The package is a fundamental concept in Java and one of the first things you stumble upon when starting programming in the language. As a beginner you probably don’t pay much attention to the structure of packages, but as you become a more experienced and mature software developer, you start to think what can be done to improve their efficiency. There are a few major options to consider and picking the right one might not be an obvious choice. This article should give you an overview of commonly selected strategies.
Why do we use packages?
From the language perspective, packages in Java provide two important features, which are utilized by the compiler. The most apparent one is the namespace definition for classes. Several classes with an exactly the same name can be used in a single project as long as they belong to different packages which distinguish one class from another. If you can’t imagine how the language would look like if there were no packages, just have a look at the modularization strategies in the JavaScript world. Before ES2015 there were no official standards and a naming collision wasn’t a rare case.
The second thing is that packages allow defining access modifiers for particular members of a project. Accessibility of a class, an interface, or one of their members like fields and methods can be limited or completely prohibited for members of different packages.
Both features are first of all used by the compile to enforce language rules. For clean coders and software craftsmen the primary property of a package is possibility to have a meaningful name which describes its purpose and the reason for existence. For compilers, it’s just a random string of chars while for us, it’s another way to express our intention.
What is a package?
In the official Java tutorial we can find the definition which begins like this:
A package is a namespace that organizes a set of related classes and interfaces. Conceptually you can think of packages as being similar to different folders on your computer. You might keep HTML pages in one folder, images in another, and scripts or applications in yet another. (…)
The first sentence emphasizes the organization purpose of packages. The definition doesn’t explain, though, what kind of a relationship classes and interfaces should have to consider them as a single group. The question is open to all software developers. Recently, Kent Beck wrote a general piece of advice which also applies to the topic discussed in this post:
if you're ever stuck wondering what to clean up, move similar elements closer together and move different elements further apart
— Kent Beck 🌻 (@KentBeck) June 26, 2017
Yet, just like the word “related” in the aforementioned package definition, the word “similar” can have completely different meaning to different people. In the remaining part of the article we will consider possible options in the context of package organization.
Package by layer
Probably the most commonly recognized similarity between project classes is their responsibility. The approach which uses this property for organization is known as package by layer or horizontal slice and in practice looks more or less like on the picture below.
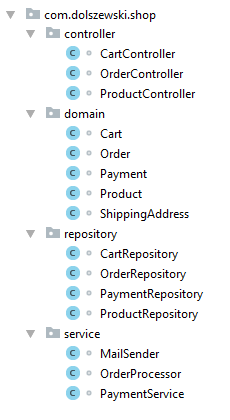
If you didn’t have a chance to work on a project with such structure, you could come across it in some framework tutorials. For instance, Play framework recommended such approach up to version 2.2. The tutorial of Angular.js initially suggested keeping things together based on their responsibilities.

The fact they changed their opinions about the subject and updated tutorials should probably excite you to think what was the reason. But before we judge the solution, let’s look at its strengths and weaknesses.
Pros
Considering layered architecture as the most widely used, it shouldn’t be surprising that developers aim to reflect the chosen architecture in the package structure. The long prevalence of the approach influences the decision to apply the structure in new projects because it’s easier for team’s newcomers to adopt in the environment which is familiar to them.
Finding a right place for a new class in such application is actually a no-brainer operation. The structure is created at the beginning of development and kept untouched during the entire project’s existence. The simplicity allows keeping the project in order even by less experienced developers as the structure is easily understandable.
Cons
Some people say having all model classes in one place makes them easier to reuse because they can simply be copied with the whole package to another project. But is it really the case? The shape of a particular domain model is usually valid only in a bounded context within a project. For instance, the product class will have different properties in a shopping application than in an application which manages orders from manufactures. And even if you would like to use the same classes, it would be reasonable to extract them to a separate jar marked as a dependency in each application. Duplication of code leads to bugs even if it exists in separate but related projects, hence we should avoid copy-pasting.
A major disadvantage of the package by layer approach is overuse of the public access modifier. Modern IDEs create classes and methods with the public modifier by default without forcing a developer to consider a better fitting option. In fact, in the layered package organization there is no other choice. Exposing a repository just to a single service class requires the repository to be public. As a side effect the repository is accessible to all other classes in the project, even from layers which shouldn’t directly communicate with it. Such approach encourages creating an unmaintainable spaghetti code and results in high coupling between packages.
While jumping between connected classes in IDEs is nowadays rather simple no matter where they are located, adding a new set of classes for a new feature required more attention. It is also harder to assess the complexity of a feature just by looking at code as classes are spread across multiple directories.
At the beginning, we said that the name of a package should provide additional details about its content. In the package by layer approach, all packages describe the architecture of the solution, but separately they don’t give any useful information. Actually, in many cases, they duplicate information present in class names of its members.
Package by feature
On the other side of the coin you can structure your classes around features or domain models. You might have heard of this approach as the vertical slice organization. If you work only with the horizontal slice, at the first glance it might look a little bit messy, but in the end it’s just a question of mindset. The following picture represents the same classes as in the previous paragraph, but with a different package layout.
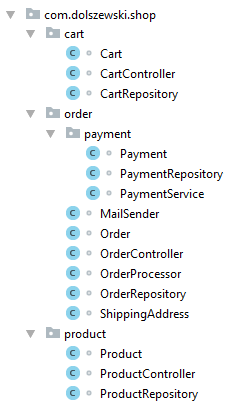
You probably don’t keep all your left shoes in one place and all right in another just because they fit the same feet. You keep your shoes in pairs because that’s the way you use them. By the same token, you can look at the classes in your project.

The core idea of the vertical slice is to place all classes which build a particular feature in a single package. By following this rule, in return you will receive some benefits, but also face some negative consequences.
Pros
When all feature classes are in a single package, the public access modifier is much more expressive as it allows describing what part of a feature should be accessible by other parts of the application. Within a package you should favor usage of the package-private modifier to improve modularization. It’s a good idea to modify default templates in your IDE to avoid creating public classes and methods. Making something public should be a conscious decision. Fewer connections between classes from different packages will lead to cleaner and a more maintainable code base.
In the horizontal slice, packages have the same set of names in each project while in the vertical slice approach packages have much more meaningful names, which describe their functional purpose. Just by looking at project structure, you can probably guess what users can do with the application. The approach also expresses hierarchical connections between features. Aggregate roots of the domain can be easily identified as they exist at the lowest level of the package tree. Package structure documents the application.
Grouping classes based on features results in smaller and easier to navigate packages. In horizontal approach each new feature increases the total number of classes in layer packages and makes them harder to browse. Finding interesting elements on the long list of classes becomes an inefficient activity. By contrast, a package focused on a feature grows only if that feature is extended. A new feature receives its own package in an appropriate node of the tree.
It’s also worth to mention the flexibility of the vertical slice packaging. With the growing popularity of the microservice architecture, having a monolith application which is already sliced by features is definitely much easier to convert into separate services than a project which organizes classes by layers. Adopting the package by feature approach prepares your application for scalable growth.
Cons
Along with the development of the project, the structure of packages requires more care. It’s important to understand that the package tree evolves over time as the application gets more complex. From time to time you will have to stop for a while and consider moving a package to a different node or to split it into smaller ones. The clarity of the structure doesn’t come for free. The team is responsible for keeping it a good shape with alignment to knowledge about the domain.
Understanding the domain is the key element of clean project structure. Choosing a right place for a new feature may be problematic, especially for team newcomers as it requires knowledge about the business behind your application. Some people may consider this as an advantage as the approach encourages sharing knowledge among team members. Introduction of a new developer to the project is slightly more time consuming, yet it might be seen as an investment.
Mixed approach
You may think that no extremity is good. Can’t we just take what is best from both approaches and create a new quality that is intermediate between two extremes? There are two possible combinations. Either the first level of packages is divided by a layer and features are their children or features build the top level and layers are they sub nodes.

The first option is something that you might have encountered as it is a common solution for packages which grow to large sizes. It increases clarity of the structure, but unfortunately all disadvantages of the package by layer approach apply just like before. The greatest problem is that the public modifier must still be used almost everywhere in order to connect your classes and interfaces.
With the other option we should ask a question whether the solution really makes much sense. The package by feature approach supports organization of layers, but it does it on the class level and not using packages. By introducing additional levels of packages we lose the ability to leverage default access modifier. We also don’t gain much simplicity in the structure. If a feature package grows to unmanageable size, it’s probably better to extract a sub feature.
Summary
Picking the package structure is one of the first choices you have to make when starting a new project. The decision has an impact on future maintainability of the whole solution. Although in the theory you can change the approach at any point in time, usually the overall cost of such shift simply prevents it from happening. That is why it’s particularly important to spend a few minutes with your whole team at the beginning and compare possible options. Once you make a choice all you have to do is to make sure that every developer follows the same strategy. It might be harder for the package by feature approach, especially if done for the first time, but the list of benefits is definitely worth the effort.
If you have any experience with the vertical slice and would like to add your two cents to the topic, don’t hesitate to share your thoughts in the comments. Also please consider sharing the post with your colleagues. It would be great to read the outcome of your discussions and feelings about the approach.
| Reference: | Project Package Organization from our JCG partner Daniel Olszewski at the Daniel Olszewski about coding blog. |
