Bill Gates once said: “I choose a lazy person to do a difficult job because a lazy person will find an easy way to do it.” Nothing can be more true when it comes to streams. In this article, you will learn how a Stream avoids unnecessary work by not performing any computations on the source elements before a terminal operation is invoked and how only a minimum amount of elements are ever produced by the source.
This article is the third out of five, complemented by a GitHub repository containing instructions and exercises to each unit.
Part 1: Creating Streams
Part 2: Intermediate Operations
Part 3: Terminal Operations
Part 4: Database Streams
Part 5: Creating a Database Application Using Streams
Terminal Operations
Now that we are familiar with the initiation and construction of a Stream pipeline we need a way to handle the output. Terminal operations allow this by producing a result from the remaining elements (such ascount()) or a side-effect (such asforEach(Consumer)).
A Stream will not perform any computations on the elements of the source before the terminal operation is initiated. This means that source elements are consumed only as needed – a smart way to avoid unnecessary work. This also means that once the terminal operation is applied, the Stream is consumed and no further operations can be added.
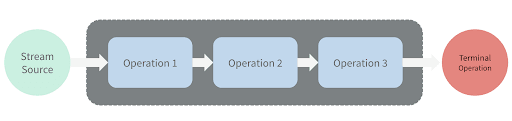
Let’s look at what terminal operations we can apply to the end of a Stream pipeline:
ForEach and ForEachOrdered
A possible use case of a stream could be to update a property of some, or all, elements or why not just print them out for debugging purposes. In either way, we are not interested in collecting or counting the output, but rather by generating a side-effect without returning value.
This is the purpose offorEach() orforEachOrdered(). They both take aConsumer and terminates the Stream without returning anything. The difference between these operations simply being thatforEachOrdered() promises to invoke the provided Consumer in the order the elements appear in the Stream whereasforEach() only promises to invoke the Consumer but in any order. The latter variant is useful for parallel Streams.
In the simple case below, we print out every element of the Stream in one single line.
1 2 3 4 | Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", “Lion”) .forEachOrdered(System.out::print); |
This will produce the following output:
1 | MonkeyLionGiraffeLemurLion |
1 | <br> |
Collecting Elements
A common usage of Streams is to build a “bucket” of the elements or more specifically, to build data structures containing a specific collection of elements. This can be accomplished by calling the terminal operationcollect() at the end of the Stream thus asking it to collect the elements into a given data structure. We can provide something called aCollector to thecollect() operation and there are a number of different predefined types that can be used depending on the problem at hand. Here are some very useful options:
Collect to Set
We can collect all elements into aSet simply by collecting the elements of the Stream with the collectortoSet().
1 2 3 4 | Set<String> collectToSet = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.toSet()); |
1 | toSet: [Monkey, Lion, Giraffe, Lemur] |
Collect to List
Similarly, the elements can be collected into aList usingtoList() collector.
1 2 3 4 | List<String> collectToList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.toList()); |
1 | collectToList: [Monkey, Lion, Giraffe, Lemur, Lion] |
Collect to General Collections
In a more general case, it is possible to collect the elements of the Stream into anyCollection by just providing a constructor to the desiredCollection type. Example of constructors areLinkedList::new,LinkedHashSet::new andPriorityQueue::new
1 2 3 4 | LinkedList<String> collectToCollection = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.toCollection(LinkedList::new)); |
1 | collectToCollection: [Monkey, Lion, Giraffe, Lemur, Lion] |
Collect to Array
Since an Array is a fixed size container rather than a flexibleCollection, there are good reasons to have a special terminal operation,toArray(), to create and store the elements in an Array. Note that just calling toArray() will result in an Array of Objects since the method has no way to create a typed array by itself. Below we show how a constructor of a String array can be used to give a typed array String[].
1 2 3 4 | String[] toArray = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .toArray(String[]::new); |
1 | toArray: [Monkey, Lion, Giraffe, Lemur, Lion] |
Collect to Map
We might want to extract information from the elements and provide the result as a Map. To do that, we use the collector toMap() which takes twoFunctions corresponding to a key-mapper and a value-mapper.
The example shows how different animals can be related to the number of distinct characters in their names. We use the intermediate operation distinct() to assure that we only add unique keys in the Map (If the keys are not distinct, we have to provide a variant of the toMap() collector where a resolver must be provided that is used to merge results from keys that are equal).
1 2 3 4 5 6 7 8 | Map<String, Integer> toMap = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .distinct() .collect(Collectors.toMap( Function.identity(), //Function<String, K> keyMapper s -> (int) s.chars().distinct().count()// Function<String, V> valueMapper )); |
1 | toMap: {Monkey=6, Lion=4, Lemur=5, Giraffe=6} (*) |
(*) Note that the key order is undefined.
Collect GroupingBy
Sticking to the bucket analogy, we can actually handle more than one bucket simultaneously. There is a very useful Collector namedgroupingBy() which divides the elements in different groups depending on some property whereby the property is extracted by something called a “classifier”. The output of such an operation is a Map. Below we demonstrate how the animals are grouped based on the first letter of their name.
1 2 3 4 5 6 | Map<Character, List<String>> groupingByList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.groupingBy( s -> s.charAt(0) // Function<String, K> classifier )); |
1 | groupingByList: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]} |
Collect GroupingBy Using Downstream Collector
In the previous example, a “downstream collector” toList() was applied for the values in the Map by default, collecting the elements of each bucket into a List. There is an overloaded version of groupingBy() that allows the use of a custom “downstream collector” to get better control over the resulting Map. Below is an example of how the special downstream collector counting() is applied to count, rather than collecting, the elements of each bucket.
1 2 3 4 5 6 7 | Map<Character, Long> groupingByCounting = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion") .collect(Collectors.groupingBy( s -> s.charAt(0), // Function<String, K> classifier counting() // Downstream collector )); |
1 | groupingByCounting: {G=1, L=3, M=1} |
Here is an illustration of the process:
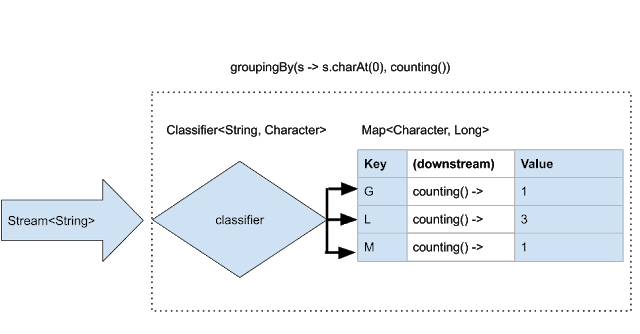
Any collector can be used as a downstream collector. In particular, it is worth noting that a collector groupingBy() can take a downstream collector that is also a groupingBy() collector, allowing secondary grouping of the result of the first grouping-operation. In our animal case, we could perhaps create a Map<Character, Map<Character, Long>> where the first map contains keys with the first character and the secondary maps contain the second character as keys and number of occurrences as values.
Occurrence of Elements
The intermediate operation filter() is a great way to eliminate elements that do not match a given predicate. Although, in some cases, we just want to know if there is at least one element that fulfills the predicate. If so, it is more convenient and efficient to use anyMatch(). Here we look for the occurrence of the number 2:
1 | boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2); |
1 | containsTwo: true |
Operations for Calculation
Several terminal operations output the result of a calculation. The simplest calculation we can perform being count() which can be applied to anyStream. It can, for example, be used to count the number of animals:
1 2 3 4 | long nrOfAnimals = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur") .count(); |
1 | nrOfAnimals: 4 |
Although, some terminal operations are only available for the special Stream implementations that we mentioned in the first article; IntStream,LongStream and DoubleStream. Having access to a Stream of such type we can simply sum all the elements like this:
1 | int sum = IntStream.of(1, 2, 3).sum(); |
1 | sum: 6 |
Or why not compute the average value of the integers with .average():
1 | OptionalDouble average = IntStream.of(1, 2, 3).average(); |
1 | average: OptionalDouble[2.0] |
Or retrieve the maximal value with .max().
1 | int max = IntStream.of(1, 2, 3).max().orElse(0); |
1 | max: 3 |
Like average(), the result of the max() operator is an Optional, hence by stating .orElse(0) we automatically retrieve the value if its present or fall back to 0 as our default. The same solution can be applied to the average-example if we rather deal with a primitive return type.
In case we are interested in all of these statistics, it is quite cumbersome to create several identical streams and apply different terminal operations for each one. Luckily, there is a handy operation called summaryStatistics() which allows several common statistical properties to be combined in aSummaryStatistics object.
1 | IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics(); |
1 | statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3} |
Exercises
Hopefully, you are familiar with the format of the provided exercises at this point. If you just discovered the series or just felt a bit lazy lately (maybe you’ve had your reasons too) we encourage you to clone the GitHub repo and start using the follow-up material. The content of this article is sufficient to solve the third unit which is called MyUnit3Terminal. The corresponding Unit3Terminal Interface contains JavaDocs which describe the intended implementation of the methods in MyUnit3Terminal.
01 02 03 04 05 06 07 08 09 10 11 12 13 | public interface Unit3Terminal { /** * Adds each element in the provided Stream * to the provided Set. * * An input stream of ["A", "B", "C"] and an * empty input Set will modify the input Set * to contain : ["A", "B", "C"] * * @param stream with input elements * @param set to add elements to */void addToSet(Stream stream, Set set); |
1 | <br> |
The provided tests (e.g. Unit3MyTerminalTest) will act as an automatic grading tool, letting you know if your solution was correct or not.
Next Article
The next article will show how all the knowledge we have accumulated so far can be applied to database queries.
Hint: Bye-bye SQL, Hello Streams… Until then – happy coding!
Authors
Per Minborg
Julia Gustafsson
Published on Java Code Geeks with permission by Per Minborg, partner at our JCG program. See the original article here: Become a Master of Java Streams – Part 3: Terminal Operations Opinions expressed by Java Code Geeks contributors are their own. |

Great article! I wish this page has more such articles and not so much spam and buzzing articles