SBE is very fast serialization library which is used in financial industry, in this blog i will go though some of the design choices that are made to make it blazing fast.
Whole purpose of serialization is to encode & decode message and there many options available starting from XML, JSON, Protobufer , Thrift, Avro etc.
XML/JSON are text based encoding/decoding, it is good in most of the case but when latency is important then these text based encoding/decoding become bottleneck.
Protobuffer/Thrift/Avro are binary options and used very widely.
SBE is also binary and was build based on Mechanical sympathy to take advantage of underlying hardware(cpu cache, pre fetcher, access pattern, pipeline instruction etc).
Small history of the CPU & Memory revolution.
Our industry has seen powerful processor from 8 bit, 16 , 32, 64 bit and now normal desktop CPU can execute close to billions of instruction provided programmer is capable to write program to generate that type of load. Memory has also become cheap and it is very easy to get 512 GB server.
Way we program has to change to take advantage all these stuff, data structure & algorithm has to change.
Lets dive inside sbe.
Full stack approach
Most of the system rely on run-time optimization but SBE has taken full stack approach and first level of optimization is done by compiler.
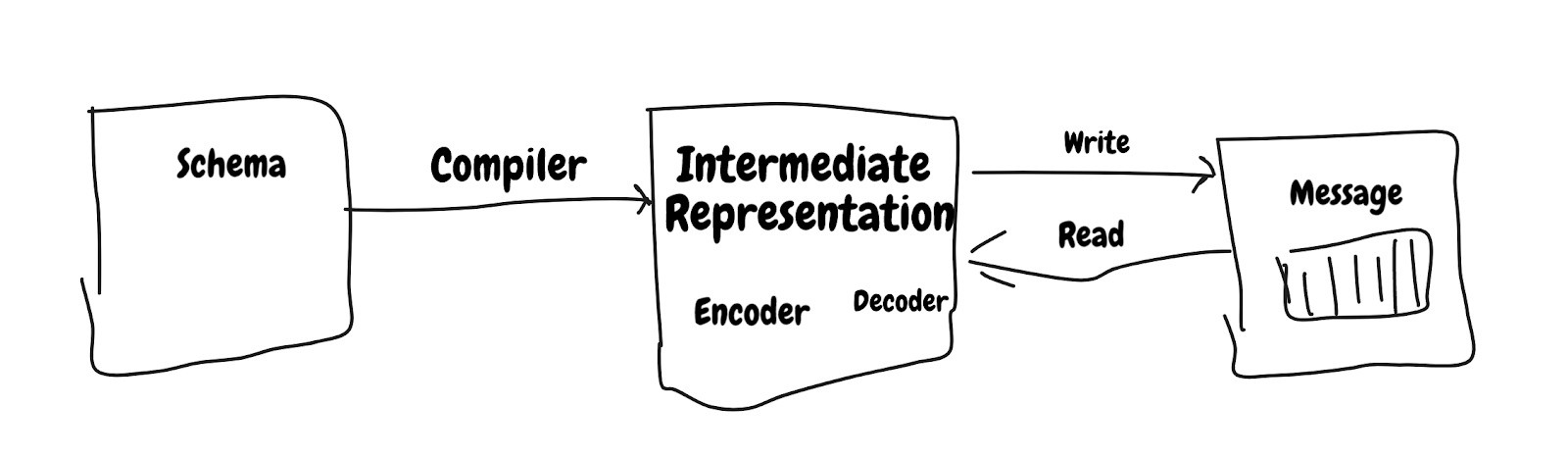
Schema – XML file to define layout & data type of message.
Compiler – Which takes schema as input and generate IR. Lot of magic happen in this layer like using final/constants, optimized code.
Message – Actual message is wrapper over buffer.
Full stack approach allows to do optimization at various level.
No garbage or less garbage
This is very important for low latency system and if it is not taken care then application can’t use CPU caches properly and can get into GC pause.
SBE is build around flyweight pattern, it is all about reuse object to reduce memory pressure on JVM.
It has notion of buffer and that can be reused, encoder/decoder can take buffer as input and work on it. Encoder/Decoder does no allocation or very less(i.e in case of String).
SBE recommends to use direct/offheap buffer to take GC completely out of picture, these buffer can be allocated at thread level and can be used for decoding and encoding of message.
Code snippet for buffer usage.
final ByteBuffer byteBuffer = ByteBuffer.allocateDirect(4096); final UnsafeBuffer directBuffer = new UnsafeBuffer(byteBuffer);
tradeEncoder .tradeId(1)
.customerId(999)
.qty(100)
.symbol("GOOG")
.tradeType(TradeType.Buy);Cache prefetching
CPU has built in hardware based prefetcher. Cache prefetching is a technique used by computer processors to boost execution performance by fetching instructions or data from their original storage in slower memory to a faster local memory before it is actually needed.
Accessing data from fast CPU cache is many orders of magnitude faster than accessing from main memory.
latency-number-that-you-should-know blog post has details on how fast CPU cache can be.
Prefetching works very well if algorithm is streaming and underlying data used is continuous like array. Array access is very fast because it sequential and predictable
SBE is using array as underlying storage and fields are packed in it.
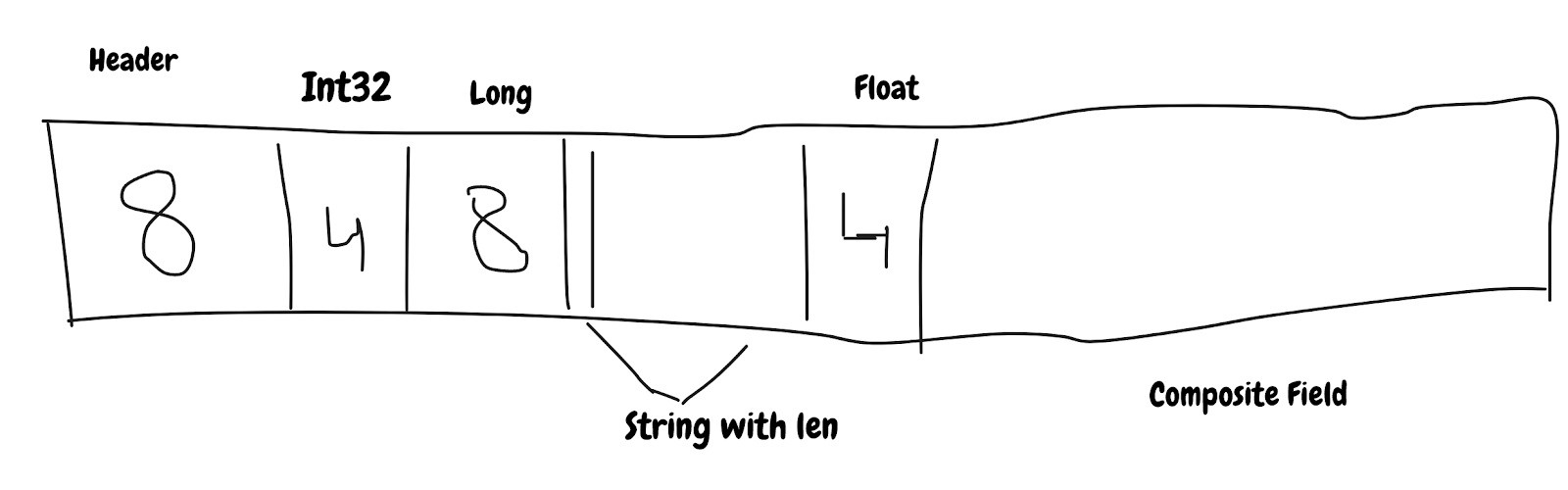
Data moves in small batches of cache line which is usually 8 bytes, so if application asks for 1 byte it will get 8 byte of data. Since data is packed in array so accessing single byte prefetch array content in advance and it will speed up processing.
Think of prefetcher as index in database table. Application will get benefit if reads are based on those indexes.
Streaming access
SBE supports all the primitive types and also allows to define custom types with variable size, this allows to have encoder and decoder to be streaming and sequential. This has nice benefit of reading data from cache line and decoder has to know very little metadata about message(i.e offset and size).
This comes with trade off read order must be based on layout order especially if variable types of data is encoded.
For eg Write is doing using below order
tradeEncoder .tradeId(1)
.customerId(999)
.tradeType(TradeType.Buy)
.qty(100)
.symbol("GOOG")
.exchange("NYSE");For String attributes(symbol & exchange) read order must be first symbol and then exchange, if application swaps order then it will be reading wrong field, another thing read should be only once for variable length attribute because it is streaming access pattern.
Good things comes at cost!
Unsafe API
Array bound check can add overhead but SBE is using unsafe API and that does not have extra bound check overhead.
Use constants on generated code
When compiler generate code, it pre-compute stuff and use constants. One example is field off set is in the generated code, it is not computed.
Code snippet
public static int qtyId()
{
return 2;
}
public static int qtySinceVersion()
{
return 0;
}
public static int qtyEncodingOffset()
{
return 16;
}
public static int qtyEncodingLength()
{
return 8;
}This has trade-off, it is good for performance but not good for flexibility. You can’t change order of field and new fields must be added at end.
Another good thing about constants is they are only in generated code they are not in the message to it is very efficient.
Branch free code
Each core has multiple ports to do things parallel and there are few instruction that choke like branches, mod, divide. SBE compiler generates code that is free from these expensive instruction and it has basic pointer bumping math.
Code that is free from expensive instruction is very fast and will take advantage of all the ports of core.
Sample code for java serialization
public void writeFloat(float v) throws IOException {
if (pos + 4 <= MAX_BLOCK_SIZE) {
Bits.putFloat(buf, pos, v); pos += 4; } else {
dout.writeFloat(v); }
}
public void writeLong(long v) throws IOException {
if (pos + 8 <= MAX_BLOCK_SIZE) {
Bits.putLong(buf, pos, v); pos += 8; } else {
dout.writeLong(v); }
}
public void writeDouble(double v) throws IOException {
if (pos + 8 <= MAX_BLOCK_SIZE) {
Bits.putDouble(buf, pos, v); pos += 8; } else {
dout.writeDouble(v); }
}
Sample code for SBE
public TradeEncoder customerId(final long value)
{
buffer.putLong(offset + 8, value, java.nio.ByteOrder.LITTLE_ENDIAN); return this;}public TradeEncoder tradeId(final long value)
{
buffer.putLong(offset + 0, value, java.nio.ByteOrder.LITTLE_ENDIAN); return this;}Some numbers on message size.
Type class marshal.SerializableMarshal -> size 267
Type class marshal.ExternalizableMarshal -> size 75
Type class marshal.SBEMarshall -> size 49
SBE is most compact and very fast, authors of SBE claims it is around 20 to 50X times faster than google proto buffer.
SBE code is available @simple-binary-encoding
Sample code used in blog is available @sbeplayground
| Published on Java Code Geeks with permission by Ashkrit Sharma, partner at our JCG program. See the original article here: Inside Simple Binary Encoding (SBE) Opinions expressed by Java Code Geeks contributors are their own. |
