Virtual Threads Two Years In: Production War Stories, the Pinning Edge Cases, and What JDK 25 Fixed
Java 21 shipped virtual threads in September 2023. Two-plus years of production data later, the picture is more nuanced than the launch hype suggested. Teams at Netflix hit real deadlocks. HikariCP’s GitHub tracked carrier starvation. Caffeine’s maintainers called it a JDK-level problem. Here is what actually happened — and why JDK 24 finally fixed it at the source.
1. The Promise, Honestly Stated
Virtual threads are not a new concurrency paradigm. They are not reactive programming in a different skin. The value proposition is narrower than the launch marketing suggested — and that narrowness is actually a strength, because it is precise. Virtual threads solve one specific problem: the cost of blocking I/O on OS threads.
In the classic thread-per-request model, a platform thread blocks for the entire duration of every database call, every HTTP request to a downstream service, every file read. That thread, consuming megabytes of stack memory and OS-level resources, sits idle waiting. You can only run as many concurrent requests as you have threads, which in practice means a few hundred to a few thousand before the machine starts sweating. Reactive programming solved this by never blocking at all — but at the cost of callback-driven code that is famously difficult to write, read, debug, and reason about.
Virtual threads solve it differently. They let you write simple, sequential, blocking code — the kind every Java developer already knows — but under the hood, the JVM unmounts the virtual thread from its OS carrier thread the moment it blocks, freeing that carrier to serve other work. When the blocking operation completes, the virtual thread remounts on any available carrier. A handful of OS threads can now serve hundreds of thousands of concurrent virtual threads, with no reactive callbacks in sight.

What virtual threads are not: a solution for CPU-bound workloads. If your virtual thread is running image processing, cryptography, or complex computation rather than waiting for I/O, it cannot unmount. It sits on a carrier the entire time. Having more virtual threads than CPU cores gives you zero extra CPU cycles — it just means more threads contending for the same carriers. Teams that expected virtual threads to speed up CPU-heavy services in 2023 were disappointed, and that confusion generated a lot of the early negative sentiment.
2. Understanding Pinning From First Principles
The central technical challenge of virtual threads in Java 21 through 23 was pinning — the condition where a virtual thread gets stuck to its carrier OS thread and cannot unmount, even during a blocking operation. Understanding why this happened requires knowing something about how the JVM implemented monitors before virtual threads existed.
When you write synchronized(obj), the JVM compiles it to monitorenter and monitorexit bytecodes. These acquire and release an object monitor — the JVM’s internal locking mechanism. Every Java object has a monitor. When a thread enters a synchronized block, the JVM records which thread owns that monitor. The critical detail: it records the OS thread identity, not the virtual thread identity. Monitors predate virtual threads by decades and were designed around OS threads exclusively.
This creates a fundamental conflict. Suppose a virtual thread (call it VT-A) running on carrier CT-1 enters a synchronized block and acquires the monitor on some object. It then performs an I/O call inside that block. Normally the JVM would unmount VT-A, freeing CT-1. But CT-1 still owns the monitor — the JVM recorded CT-1 as the holder. If the JVM frees CT-1 and mounts a different virtual thread (VT-B) on it, that new virtual thread is now running on a carrier that holds a lock it never acquired. If VT-B then tries to enter the same synchronized block, the JVM sees CT-1 as the owner and allows re-entry — breaking mutual exclusion entirely.
The JVM’s solution in Java 21–23 was to refuse to unmount. When a virtual thread entered a synchronized block, it became pinned to its carrier — the carrier could not serve any other virtual threads until the synchronized block completed. This preserved correctness but destroyed the scalability benefit. If enough virtual threads pinned enough carriers simultaneously, the scheduler ran out of available carriers. New virtual threads queued up waiting. Under high concurrency, the system stalled.
There were two distinct pinning conditions. The first — and the one that JEP 491 fixed — was the synchronized keyword. The second, which still exists today, is native code: when a virtual thread calls a JNI method or Foreign Function, it also pins because the JVM cannot safely manage thread state across the native frame boundary. The native-code pinning remains in JDK 25; only the synchronized pinning has been resolved.
Carrier Thread Behavior: Synchronized Pinning vs. Normal I/O Block
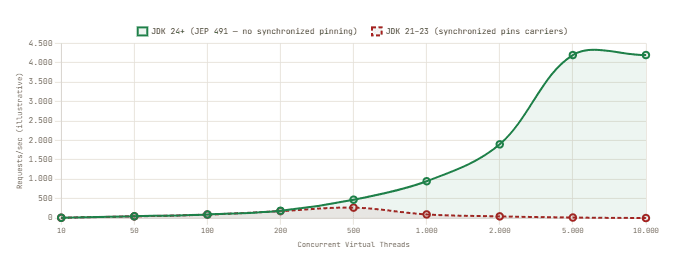
3. The Netflix Deadlock: A Production Post-Mortem
The clearest real-world account of what pinning looks like in production came from Netflix in July 2024. Their JVM Ecosystem team published a post-mortem titled “Java 21 Virtual Threads — Dude, Where’s My Lock?” that became required reading for anyone running virtual threads seriously.
Netflix: Hung Instances With Thousands of CLOSE_WAIT Sockets
Netflix was running Java 21 with Spring Boot 3 and embedded Tomcat. After enabling virtual threads for request handling, services began experiencing intermittent timeouts and complete unresponsiveness. JVM instances stayed alive but stopped serving any traffic. The symptom that led to the root cause: thousands of TCP sockets stuck in CLOSE_WAIT state — meaning the remote side had closed the connection, but the local application had not processed the close because it was deadlocked.
Symptom
Intermittent full service hangs. JVM alive, traffic dead. Thousands of sockets in CLOSE_WAIT. No obvious exception in logs — the application was simply stuck, not crashed.
Root Cause
A tracing library used internally contained synchronized blocks. Under high concurrency, virtual threads pinned all available carrier threads inside those blocks. New virtual threads queued, waiting for carriers. The pinned virtual threads needed I/O to complete — but the I/O threads themselves were virtual threads waiting for carriers. Classic deadlock.
How They Found It
Heap dump showed the lock was unowned — no thread held it — yet all threads waiting for it could not proceed. This transient-but-stuck state was the giveaway. JFR jdk.VirtualThreadPinned events confirmed the pinning source was the tracing library.
Resolution
Identified and updated the tracing library to a version that replaced synchronized with ReentrantLock. The team also published a reproducible test case to prevent recurrence. The same fundamental failure mode was confirmed by formal TLA+ modelling by a separate engineer at Netflix.
The Netflix case was important not just for what it revealed technically, but for what it showed operationally: the problematic synchronized block was inside a library the application team did not write and did not control. They could not search their own codebase for synchronized and fix it. The dependency was two or three levels deep in the classpath. This is the production pattern that was most damaging — not teams writing bad concurrent code themselves, but teams using good code that happened to depend on libraries that had not been updated for the virtual thread era.
“The problem resulted from a classic deadlock scenario in which virtual threads could not proceed because the required lock was held by other virtual threads pinned to all available OS threads.”— InfoQ coverage of Netflix’s Java 21 Virtual Threads case study, August 2024
4. The Ecosystem Scramble: Libraries That Bit Teams
Netflix was not alone. The eighteen months following Java 21’s release were characterized by a steady stream of library maintainers discovering that their code pinned virtual threads under load. The pattern was consistent: library written for platform threads, uses synchronized internally for thread safety, works perfectly for years, then deadlocks under virtual thread concurrency.
HK- 2023–2024 · HikariCP- The Connection Pool Pinning Issue
HikariCP’s ConcurrentBag used ThreadLocal variables to cache connections for thread reuse — an optimization that made sense for pooled platform threads but created per-task allocation overhead with virtual threads. Separately, HikariDataSource.getConnection() used a synchronized block in the acquisition path. Under high virtual thread concurrency, carrier starvation was reproducible: 9 of 10 carriers blocked on synchronized, the 10th parked waiting for a lock, none able to proceed. GitHub issue #2293 documented this precisely.
CF- 2023 · Caffeine Cache- ConcurrentHashMap’s Internal Monitors
Caffeine’s high-performance cache is built on top of ConcurrentHashMap, which itself uses synchronized monitors internally in specific code paths. When virtual threads called cache.get() with a loader function that performed I/O, they hit ConcurrentHashMap‘s internal monitors, pinning carriers. The Caffeine maintainer documented this explicitly: it was a JDK-level problem, not a Caffeine problem. The recommended workaround was to use AsyncCache instead of synchronous loading.
HC- 2024 · Apache HttpClient 5 (pre-5.4)- Connection Pool Acquisition Pinning
Apache HTTP Client 5 had synchronized blocks in PoolingHttpClientConnectionManager.lease() — the code path that acquires a connection during network operations. This is one of the highest-frequency paths in any service making HTTP calls. Version 5.4 explicitly addressed this: its release notes state that it “ensures compatibility with Java Virtual Threads by replacing synchronized keywords in critical sections with Java lock primitives.”
MJ- 2023 · MySQL Connector/J- JDBC Driver Internal Synchronization
The MySQL JDBC driver used synchronized in internal I/O paths. A community contribution replaced these with ReentrantLock, shipped in Connector/J 9.0.0. The release note was explicit: “Synchronized blocks in the Connector/J code were replaced with ReentrantLocks. This allows carrier threads to unmount virtual threads when they are waiting on IO operations, making Connector/J virtual-thread friendly.”
R4J- 2025 · Resilience4j- Waiting for JDK 25 LTS
The Resilience4j team explicitly tracked the JDK’s pinning fix as a prerequisite for fully resolving their virtual thread compatibility issues. A GitHub issue notes: “However, in JDK 24, the pinned issue caused by synchronized has been eliminated… This requires an upgrade to the next LTS version, JDK 25.” Many ecosystem teams made the same calculation: wait for JDK 25 LTS rather than maintaining workarounds that the JVM fix would render unnecessary.
Library Virtual Thread Compatibility — Before and After Remediation
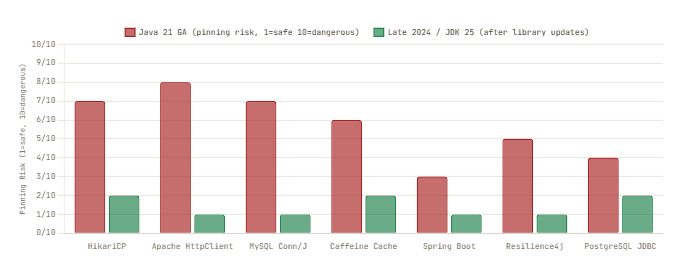
5. The ThreadLocal Time Bomb
Alongside pinning, the second major production issue teams ran into was subtler and slower to manifest: ThreadLocal misuse. This one does not cause deadlocks — it causes invisible memory pressure that grows with concurrency and only surfaces under realistic load.
The ThreadLocal pattern was designed for pooled platform threads that lived for the life of the application. The logic was sound: an expensive object — a SimpleDateFormat, a JSON serializer, a database connection wrapper — gets created once per thread and reused across all the requests that thread handles. With a pool of 200 platform threads, you get 200 instances, total, for the application’s lifetime.
Virtual threads break this assumption completely. Virtual threads are never pooled and never reused by unrelated tasks. Every new virtual thread gets a fresh ThreadLocal state. At low concurrency, this is invisible. At 50,000 concurrent virtual threads — a number that is advertised as a selling point of the model — you now have 50,000 instances of an object designed to have 200. Heap growth becomes non-linear with concurrency. GC pressure spikes. The application slows down not from deadlock but from garbage collection overhead that tracking tools struggle to attribute correctly.
Platform thread assumption (breaks with VT)
ThreadLocal caching pattern: An expensive formatter or serializer is cached in a ThreadLocal. With a pool of 200 platform threads, this creates 200 instances, ever. Threads are long-lived and requests are multiplexed across them, so the cache is reused constantly. Entirely rational, efficient, idiomatic Java.
With virtual threads: Each of 50,000 concurrent virtual threads creates its own fresh instance on first access. The cache provides zero reuse. You have manufactured a 50,000-object allocation per request cycle.
Virtual-thread-safe alternatives
For context propagation (user ID, trace ID, security principal): Use Scoped Values (finalized in JDK 25 via JEP 506). Values are immutable, scope-bound, and child threads share the parent’s binding without copying — exactly what you want at high concurrency.
For expensive reusable objects: Instantiate locally within the task (virtual thread creation is cheap enough) or move to a bounded ExecutorService for the specific objects that must be pooled. Use connection pools (HikariCP correctly configured) rather than thread-local pools.
The real danger, as engineers who migrated in 2024 discovered, is that the problematic ThreadLocal often lives inside a library. Spring Security historically stored its SecurityContext in a ThreadLocal. MDC logging in Logback stores trace IDs in a ThreadLocal. Hibernate’s session management has historically touched ThreadLocal. You cannot fix these by searching your own code. You have to know which libraries are doing it and whether they have been updated — or whether, like Spring Security 6.x, they already provide configuration to use alternative propagation mechanisms.
To find ThreadLocal usage in your virtual thread code paths before production surprises you, run with -Djdk.traceVirtualThreadLocals. You will get a stack trace whenever a virtual thread mutates a thread-local variable. In production, monitor heap growth under load with -XX:NativeMemoryTracking=summary — non-linear heap growth as concurrent request count scales up is the signature of runaway thread-local allocation.
6. Observability: Seeing What Is Actually Happening
One of the less-discussed challenges of virtual thread adoption in Java 21–23 was that standard observability tools were not built for millions of lightweight threads. jstack, top, and basic thread dumps produced output that was either incomplete, overwhelming, or simply did not show virtual threads in a useful way.
The practical tooling that emerged as actually useful in production breaks down into three categories.
| Tool / Method | What It Shows | When to Use It | JDK Availability |
|---|---|---|---|
jdk.VirtualThreadPinned JFR event | Stack trace of any pinning event lasting over 20ms threshold. Enabled by default. | Continuous production monitoring — the first signal that something is pinning | JDK 21+ |
jfr print --events | Full event list including VirtualThreadStart, VirtualThreadEnd, VirtualThreadPinned, VirtualThreadSubmitFailed | Post-incident analysis on saved recording files | JDK 21+ |
-Djdk.tracePinnedThreads | Stack trace to stdout whenever a virtual thread pins its carrier | Development and staging — noisy in production; removed in JDK 24+ as pinning from synchronized is gone | JDK 21–23 only |
Thread dump (jcmd or signal) | JDK 21+ includes virtual threads in thread dumps, but can be enormous — filter for pinned carrier states | Debugging a live hung application; heap dump confirms lock state | JDK 21+ |
jdk.VirtualThreadScheduler.* counters | Scheduler pool size, queue depth, parallelism level — watches for carrier starvation | Ongoing capacity monitoring in high-concurrency services | JDK 21+ |
-Djdk.traceVirtualThreadLocals | Stack trace on every ThreadLocal mutation from a virtual thread | One-time audit during migration to find ThreadLocal usage | JDK 21+ |
The most practically important of these is the jdk.VirtualThreadPinned JFR event. It is enabled by default with a 20ms threshold — meaning you do not pay any cost unless a pinning event actually occurs and exceeds the threshold. In practice, running JFR continuously in production and setting up an alert on this event is the single most reliable early warning system for virtual thread problems, both before and after the JDK 24 fix. Native-code pinning still produces it; JFR remains the detection mechanism.
7. JEP 491: What the Fix Actually Changed in the JVM
JEP 491 — “Synchronize Virtual Threads without Pinning” — shipped in JDK 24 (March 2025) and carries forward into JDK 25 LTS (September 2025). Understanding what it actually changed at the JVM level is important both for assessing its scope and for understanding the edge cases it did not address.
The core change: the JVM was reimplemented so that monitors track ownership by virtual thread identity rather than carrier thread identity. When a virtual thread acquires a monitor and then performs a blocking operation inside the synchronized block, the JVM can now safely unmount the virtual thread from its carrier. The carrier is freed to serve other virtual threads. When the blocking operation completes, the virtual thread remounts on any available carrier and resumes inside the synchronized block — still holding the monitor, because the monitor is now associated with the virtual thread, not the carrier.
JEP 491: The Concrete ResultRunning the same code that deadlocked Netflix on JDK 24 or JDK 25 does not deadlock. Virtual threads can enter
synchronizedblocks, perform I/O, unmount, and remount without pinning their carriers. Thejdk.tracePinnedThreadsJVM flag was removed in JDK 24 becausesynchronized-based pinning no longer occurs. Teams can use thesynchronizedkeyword without worrying about virtual thread scalability — it works correctly again.
The JEP also improved Object.wait() and Object.notify() within synchronized blocks. In Java 21–23, calling Object.wait() in a synchronized block could pin the carrier. In JDK 24+, a virtual thread that calls Object.wait() inside a synchronized block will unmount and remount when signaled, without pinning. This matters for code patterns that use wait/notify for condition signaling — a pattern that is common in legacy synchronization code.
Three narrow cases still pin virtual threads even after JEP 491, by design. When resolving a symbolic class reference and the virtual thread blocks while loading a class, when blocking inside a class initializer, and when waiting for a class to be initialized by another thread. As the JEP notes, these cases should rarely cause issues in practice — class loading is a startup-time phenomenon, not a steady-state one. The OpenJDK team has committed to revisiting them if they prove problematic in production.
JDK 21–23: synchronized pins the carrier
- Virtual thread VT-A enters
synchronized(obj). - JVM records: “OS thread CT-1 owns this monitor.”
- VT-A performs I/O inside the synchronized block.
- JVM cannot unmount VT-A — CT-1 would lose monitor ownership.
- CT-1 is pinned. No other virtual thread can run on CT-1 until the block exits.
- Under high concurrency: all carriers pinned → starvation → deadlock.
JDK 24+ (JEP 491): synchronized is safe
- Virtual thread VT-A enters
synchronized(obj). - JVM records: “Virtual thread VT-A owns this monitor.”
- VT-A performs I/O inside the synchronized block.
- JVM unmounts VT-A from CT-1. CT-1 is freed immediately.
- CT-1 serves other virtual threads.
- When I/O completes, VT-A remounts on any available carrier, still holding the monitor. Mutual exclusion preserved. No pinning.
8. What JDK 25 Still Does Not Fix
Being honest about what JEP 491 did not solve is important for teams making upgrade decisions. JDK 25 is not a complete resolution of every virtual thread edge case — it is a significant resolution of the most damaging one.
| Issue | Status in JDK 25 | Severity | Mitigation |
|---|---|---|---|
synchronized pinning during I/O | Fixed (JEP 491) | Was: critical | None needed — use synchronized freely |
| Native code (JNI / Foreign Function) pinning | Still pins carriers | Medium — depends on JNI usage | Offload JNI-heavy work to bounded platform thread pools; monitor with JFR |
| Class-loading-time pinning | By design, rarely hits steady state | Low — startup only | Pre-warm class loading before traffic; rarely actionable |
| ThreadLocal caching anti-pattern | Not fixed — architectural | High at scale — memory pressure | Migrate to Scoped Values (JDK 25 finalized); audit with -Djdk.traceVirtualThreadLocals |
| CPU-bound virtual threads starving carriers | Fundamental — not fixable | High for CPU workloads | Route CPU-bound work to a separate bounded platform thread executor |
| Unbounded concurrency / resource exhaustion | Fundamental — not fixable | Medium — application design | Use semaphores to bound concurrency against external resources; do not replace all thread pools with virtual threads blindly |
| Debugger / profiler opacity | Improved but incomplete | Low–medium — operational friction | Use JFR + JDK Mission Control; most modern IDEs have improved virtual thread support |
The unbounded concurrency issue deserves particular emphasis because it is unintuitive. Virtual threads make it trivially easy to spin up a million concurrent operations, but the resources those operations consume — database connections, HTTP connections, file descriptors — are still finite. A service that was previously rate-limited by its thread pool size (say, 200 threads → maximum 200 concurrent database queries) suddenly has no such limit with virtual threads. The database pool becomes the bottleneck, but now hundreds of virtual threads are fighting for 20 connections instead of the pool being the natural limiter. The solution is explicit semaphore-based throttling around resource-constrained operations — not abandoning virtual threads, but using them in conjunction with the right bounding primitives.
9. Migration Guidance: When and How to Upgrade
Given two-plus years of production data, the practical guidance on whether and when to migrate has become clearer than it was at Java 21’s launch.
The LTS argument is straightforward. JDK 25 (September 2025) is the first LTS release that contains JEP 491’s pinning fix. Teams who adopted virtual threads on JDK 21 and hit pinning problems were stuck either waiting for JDK 25 or applying workarounds (replacing
synchronizedwithReentrantLockin their own code, updating dependencies, increasing the carrier thread count withjdk.virtualThreadScheduler.parallelism). JDK 25 removes the need for those workarounds forsynchronized-based pinning.
If upgrading immediately is not possible, the practical checklist for JDK 21–23 production environments is: run JFR with jdk.VirtualThreadPinned events enabled and set an alert threshold, audit all transitive dependencies for synchronized usage in I/O paths, update to the virtual-thread-aware versions of HikariCP, Apache HttpClient, and any JDBC drivers in use, and configure the scheduler’s maximum parallelism (jdk.virtualThreadScheduler.maxPoolSize) as a safety valve against full starvation.
For teams deciding whether to enable virtual threads at all, the decision tree is simpler than many articles suggest. Is your service I/O-bound — spending most of its time waiting for databases, HTTP calls, or message queues? Enable virtual threads. Is it CPU-bound — running computation for most of its time? Do not expect throughput gains; focus on other optimizations. Is it mixed? Enable virtual threads but route CPU-heavy tasks explicitly to a bounded platform thread executor. In all cases, upgrade to JDK 25 before taking virtual threads to high-concurrency production.
10. What We Have Learned
Two years of production data has turned virtual threads from a promising preview into a well-understood technology with specific strengths, specific failure modes, and a now-resolved architectural limitation at its center. The pinning problem — carrier thread starvation from synchronized blocks — was real and dangerous. Netflix documented it as a production deadlock. HikariCP, Caffeine, Apache HttpClient, and MySQL Connector/J all had to be updated. The root cause was a thirty-year-old JVM implementation detail: monitors tracked OS thread identity, not virtual thread identity. JEP 491 fixed that at the source, shipping in JDK 24 and landing in JDK 25 LTS.
The remaining rough edges are architectural rather than JVM-level bugs. ThreadLocal caching is genuinely unsafe at virtual thread scale — not incorrect, but expensive in ways that only surface under load. Scoped Values, finalized in JDK 25, are the correct replacement for context propagation. Native-code pinning still exists and still requires JFR monitoring. CPU-bound work still does not benefit from virtual threads and still starves carriers if not routed to a separate executor. Unbounded concurrency against bounded resources requires explicit semaphore-based throttling.
The technology is production-ready on JDK 25. The checklist for safe adoption is short: upgrade to JDK 25 LTS, audit for ThreadLocal caching patterns, enable JFR pinning event monitoring as an ongoing alarm, bound concurrency explicitly for resource-constrained operations, and resist the instinct to treat virtual threads as a general-purpose performance upgrade. They solve one problem — blocking I/O scalability — and they solve it exceptionally well.
