Project Loom is one of the projects sponsored by the Hotspot Group, initiated to deliver high throughput and lightweight concurrency model into the JAVA world. At the time of writing this post, project Loom is still under active development and its API might change.
Why Loom?
The first question that might and should pop up for every new project is that why?
Why do we need to learn something new and where it does help us? (if it really does)
So to answer this question specifically for Loom we first need to know the basics of how the existing threading system in JAVA is working.
Every thread spawned inside a JVM ends up with a one to one corresponding thread in the OS kernel space with its own stack, registers, program counter, and state. Probably the biggest part of every thread would be its stack, the stack size is in Megabytes scale and usually is between 1MB to 2MB.
So these types of threads are expensive in terms of both initiation and runtime. It is not possible to spawn 10 thousand of the threads in one machine and expect that it just works.
One might ask why do we even need that many threads? Given that CPUs just have a few hyper threads. e.g. CPU Internal Core i9 has 16 threads in total.
Well, the CPU is not the only resource that your application uses, any software without I/O just contributes to global warming!
As soon as a thread needs I/O the OS tries to allocate the required resource to it and schedules another thread that needs CPU in the meantime.
So the more threads we have in the application the more we can utilize these resources in parallel.
One very typical example is a web server. every server is able to handle thousands of open connections at each point of time but handling that many connections at the same time either needs thousands of threads or async non-blocking code (I will probably write another post in the coming weeks to explain more about asynchronous code) and as mentioned before thousands of OS threads is neither what you nor the OS would be happy about!
How Loom Helps?
As part of the Project Loom, a new type of thread called Fiber is introduced. Fiber also called Virtual thread, Green thread or User thread as these names would imply is handled completely by the VM and OS does not even know that such threads exist. It means that not every VM thread would need to have a corresponding thread at the OS level! Virtual threads might be blocked by I/O or wait to get a signal from another thread, however, in the meantime the underlying threads can be utilized by other Virtual threads!
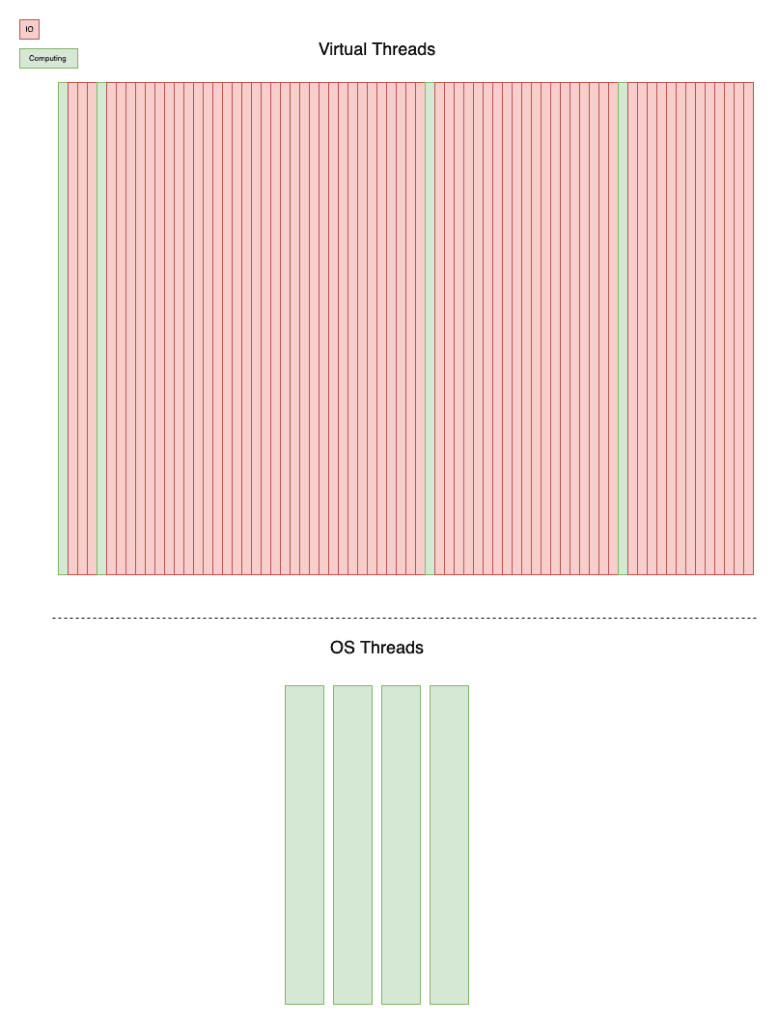
The picture above illustrates the relationship between the Virtual threads and the OS threads. The virtual threads can simply be blocked by I/O and in such cases, the underlying thread is going to be used by another Virtual thread.
The memory footprint of these virtual threads would be in the Kilobytes scale rather than Megabyte. Their stack can potentially be expanded after their spawn if needed so that the JVM doesn’t need to allocate significant memory to them.
So now that we have a very lightweight way to implement the concurrency we can rethink the best practices that exist around classic threads in Java too.
Nowadays the most used construct to implement concurrency in java is different implementations of ExecutorService. They have quite convenient APIs and are relatively easy to use. Executor services have an internal thread pool to control how many threads can be spawned based on the characteristics that the developer defines. This thread pool is mainly used to limit the number of OS threads the application creates since as we mentioned above they are expensive resources and we should reuse them as much as possible. But now that it’s possible to spawn lightweight virtual threads, we can rethink the way we use ExecutorServices as well.
Structured Concurrency
Structured concurrency is a programming paradigm, a structured approach to write concurrent programs that are easy to read and maintain. The main idea is very similar to the structured programming if the code has a clear entrance and exit points for concurrent tasks, reasoning about the code would be way easier in comparison to starting concurrent tasks that might last longer than the current scope!
To be more clear on how a structured concurrent code might look like consider the following pseudo-code:
1 2 3 4 5 6 7 | void notifyUser(User user) { try(var scope = new ConcurrencyScope()) { scope.submit( () -> notifyByEmail(user)); scope.submit( () -> notifyBySMS(user)); } LOGGER.info("User has been notified successfully");} |
The notifyUser method is supposed to notify a user via Email and SMS and once both are done successfully this method is going to log a message. With structured concurrency it is possible to guarantee that the log would be written just after both notify methods are done. In other words the try scope would be done if all the started concurrent jobs inside it finish!
Note: To keep the example simple we assume notifyByEmail and notifyBySMS In the example above do handle all possible corner cases internally and always make it through.
Structured Concurrency with JAVA
In this section, I would show how it is possible to write structured concurrent applications in JAVA and how Fibers would help to scale the application with a very simple example.
What we are going to solve
Imagine we have 10 thousand tasks all I/O bound and each task takes exactly 100ms to finish. We are asked to write an efficient code to accomplish these jobs.
We use class Job defined below to mimic our jobs.
1 2 3 4 5 6 7 8 9 | public class Job { public void doIt() { try { Thread.sleep(100l); } catch (InterruptedException e) { e.printStackTrace(); } }} |
First attempt
In the first attempt let’s write it by using a Cached Thread Pool and OS Threads.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public class ThreadBasedJobRunner implements JobRunner { @Override public long run(List<Job> jobs) { var start = System.nanoTime(); var executor = Executors.newCachedThreadPool(); for (Job job : jobs) { executor.submit(job::doIt); } executor.shutdown(); try { executor.awaitTermination(1, TimeUnit.DAYS); } catch (InterruptedException e) { e.printStackTrace(); Thread.currentThread().interrupt(); } var end = System.nanoTime(); long timeSpentInMS = Util.nanoToMS(end - start); return timeSpentInMS; }} |
In this attempt, we haven’t applied anything from project Loom. Just a cached thread pool to ensure that idle threads would be used rather than creating a new thread.
Let’s see how long it takes to run 10,000 jobs with this implementation. I have used the code below to find the top 10 fastest runs of the code. To keep it simple no micro benchmarking tool has been used.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | public class ThreadSleep { public static void main(String[] args) throws InterruptedException { List<Long> timeSpents = new ArrayList<>(100); var jobs = IntStream.range(0, 10000).mapToObj(n -> new Job()).collect(toList()); for (int c = 0; c <= 100; c++) { var jobRunner = new ThreadBasedJobRunner(); var timeSpent = jobRunner.run(jobs); timeSpents.add(timeSpent); } Collections.sort(timeSpents); System.out.println("Top 10 executions took:"); timeSpents.stream().limit(10) .forEach(timeSpent -> System.out.println("%s ms".formatted(timeSpent)) ); }} |
The result on my machine is:
Top 10 executions took:
694 ms
695 ms
696 ms
696 ms
696 ms
697 ms
699 ms
700 ms
700 ms
700 ms
So far we have a code that at best case takes around 700ms to run 10,000 jobs on my machine. Let’s implement the JobRunner this time by using Loom features.
Second Attempt (with Fibers)
In the implementation with Fibers or Virtual Threads, I am going to code the concurrency in a structured way as well.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | public class FiberBasedJobRunner implements JobRunner { @Override public long run(List<Job> jobs) { var start = System.nanoTime(); var factory = Thread.builder().virtual().factory(); try (var executor = Executors.newUnboundedExecutor(factory)) { for (Job job : jobs) { executor.submit(job::doIt); } } var end = System.nanoTime(); long timeSpentInMS = Util.nanoToMS(end - start); return timeSpentInMS; }} |
Perhaps the first noteworthy thing about this implementation is its conciseness, if you compare it against ThreadBasedJobRunner you would notice this code has less lines! The main reason is the new change in ExecutorService interface that now extends Autocloseable and as a result, we can use it in try-with-resources scope. The codes after the try block will be executed once all the submitted jobs are done.
This is exactly the main construct we use to write structured concurrent codes in JAVA.
The other new thing in the code above is the new way that we can build thread factories. Thread class has a new static method called builder that can be used to either create a Thread or ThreadFactory.
What this line of code is doing is creating a thread factory that created Virtual threads.
1 | var factory = Thread.builder().virtual().factory(); |
Now Let’s see how long it takes to run 10,000 jobs with this implementation.
Top 10 executions took:
121 ms
122 ms
122 ms
123 ms
124 ms
124 ms
124 ms
125 ms
125 ms
125 ms
Given that Project Loom, is still under active development and there are still spaces to improve the speed but the result is really great.
Many applications whether thoroughly or partially can benefit from Fibers with the minimum effort! The only thing that needs to be changed is the Thread Factory of the thread pools and that’s it!
Specifically, in this example, the runtime speed of the application improved ~6 times, However the speed is not the only thing we achieved here!
Although I don’t want to write about the memory footprint of the application that has been drastically decreased by using Fibers, but I would highly recommend you to play around the codes of this post accessible here and compare the amount of memory used along with the number of OS threads each implementation takes! You can download the official early access build of Loom here.
In the coming posts, I will write more about other APIs project Loom is introducing and how we can apply them in real life use cases.
Please don’t hesitate to share your feedbacks through comments with me
Published on Java Code Geeks with permission by Soroosh Sarabadani, partner at our JCG program. See the original article here: OpenJDK Loom and Structured Concurrency Opinions expressed by Java Code Geeks contributors are their own. |

Hi…
Structured Concurrency. The core concept of “structured concurrency” is that when control splits into concurrent tasks that they join up again. If a main task splits into several concurrent sub-tasks to be executed by spawning threads then those threads must terminate before the main task can complete.