to treat the cluster as the database.
Treat SplitBrainProtectionException and AvailabilityException as cache-miss signals
When your tool is correctly configured to raise exceptions on the minority partition, your Java code needs to catch them and execute the cache-miss path — query the database, rehydrate, continue — rather than propagating the exception as a fatal error. A split-brain is a temporary infrastructure condition, not a bug in your code. Treating it as a hard failure causes cascading outages; treating it as a cache miss causes a brief performance degradation while the partition resolves.
try {
return cache.get(key);
} catch (SplitBrainProtectionException | AvailabilityException e) {
// minority partition — fall through to source of record
log.warn("Cache unavailable during partition, reading from DB: {}", key);
return repository.findById(key)
.orElseThrow(() -> new ResourceNotFoundException(key));
}
Never cache quantities that must be exact without an idempotency check
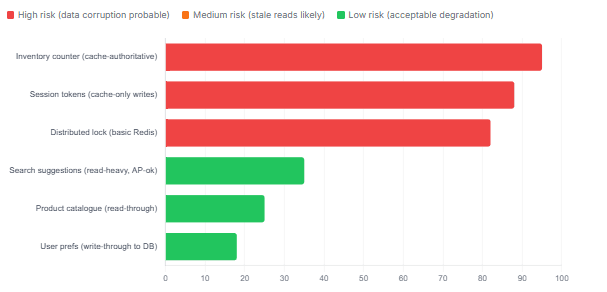
Inventory counts, account balances, seat allocations, rate-limit counters — any value that is decremented or incremented under concurrent load is catastrophically vulnerable to split-brain divergence. During a partition, both sides can independently decrement the same counter. During the merge, one side’s decrements are discarded. You have oversold. The cache is not the right place to hold these values authoritatively. Use your database’s optimistic locking or the WATCH/MULTI/EXEC pattern in Redis, where the transaction fails fast rather than silently committing against a partitioned master.
Risk score by use case and cache pattern during a 60-second split-brain event
Side-by-side: defaults, risks, and fixes at a glance
| Tool | Default split-brain behaviour | What Java code observes (default) | Protective config | What Java code observes (protected) |
|---|---|---|---|---|
| Redis Sentinel | Old master accepts writes until failover completes | Write OK → later discarded silently | min-replicas-to-write 1 | RedisException on isolated master writes |
| Hazelcast | Both partitions accept writes; losers discarded on merge | Write OK → may be overwritten silently post-merge | Split-brain protection (min cluster size) | SplitBrainProtectionException on minority writes |
| Infinispan | ALLOW_READ_WRITES — full divergence permitted | All ops succeed; losing side discarded on merge | DENY_READ_WRITES strategy | AvailabilityException on minority ops |
What we learned
Split-brain is not a theoretical edge case — network partitions happen in Kubernetes rolling restarts, cloud availability zone blips, and GC pauses long enough to trigger heartbeat timeouts. All three tools examined here default to availability over consistency, which means that by default, a split-brain event produces silent data loss or silent divergence rather than observable failures. Redis Sentinel accepts writes to an isolated master that will be discarded when it is demoted. Hazelcast silently discards minority-partition writes on merge, with no notification to the application.
Infinispan’s default ALLOW_READ_WRITES strategy permits full divergence across both partitions. The fix at the infrastructure layer is one configuration change per tool — min-replicas-to-write, split-brain protection with a minimum cluster size, or DENY_READ_WRITES. But configuration alone is not enough: the application layer must catch partition exceptions as cache-miss signals, use write-through for any data that matters, and never store authoritatively mutable quantities solely in the cache. A write failure you can catch and handle is always preferable to a silent corruption you discover in production.
