A few months ago, somebody in the office pointed us to an interesting job offer from CartoDB which looked as follows:
What follows is a technical test for this job offer at CARTO: https://boards.greenhouse.io/cartodb/jobs/705852#.WSvORxOGPUI
Build the following and make it run as fast as you possibly can using Python 3 (vanilla). The faster it runs, the more you will impress us!
Your code should:
- Download this 2.2GB file: https://s3.amazonaws.com/carto-1000x/data/yellow_tripdata_2016-01.csv
- Count the lines in the file
- Calculate the average value of the tip_amount field.
All of that in the most efficient way you can come up with.
That’s it. Make it fly!
Remember to apply here!: https://boards.greenhouse.io/cartodb/jobs/705852#.WSvORxOGPUI
After reading that through I remember thinking “man, this is a nice excuse to dig into Clojure’s core.async” …..and the sooner said than done, that’s what I was doing a few days alter. Here my notes on that experience.
Where to start?
I already was familiar with the theory behind core.async (I’m talking about Communicating Sequential Processes or just CSP) but when it was time to setup my project and begin laying out my solution I found out that the documentation was between scarce & discouraging. That being said, the unexpected setback did not stop me:
- I watched all Timothy Baldridge videos on the topic. Mandatory watch.
- Rich Hickey internals talk is great too.
- Learning how to combine transducers with channel is something you won’t regret.
- This one is a little bit low level but helps to understand certain corner cases or even error messages you might get.
- Playing around with some real-life examples available in the wilderness of the Internet also helps, always relying on the official API reference
All of that plus a few hours of frustration helped to finally see the light at the end of the tunnel. Now it was time for some coding of my own.
non-blocking file reading
So, first thing I wanted to start with was reading all lines from a file in an non-blocking fashion, and this very goal took me to the following implementation:
(defn stream-lines-from [path]
(let
(go
(with-open [rdr (io/reader path)]
(doseq [line (line-seq rdr)]
(>! c line)))
(close! c))
c))Let me break it down for you:
- I start by defining a channel c with a buffer size of 1024. The size is optional but I thought it was a good idea to buffer lines to avoid blocking the consuming thread as much as possible.
- Then, we’ve got a go-block – the corner stone of the library. It mainly allows to asynchronously execute a body while returning immediately to the calling thread. In this particular block, we will do as follows:
- It begins reading the lines from a source file
- Every line gets pushed to the a channel using the >! operator.
- When the end of the file is reached, the channel gets closed with the close! operator.
- Finally, with our go-block defined, we return the channel for further consumption.
Counting lines
I’m not sure how all of you like to address a problem, but personally, I always start by solving the tiniest of them all and begin building the solution from there – one problem at a time. In this particular case, I conceived a simple functionality where, by given a channel of lines, I can count them all until it gets closed. And that’s what I did:
(defn w-counter [channel]
(go-loop [total 0]
(if-some [_ (<! channel)]
(recur (inc total))
total)))As usual, there’re a couple of new constructions here:
- The go-loop block allows us to execution a loop within a go block. It’s the same as doing (go (loop….)). Also, as a reminder, a go-block returns a channel to the caller that will receive the result of the body (in this particular scenario, the total count of lines).
- The <! operator is the way we’ve got to read a value out of a channel, if available, or it will park the thread otherwise. It’s worth mentioning that, whenever a channel is closed, it will return nil, causing the counting to resume.
As you can see, by doing some recursion, I keep consuming & counting the lines out of the channel until it gets closed (if-some doing the job smoothly), returning the final count to the caller. Now, with that in place, the next thing I wanted to achieve was to perform the count operation but concurrently while somehow controlling the amount of counters doing the job. So, after some REPL driven development, this is what I’ve got:
(defn count-lines [channel npar]
(let [counters (for [_ (range npar)]
(w-counter channel))]
(async/reduce + 0 (async/merge counters))))And this was the moment when things started to click in my mind. By simply doing a for-comprehension using my previous w-counter function along with an async merge & reduce combination it finally did the trick in just a 3 goddam lines of code. So, what are these two combinators?
- async/merge allowed me to take all values from all channels and return a single channel containing all of them. This was handy to collect all partial results from all of my workers.
- async/reduce was the cherry on top since it allowed me to combine all partial counts into the final results, in this particular case, the total count.
You could represent the flow as something like this:
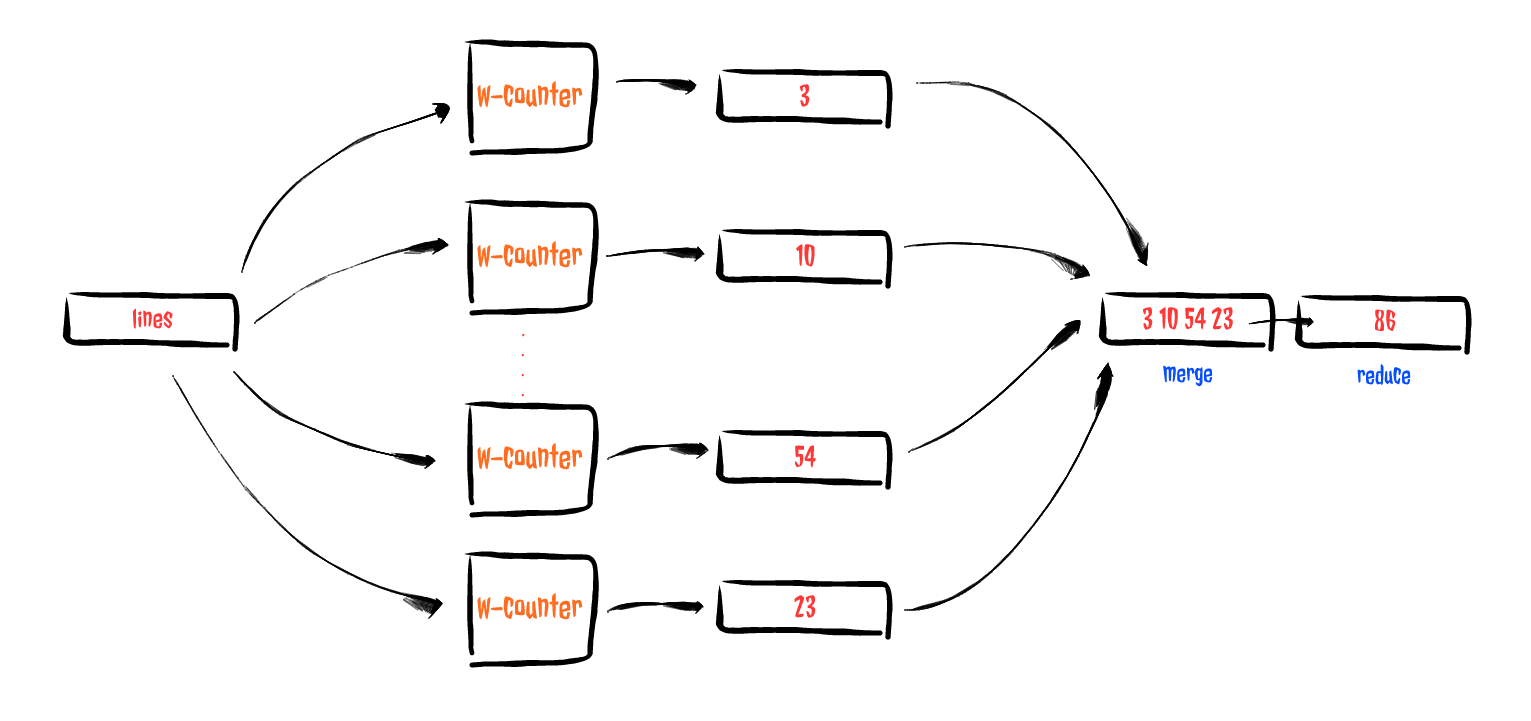
Nifty!
Tricky tricky aggregation
With the count lines in my pocket, it was time to tackle the aggregation part, but, in order to understand why I did what I did, let’s start by checking on the source file structure.
VendorID,tpep_pickup_datetime,tpep_dropoff_datetime,passenger_count,trip_distance,pickup_longitude,pickup_latitude,RatecodeID,store_and_fwd_flag,dropoff_longitude,dropoff_latitude,payment_type,fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,total_amount 2,2016-01-01 00:00:00,2016-01-01 00:00:00,2,1.10,-73.990371704101563,40.734695434570313,1,N,-73.981842041015625,40.732406616210937,2,7.5,0.5,0.5,0,0,0.3,8.8 2,2016-01-01 00:00:00,2016-01-01 00:00:00,5,4.90,-73.980781555175781,40.729911804199219,1,N,-73.944473266601563,40.716678619384766,1,18,0.5,0.5,0,0,0.3,19.3 2,2016-01-01 00:00:00,2016-01-01 00:00:00,1,10.54,-73.984550476074219,40.6795654296875,1,N,-73.950271606445313,40.788925170898438,1,33,0.5,0.5,0,0,0.3,34.3 2,2016-01-01 00:00:00,2016-01-01 00:00:00,1,4.75,-73.99346923828125,40.718990325927734,1,N,-73.962242126464844,40.657333374023437,2,16.5,0,0.5,0,0,0.3,17.3
It’s easy to see that the first line will always include the headers while the rest of the file will all be composed by values in CSV format. Now, if you remember the exercise, it requested us to aggregate tip_amount field but, according to this, we should first find out what index must be used to locate the value to be aggregated.
True to myself, I started with a simple solution to a tiny problem, so I came up with the idea of, by reading the first value of the channel (which is the same as the headers) I can define a function capable of extracting out the value I’m looking for every time a provide a line as input, and this is what I’ve got:
(defn extract-field-fn [fname channel]
(let [headers (<!! channel)
field-idx (->> (split headers #",")
(map-indexed vector)
(filter (fn [[_ v]] (= v fname)))
first
first)]
#(java.lang.Double/parseDouble (nth (split % #",") field-idx))))It starts by waiting for the first value from the channel (remember, it is mandatory that we infer the index before doing any aggregation) and that’s why I’ve used <!! to block until a value is available. Then, with the first line handy, I split it up to search later on the position in which the field with name fname was located, and finally return a partial function that can extract & parse the requested field on demand.
With that in place, the next problem to be solved was how to calculate the average of a sequence of values coming from a channel. By this time, I’d learnt a few very important lessons that paved my path to the following implementation:
(defn w-aggregate [channel]
(go-loop
(if-some [n (<! channel)]
(recur (inc c) (+ n s))
[s c])))I hope you can see that I followed a similar implementation as I did to count lines, but this time, I had to sum and count each value until the channel gets closed. Easy peace.
Finally, with this two small functions in place, I was capable of building my asynchronous solution to the field average problem, which looks as follows:
(defn aggregate-field [fname channel npar]
(let [as-value-fn (extract-field-fn fname channel)
fvalue-chan (pipe channel (chan 1024 (map as-value-fn)))
fvalue-aggregator (for [_ (range npar)]
(w-aggregate fvalue-chan))]
(go
(let [[sum count] (<! (async/reduce
#(apply map + [%1 %2])
[0.0 0]
(async/merge fvalue-aggregator)))]
(/ sum count)))))This is more or less what’s going on:
- We start by creating a partial function that, by a field name and a channel, it defines a function that reads the field value out of a line.
- Next thing we do is to pipe the incoming lines-channel to a field-value-channel…..why I did such thing?….because channels support transducers!!! Here, I define a transducer capable of mapping a line into the value that needs to be aggregated (map as-value-fn) and I use it to define a new channel that emits all values that need to be aggregated. That felt real good.
- Using the transduced channel fvalue-chan along with a for-comprehension using w-aggregate function, all I had to do was to count & sum the incoming values concurrently.
- Finally, by combining reduce & merge calls for the same purpose, I collect the partial counts & sums to finally calculate the average of the requested value by simply dividing them.
You might depict the flow as follows:
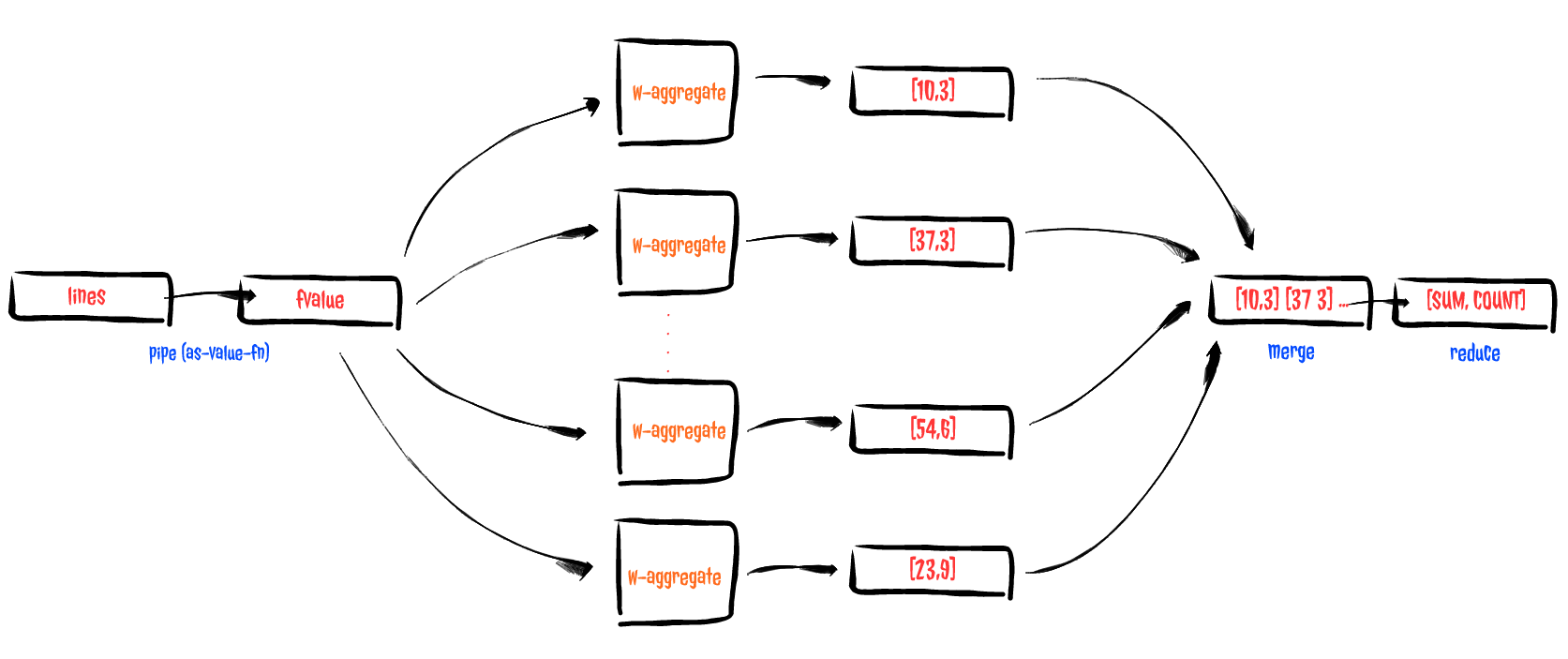
DOING IT ALL CONCuRRENTLY
With both count lines and field average value problem solved, how can I put them all to work together? And that’s when the API reference played an important role in the story since I happened to find the mult operator. According to the documentation..
Creates and returns a mult(iple) of the supplied channel. Channels containing copies of the channel can be created with ‘tap’, and detached with ‘untap’.
and it clicked … again …. so I tried this
(defn process! [path fname npar]
(let [lines (mult (stream-lines-from path))
aggregate-tap (tap lines (chan 1024))
count-tap (tap lines (chan 1024))]
(<!! (async/reduce
(fn [_ v] (println v))
""
(async/merge [(aggregate-field fname aggregate-tap npar)
(count-lines count-tap npar)])))))And it worked!!. Let’s see what we’ve got here:
- Remember the stream-lines-from function? This is the place you make use of it, we specify the source file path and get back a channel where all lines will get published, but since we need to consume those lines twice (for counting and average) we declare that channel as mult.
- Then, we tap the lines channel twice: once for the counting flow and another for the average flow. By using tap, we can copy the mult source channel onto the supplied channel and, by doing so, we can submit each line to the counting & average flows with no effort, leveraging concurrency!
- Finally, we pass in each of the tap channel to the aggregate-field & count-lines functions and wait for them all to finish by a blocking (<!! operator) merge/reduce.
Final Thoughts
Did it fly? Not really: counting was kind of “fast” (it took around a minute in my laptop) but aggregating values was slower than expected (around 5 minutes). To be fair, there’re a lot of factors here to take into account too: my laptop is kind of old, I did not invest enough time to dig into more details about the internals, just name a few, but it was also extremely hard to find information about performance recommendation from the community, and that, to me, is an important handicap to keep it mind when you consider adopting a new stack. Community is key.
Overall, I dare to say that it was a fun ride, it made me happy to see that the JVM is still a wonderful piece of software with lots of capabilities and that Clojure can still preserve that beauty in Concurrent Land but I would still lean towards other solutions rather than using core.async for high performance system, I did not get that gut feeling that I’ve got while using Akka or Rx, at least for the moment.
Can you make it faster? Ping me! Don’t let this chance slip by, you can get schwifty with Clojure NOW!

| Published on Java Code Geeks with permission by Guillermo Szeliga, partner at our JCG program. See the original article here: GETTIN’ SCHWIFTY WITH CLOJURE’S CORE.ASYNC Opinions expressed by Java Code Geeks contributors are their own. |

Hi. You have wrong solution for this case.
First rule – No I/O in go block. When you put I/O in go block you make all other go blocks for starvation and its slow down you program. Use async/thread instead for I/O.
It is better to user reducers for this task with ForkJoinPool under the hood.
https://github.com/clojure-cookbook/clojure-cookbook/blob/master/04_local-io/4-13_parallelizing-file-processing-using-iota.asciidoc