Discover faster, more efficient performance monitoring with an enterprise APM product learning from your apps. Take the AppDynamics APM Guided Tour!
“No provision need be made for the user to program the return of registers to the free-storage list.”
This line (along with the dozen or so that followed it) is buried in the middle of John McCarthy’s landmark paper, “Recursive Functions of Symbolic Expressions and Their Computation by Machine,” published in 1960. It is the first known description of automated memory management.
In specifying how to manage memory in Lisp, McCarthy was able to exclude explicit memory management. Thus, McCarthy relieved developers of the tedium of manual memory management. What makes this story truly amazing is that these few words inspired others to incorporate some form of automated memory management—otherwise known as garbage collection (GC)—into more than three quarters of the more widely used languages and runtimes developed since then. This list includes the two most popular platforms, Java’s Virtual Machine (JVM) and .NET’s Common Language Runtime (CLR), as well as the up and coming Go Lang by Google. GC exists not just on big iron but on mobile platforms such as Android’s Dalvik, Android Runtime, and Apple’s Swift. You can even find GC running in your web browser as well as on hardware devices such as SSDs. Let’s explore some of the reasons why the industry prefers automated over manual memory management.
Automatic Memory Management’s Humble Beginnings
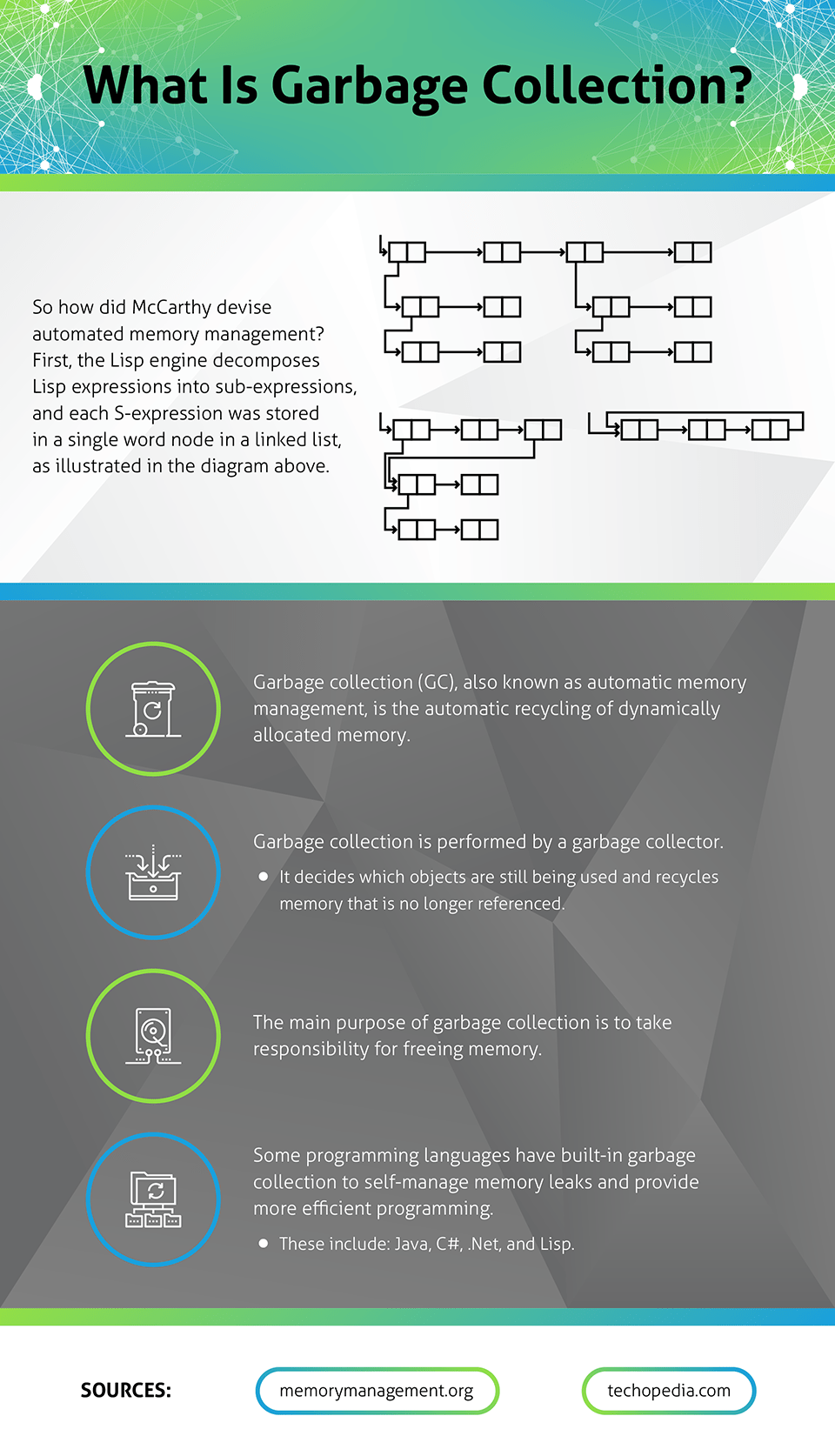
So, how did McCarthy devise automated memory management? First, the Lisp engine decomposed Lisp expressions into sub-expressions, and each S-expression was stored in a single word node in a linked list. The nodes were allocated from a free list, but they didn’t have to be returned to the free list until it was empty.
Once the free list was empty, the runtime traced through the linked list and marked all reachable nodes. Next, it scanned through the buffer containing all nodes, and returned unmarked nodes to the free list. With the free-list refilled, the application would continue on.
Today, this is known as a single-space, in-place, tracing garbage collection. The implementation was quite rudimentary: it only had to deal with an acyclic-directed graph where all nodes were exactly the same size. Only a single thread ran, and that thread either executed application code or the garbage collector. In contrast, today’s collectors in the JVM must cope with a directed graph with cycles and nodes that are not uniformly sized. The JVM is multi-threaded, running on multi-core CPUs, possibly multi-socketed motherboards. Consequently, today’s implementations are far more complex—to the point GC experts struggle to predict performance in any given situation.

Slow Going: Garbage Collection Pause Time
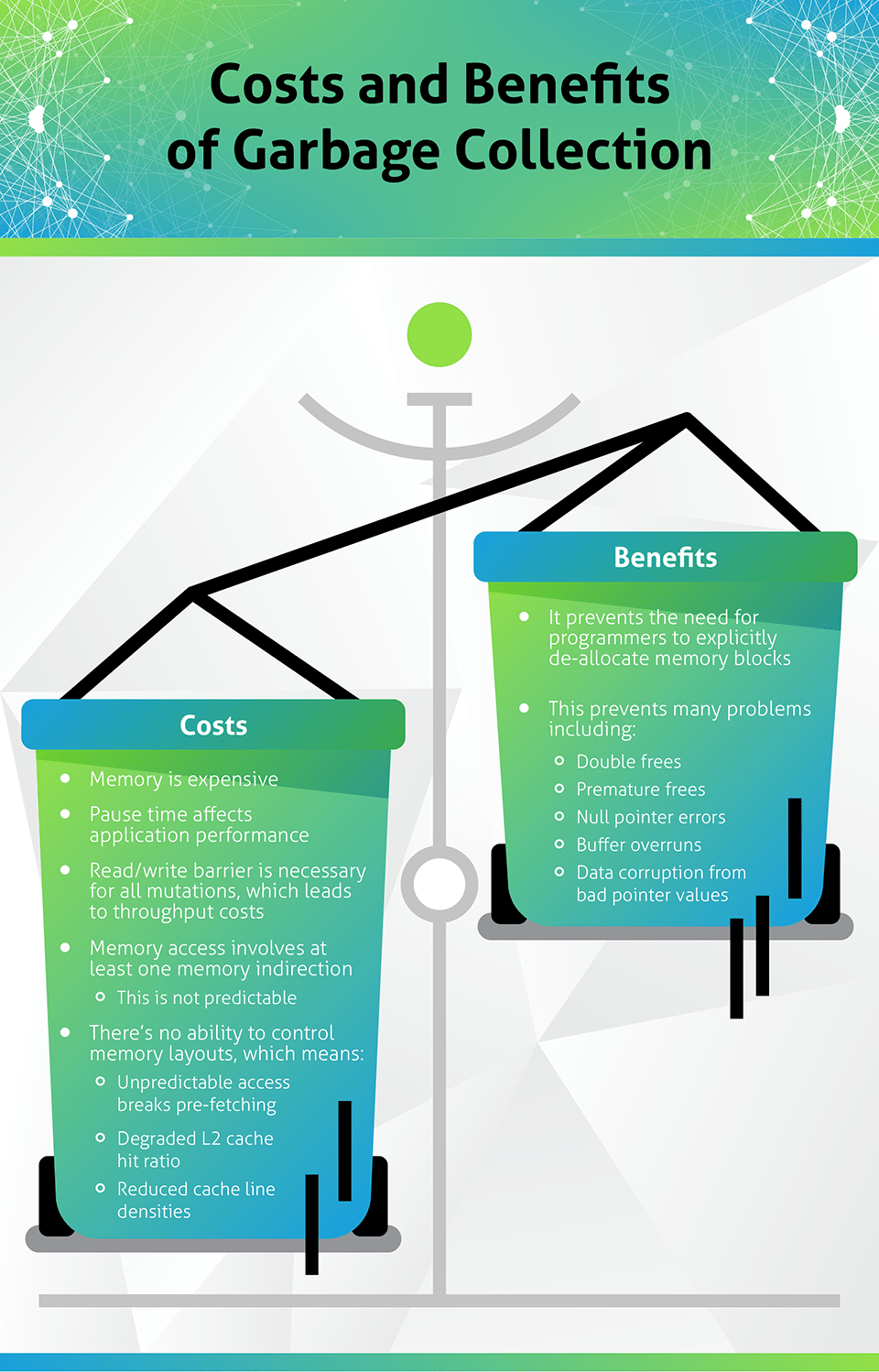
When the Lisp garbage collector ran, the application stalled. In the initial versions of Lisp it was common for the collector to take 30 to 40 percent of the CPU cycles. On 1960s hardware this could cause the application stall, in what is known as a stop-the-world pause, for several minutes. The benefit was that allocation had barely any impact on application throughput (the amount of useful work done). This implementation highlighted the constant battle between pause time and impact on application throughput that persists to this day.
In general, the better the pause time characteristic of the collector, the more impact it has on application throughput. The current implementations in Java all come with pause time/overhead costs. The parallel collections come with long pause times and low overheads, while the mostly concurrent collectors have shorter pause times and consume more computing resources (both memory and CPU).
The goal of any GC implementer is to maximize the minimum amount of processor time that mutator threads are guaranteed to receive, a concept known as minimum mutator utilization (MMU). Even so, current GC overheads can run well under 5 percent, versus the 15 to 20 percent overhead you will experience in a typical C++ application.
So why you don’t feel this overhead like you do in a Java application? Because the overhead is evenly spread throughout the C/C++ run time, it is perceptibly invisible to the end users. In fact the biggest complaint about managed memory is that it pauses your application at unpredictable times for an unpredictable amount of time.
Garbage Collection Advancements
Sun Java’s initial garbage collector did nothing to improve the image of garbage collection. Its single-threaded, single-spaced implementation stalled applications for long periods of time and created a significant drag on allocation rates. It wasn’t until Java 2, when a generational memory pool scheme—along with parallel, mostly concurrent and incremental collectors—was introduced. While these collectors offered improved pause time characteristics, pause times continue to be problematic. Moreover, these implementations are so complex that it’s unlikely most developers have the experience necessary to tune them. To further complicate the picture, IBM, Azul, and RedHat have one or more of their own garbage collectors—each with their own histories, advantages and quirks. In addition, a number of companies including SAP, Twitter, Google, Alibaba, and others have their own internal JVM teams with modified versions of the Garbage collectors.
Over time, an addition of alternate and more complex allocation paths led to huge improvements in the allocation overhead picture. For example, a fast-path allocation in the JVM is now approximately 30 times faster than a typical allocation in C/C++. The complication: Only data that can pass an escape analysis test is eligible for fast-path allocation. (Fortunately the vast majority of our data passes this test and benefits from this alternate allocation path.)
Another advantage is in the reduced costs and simplified cost models that come with evacuating collectors. In this scheme, the collector copies live data to another memory pool. Thus, there is no cost to recover short-lived data. This isn’t an invitation to allocate ad nauseam, because there is a cost for each allocation and high allocation rates trigger more frequent GC activity and accumulate extra copy costs. While evacuating collectors helps make GC more efficient and predictable, there are still significant resource costs.
That leads us to memory. Memory management demands that you retain at least five times more memory than manual memory management needs. There are times the developer knows for certain that data should be freed. In those cases, it is cheaper to explicitly free rather than have a collector reason through the decision. It was these costs that originally caused Apple to choose manual memory management for Objective-C. In Swift, Apple chose to use reference counting. They added annotations for weak and owned references to help the collector cope with circular references.
There are other intangible or difficult-to-measure costs that can be attributed to design decisions in the runtime. For example, the loss of control over memory layouts can result in application performance being dominated by L2 cache misses and cache line densities. The performance hit in these cases can easily exceed a factor of 10:1. One of the challenges for future implementers is to allow for better control of memory layouts.
Looking back at how poorly GC performed when first introduced into Lisp and the long and often frustrating road to its current state, it’s hard to imagine why anyone building a runtime would want to use managed memory. But consider that if you manually manage memory, you need access to the underlying reference system—and that means the language needs added syntax to manipulate memory pointers.
Languages that rely on managed memory consistently lack the syntax needed to manage pointers because of the memory consistency guarantee. That guarantee states that all pointers will point where they should without dangling (null) pointers waiting to blow up the runtime, if you should happen to step on them. The runtime can’t make this guarantee if developers are allowed to directly create and manipulate pointers. As an added bonus, removing them from the language removes indirection, one of the more difficult concepts for developers to master. Quite often bugs are a result of a developer engaged in the mental gymnastics required to juggle a multitude of competing concerns and getting it wrong. If this mix contains reasoning through application logic, along with manual memory management and different memory access modes, bugs likely appear in the code. In fact, bugs in systems that rely on manual memory management are among the most serious and largest source of security holes in our systems today.
To prevent these types of bugs the developer always has to ask, “Do I still have a viable reference to this data that prevents me from freeing it?” Often the answer to this question is, “I don’t know.” If a reference to that data was passed to another component in the system, it’s almost impossible to know if memory can safely be freed. As we all know too well, pointer bugs will lead to data corruption or, in the best case, a SIGSEGV.
Removing pointers from the picture tends to yield a code that is more readable and easier to reason through and maintain. GC knows when it can reclaim memory. This attribute allows projects to safely consume third-party components, something that rarely happens in languages with manual memory management.
Conclusion
At its best, memory management can be described as a tedious bookkeeping task. If memory management can be crossed off the to-do list, then developers tend to be more productive and produce far fewer bugs. We have also seen that GC is not a panacea as it comes with its own set of problems. But thankfully the march toward better implementations continues.
Go Lang’s new collector uses a combination of reference counting and tracing to reduce overheads and minimize pause times. Azul claims to have solved the GC pause problem by driving pause times down dramatically. Oracle and IBM keep working on collectors that they claim are better suited for very large heaps that contain significant amounts of data. RedHat has entered the fray with Shenandoah, a collector that aims to completely eliminate pause times from the run time. Meanwhile, Twitter and Google continue to improve the existing collectors so they continue to be competitive to the newer collectors.
Discover faster, more efficient performance monitoring with an enterprise APM product learning from your apps. Take the AppDynamics APM Guided Tour!

Nice!!