This article is part of our Academy Course titled Elasticsearch Tutorial for Java Developers.
In this course, we provide a series of tutorials so that you can develop your own Elasticsearch based applications. We cover a wide range of topics, from installation and operations, to Java API Integration and reporting. With our straightforward tutorials, you will be able to get your own projects up and running in minimum time. Check it out here!
1. Introduction
In this last part of the tutorial we are going to look around and learn how perfectly Elasticsearch fits into Java ecosystem and inspires many interesting projects. One of the best ways to illustrate that is to take a look at the marriage of Elasticsearch and Hibernate framework, an exceptionally beloved choice among Java developers for managing the persistence layer.
Table Of Contents
Additionally, at the very end we are going to glance through a tremendously popular suite of the applications, known as Elastic Stack, and what you could do with it. Although it goes well beyond Java applications only, it is hard to overestimate the value it offers to modern, highly distributed software systems.
2. Elasticsearch for Hibernate Users
It is practically impossible to find any Java developer out there who has not heard about the Hibernate framework. On the other hand, not so many developers know that there are quite a few projects hidden under the Hibernate umbrella and one of them is a real gem called Hibernate Search.
Hibernate Search transparently indexes your objects and offers fast regular, full-text and geolocation search. Ease of use and easy clustering are core. – http://hibernate.org/search/
Hibernate Search has started as a simple glue layer between Hibernate and Apache Lucene and used to offer a very limited set of supported backends to manage search indices. But the situation is changing for the better with a just recently released final version of the Hibernate Search 5.7.0 along with full-fledged Elasticsearch support (while still bearing an experimental label). What it practically means is that if your persistence layer is managed by Hibernate, then by plugging in Hibernate Search you could enrich your data model with full-text search capabilities, all that backed by Elasticsearch. Sounds exciting, right?
To get a feeling of how things work under the hood, let us take a look at our catalog data model expressed in terms of JPA entities decorated with Hibernate Search annotations, starting with the Book class.
@Entity
@Table(name = "BOOKS")
@Indexed(index = "catalog")
public class Book {
@Id
@Field(name = "isbn", analyze = Analyze.NO)
private String id;
@Field
@Column(name = "TITLE", nullable = false)
private String title;
@IndexedEmbedded(depth = 1)
@ElementCollection
private Set categories = new HashSet<>();
@Field(analyze = Analyze.NO)
@Column(name = "PUBLISHER", nullable = false)
private String publisher;
@Field
@Column(name = "DESCRIPTION", nullable = false, length = 4096)
private String description;
@Field(name = "published_date", analyze = Analyze.NO)
@Column(name = "PUBLISHED_DATE", nullable = false)
@DateBridge(resolution = Resolution.DAY)
private LocalDate publishedDate;
@NumericField @Field(name = "rating")
@Column(name = "RATING", nullable = false)
private int rating;
@IndexedEmbedded
@ManyToMany
private Set authors = new HashSet();
}
For seasoned Java developers it is a familiar piece of code to describe persistent entities, with only a couple of Hibernate Search annotations (like @Field, @DateBridge, @IndexedEmbedded) added on top. We are not going to discuss them here unfortunately, this topic itself is worth of a complete tutorial but please do not hesitate to refer to the official documentation for more details. With that being said, we just move on to the Category class.
@Embeddable
public class Category {
@Field(analyze = Analyze.NO)
@Column(name = "NAME", nullable = false)
private String name;
}
Followed by the Author class right after.
@Entity
@Indexed(index = "catalog")
@Table(name = "AUTHORS")
public class Author {
@Id
private String id;
@Field(name = "first_name", analyze = Analyze.NO)
@Column(name = "FIRST_NAME", nullable = false)
private String firstName;
@Field(name = "last_name", analyze = Analyze.NO)
@Column(name = "LAST_NAME", nullable = false)
private String lastName;
}
Thanks to Spring Framework, and particularly to Spring Boot magic, the configuration of the Hibernate and Hibernate Search pointing to Elasticsearch as the search backend is as easy as adding a couple of lines to application.yml file.
spring:
jpa:
properties:
hibernate:
search:
default:
indexmanager: elasticsearch
elasticsearch:
host: http://localhost:9200
Frankly speaking, you may need to tailor this configuration quite a bit to fit the needs of your applications, to our luck the official documentation covers this part pretty well. Every time the instances of the Book or Author classes are created, modified or deleted, the Hibernate Search takes care of keeping Elasticsearch index in sync, it is completely transparent.
How the search looks like? Well, Hibernate Search does provide its own Query DSL abstraction layer, based on Apache Lucene queries (at the same time leaving a route to use some native Elasticsearch features), for example:
@Autowired private EntityManager entityManager;
final FullTextEntityManager fullTextEntityManager = Search
.getFullTextEntityManager(entityManager);
final QueryBuilder qb = fullTextEntityManager
.getSearchFactory()
.buildQueryBuilder()
.forEntity(Book.class)
.get();
final FullTextQuery query = fullTextEntityManager
.createFullTextQuery(
qb.bool()
.must(
qb.keyword()
.onField("categories.name")
.matching("analytics")
.createQuery()
)
.must(
qb.keyword()
.onField("authors.last_name")
.matching("Tong")
.createQuery()
).createQuery(), Book.class);
final List books = query.getResultList();
...
There are definitely a lot of similarities to Elasticsearch’s own Query DSL so this code snippet should look already familiar to you. But before you get too excited, there are several limitations related to Hibernate Search and Elasticsearch integration. First of all, the latest version of Elasticsearch which is supported by Hibernate Search at the moment is 2.4.4. Not bad but quite far from the current 5.x release branch, hopefully this is going to be addressed soon. Secondly, indeed, the subset of the Elasticsearch features exposed over the Hibernate Search APIs, in particular Query DSL, is quite limited but frankly speaking, might be enough for many applications.
Anyway, why we are mentioning Hibernate Search in the first place? Simple, if your applications are built on top of Hibernate persistence, using Hibernate Search is probably the fastest and cheapest way to benefit from full-text search capabilities for your data models, leveraging Elasticsearch behind the curtain.
3. Elastic Stack: Get It All
If you already run into mysterious ELK abbreviation and were curious what it means than this section would help you to find the answers. ELK is essentially a bundle of products, consisting of (E)lasticsearch, (L)ogstash and (K)ibana, therefore just ELK in short. Recently, with the addition of the Beats, a new member of this awesome family, the ELK is often referred as Elastic Stack now.
Undoubtedly, Elasticsearch is the heart and soul of ELK so let us talk about what those other products are and why they are useful.
Kibana lets you visualize your Elasticsearch data and navigate the Elastic Stack, so you can do anything from learning why you’re getting paged at 2:00 a.m. to understanding the impact rain might have on your quarterly numbers. – https://www.elastic.co/products/kibana
Basically, Kibana is just a web application which is capable of creating powerful charts and dashboards based on the data you are having indexed in Elasticsearch.
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite “stash”, f.e. Elasticsearch – https://www.elastic.co/products/logstash
Consequently, Logstash is a terrific tool, capable of extracting, massaging and feeding the data to Elasticsearch (and a myriad of other sources) which could be visualized using Kibana later on. The Beats are quite close to Logstash but are not yet so powerful.

One of the areas where Elastic Stack is exceptionally useful and leads the race is collecting and analyzing the massive amounts of application logs. It may sound not very convincing, why would you need such a complex system in order to tail/grep over a log file? But at scale, when you deal with hundreds or even thousands of the applications (think microservices), the benefits become very obvious: you suddenly have a centralized places where the logs from all the applications are streamed into and could be searched against, analyzed, correlated and visualized.
Without any further talks, let us demonstrate how a typical Spring Boot application could be configured to send its logs to Logstash, which is going to forward them to Elasticsearch as-is, without transformations applied. First, we need Logstash to be installed, either as Docker container or just running on local machine, the official documentation presents the installation steps exceptionally well.
The only thing we need to tell to Logstash is where to get logs from (using input plugins) and where to send the massaged logs to (using output plugins), all that through logstash.conf configuration file.
input {
tcp {
port => 7760
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
The number of input and output plugins supported by Logstash is astonishing. To keep the example very simple, we are going to deliver the logs over the TCP socket input plugin and forward straight to Elasticsearch using Elasticsearch output plugin.
It looks great, but how we could send the logs from our Java applications to Logstash? There are many ways to do that and the easiest one is probably by leveraging the capabilities of your logging framework. Most of the Java applications these days rely on the awesome Logback framework and the community has implemented dedicated Logback encoder to be used along with Logstash.
You just have to include an additional dependency into your project, like we do here, for example, using Apache Maven:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.9</version>
</dependency>
And then add the Logstash appender into your logback.xml configuration file. To be noted, there are several appenders available, the one we are interested in is LogstashTcpSocketAppender which talks to Logstash over TCP socket. Please notice that the port under destination tag should match to your Logstash input plugin configuration, in our case it is 7760.
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:7760</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
By and large, this is all we have to do! The logs will be shipped from our application to Elasticsearch and we could explore them using Kibana dashboards. When you download and run Kibana on your local machine, the web UI by default is available at http://localhost:5601:

Easy, simple, powerful … the Elasticsearch way. The only thing to remember is that you should better use the same versions of Elasticsearch , Logstash and Kibana. As we have been using Elasticsearch 5.2.0 along this tutorial, Logstash and Kibana should also be of 5.2.0 release.
If you already using Elasticsearch or are planning to do so, Elastic Stack just opens a whole universe of interesting opportunities for you to discover and benefit from. Moreover, it is being constantly improved and enhanced with new features added every single release.

4. Supercharge Elasticsearch with Plugins
Elasticsearch is wonderful but often command line tools or even Java APIs are not the best way to communicate with your clusters. Luckily, Elasticsearch has extensibility built-in from the early days in a form of plugins.
There are many plugins and accompanying tools available at the moment, but it is worth to talk about three of them:
- elasticsearch-head: a web front end for an Elasticsearch cluster
- elasticsearch-HQ: monitoring, management, and querying web interface for Elasticsearch
- search-guard: security for Elasticsearch
The elasticsearch-head is, essentially, a full-fledged web interface to Elasticsearch. Not only you have nice visual representations of indices and shards, you can also browse the documents, play with search queries and navigate through the results easily.
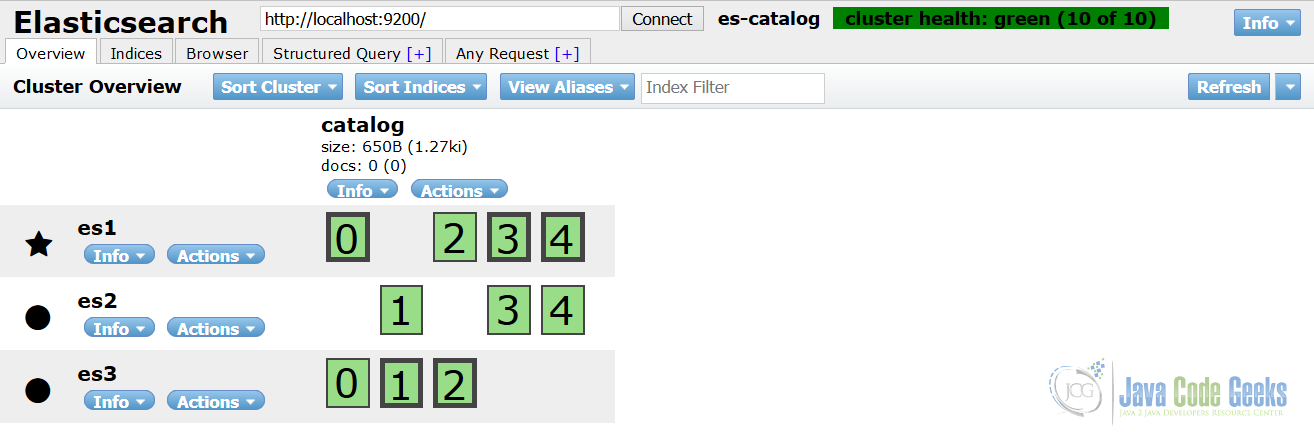
The ability to run structured or arbitrary queries is very helpful, specifically if your query returns a lot of results and you need a convenient way to go through all of them.
Another very interesting one is elasticsearch-HQ which basically put the focus on exposing operational information about Elasticsearch clusters and nodes. Unfortunately, as of moment of this writing, the elasticsearch-HQ does not support 5.x release branch of Elasticsearch but the work to make it happen has already begun.
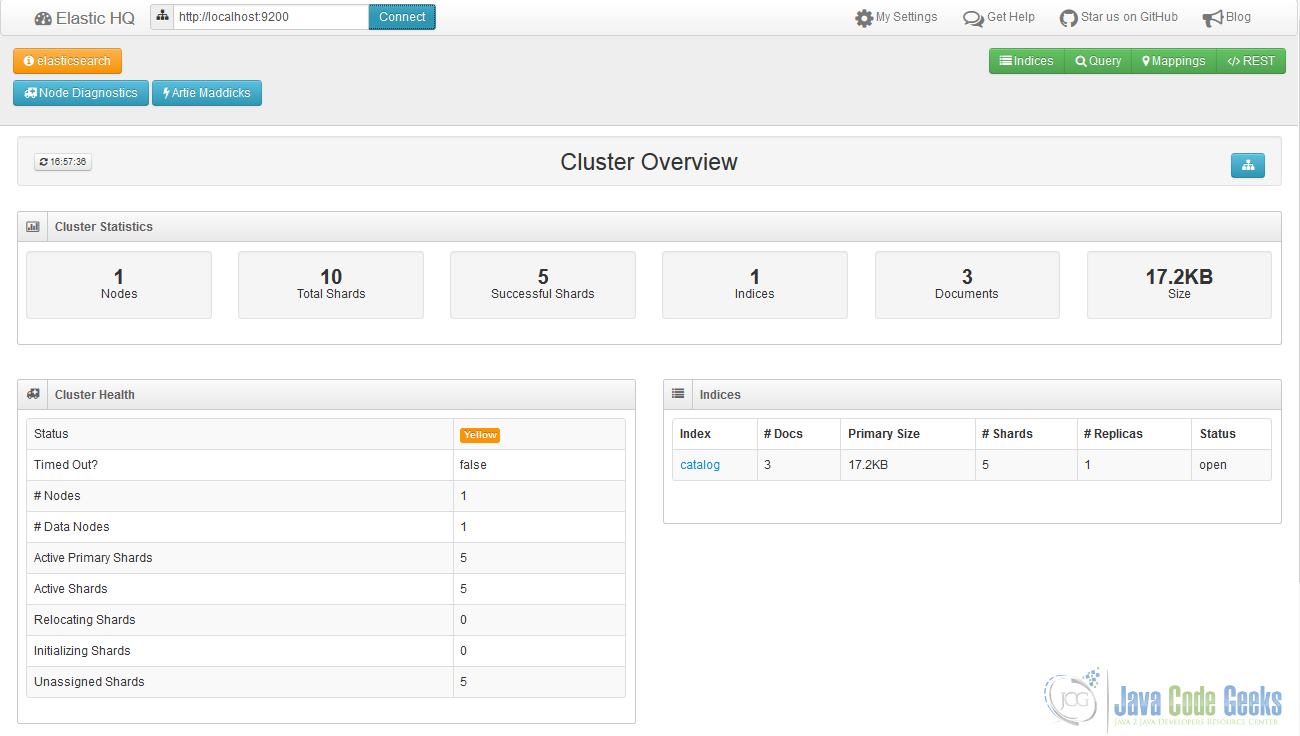
Before we touch upon last plugin, the search-guard, it would be good to talk about the state of security in Elasticsearch. In fact, we have better to say that out of the box Elasticsearch has nothing to offer in terms of security or alike (although this feature, along with many others, is available as part of commercial distribution of Elasticsearch). The search-guard is the oldest community supported plugin which adds quite a lot of security capabilities to Elasticsearch. Please make sure to take a look at this one, if you are serious about running Elasticsearch in production, luckily it supports all recent Elasticsearch versions.
5. Conclusions
With this part, the “Elasticsearch for Java Developers” series is coming to its logical end. Along this tutorial we have learned about Elasticsearch, what it does and how to communicate with it using command line tools and its rich set of RESTful APIs. We have also discussed different flavors of Java APIs available at the moment and briefly debated when to use one or another. And lastly, we have covered a flourishing ecosystem of projects (and products) which has emerged around Elasticsearch and heavily relies on it features.
Hopefully, you have learned something along the way, and if you have hesitated before about giving Elasticsearch a try or not, all your doubts should be cleared out now. It is a great product with terrific potential to solve wide range of hard problems and power your ideas to success.
With that, best of luck on this journey! The complete source code for this article is available here.

For everyone who is interested in Hibernate Search, the preliminary support for Elasticsearch 5.x has been announced: http://in.relation.to/2017/04/15/HibernateSearchNowSpeakingEs5/ !