This article is part of our Academy Course titled Elasticsearch Tutorial for Java Developers.
In this course, we provide a series of tutorials so that you can develop your own Elasticsearch based applications. We cover a wide range of topics, from installation and operations, to Java API Integration and reporting. With our straightforward tutorials, you will be able to get your own projects up and running in minimum time. Check it out here!
1. Introduction
Effective, fast and accurate search functionality is an integral part of vast majority of the modern applications and software platforms. Either you are running a small e-commerce web site and need to offer your customers a search over product catalogs, or you are a service provider and need to expose an API to let the developers filter over users and companies, or you are building any kind of messaging application where finding a conversation in the history is a must-have feature from day one … What is really important is that, delivering as relevant results as fast as possible could be yet another competitive advantage of the product or platform you are developing.
Table Of Contents
Indeed, the search could have many faces, purposes, goals and different scale. It could be as simple as looking by exact word match or as complex as trying to understand the intent and the contextual meaning of the words one’s is looking for (semantic search engines). In terms of scale, it could be as trivial as querying a single database table, or as complex as crunching over billions and billions of web pages in order to deliver the desired results. It is very interesting and flourishing area of research, with many algorithms and papers published over the years.
In case you are a Java / JVM developer, you may have heard about Apache Lucene project, a high-performance, full-featured indexing and search library. It is the first and the best in class choice to unleash the power of full-text search and embed it into your applications. Although it is a terrific library by all means, many developers have found Apache Lucene too low-level and not easy to use. That is one of the reasons why two other great projects, Elasticsearch and Apache Solr, have been born.
In this tutorial, we are going to talk about Elasticsearch, making an emphasis on development side of things rather than operational. We are going to learn the basics of Elasticsearch, get familiarized with the terminology and discuss different ways to run it and communicate with it from within Java / JVM applications or command line. At the very end of the tutorial we are going to talk about Elastic Stack to showcase the ecosystem around Elasticsearch and its amazing capabilities.
If you are a junior or seasoned Java / JVM developer and interested in learning about Elasticsearch, this tutorial is definitely for you.
2. Elasticsearch Basics
To get started, it would be great to answer the question: so, what is Elasticsearch, how it can help me and why should I use it?
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements. – https://www.elastic.co/
Elasticsearch is built on top of Apache Lucene but favors communication over RESTful APIs and advanced in-depth analytics features. The RESTful part makes Elasticsearch particularly easy to learn and use. As of the moment of this writing, the latest stable release branch of the Elasticsearch was 5.2, with the latest released version being 5.2.0. We should definitely give Elasticsearch guys the credit for keeping the pace of delivering new releases so often, 5.0.x / 5.1.x branches are just a few months old ….
In perspective of Elasticsearch, being RESTful APIs has another advantage: every single piece of data sent to or received from Elasticsearch is itself a human-readable JSON document (although this is not the only protocol Elasticsearch supports as we are going to see later on).
To keep the discussion relevant and practical, we are going to pretend that we are developing the application to manage the catalog of books. The data model will include categories, authors, publisher, book details (like publishing date, ISBN, rating) and brief description.

Let us see how we could leverage Elasticsearch to make our book catalog easily searchable but before that we need to get familiarized a bit with the terminology. Although in the next couple of sections we are going to go over most of the concepts behind Elasticsearch, please do not hesitate to consult Elasticsearch official documentation any time.
2.1. Documents
To put it simply, in context of Elasticsearch document is just an arbitrary piece of data (usually, structured). It could be absolutely anything which makes sense to your applications (like users, logs, blog posts, articles, products, …) but this is a basic unit of information which Elasticsearch could manipulate.
2.2. Indices
Elasticsearch stores documents inside indices and as such, an index is simply a collection of the documents. To be fair, persisting absolutely different kind of the documents in the same index would be somewhat convenient but quite difficult to work with so every index may have one or more types. The types group documents logically by defining a set of common properties (or fields) every document of such type should have. Types serve as a metadata about documents and are very useful for exploring the structure of the data and constructing meaningful queries and aggregations.
2.3. Index Settings
Each index in Elasticsearch could have specific settings associated with it at the time of its creation. The most important ones are number of shards and replication factor. Let us talk about that for a moment.
Elasticsearch has been built from the ground up to operate over massive amount of indexed data which will very likely exceed the memory and/or storage capabilities of a single physical (or virtual) machine instance. As such, Elasticsearch uses sharding as a mechanism to split the index into several smaller pieces, called shards, and distribute them among many nodes. Please notice, once set the number of shards could not be altered (although this is not entirely true anymore, the index could be shrunk into fewer shards).
Indeed, sharding solves a real problem but it is vulnerable to data loss issues due to individual node failures. To address this problem, Elasticsearch supports high availability by leveraging replication. In this case, depending on replication factor, Elasticsearch maintains one or more copies of each shard and makes sure that each shard’s replica is placed on different node.
2.4. Mappings
The process of defining the type of the documents and assigning it to a particular index is called index mapping, mapping type or just a mapping. Coming up with a proper type mapping is, probably, one of the most important design exercises you would have to make in order to get most out of Elasticsearch. Let us take some time and talk about mappings in details.
Each mapping consists of optional meta-fields (they usually start from the underscore ‘_’ character like _index, _id, _parent) and regular document fields (or properties). Each field (or property) has a data type, which in Elasticsearch could fall into one of those categories:
- Simple data types
- text – indexes full-text values
- keyword – indexes structured values
- date – indexes date/time values
- long – indexes signed 64-bit integer values
- integer – indexes signed 32-bit integer values
- short – indexes signed 16-bit integer values
- byte – indexes signed 8-bit integer values
- double – indexes double-precision 64-bit IEEE 754 floating point values
- float – indexes single-precision 32-bit IEEE 754 floating point values
- half_float – indexes half-precision 16-bit IEEE 754 floating point values
- scaled_float – indexes floating point values that is backed by a long and a fixed scaling factor
- boolean – indexes boolean values (for example, true/false, on/off, yes/no, 1/0)
- ip – indexes either IPv4 or IPv6 address values
- binary – indexes any binary value encoded as a Base64 string
- Composite data types
- Specialized data type
- geo_point – indexes latitude-longitude pairs
- geo_shape – indexes an arbitrary geo shapes (such as rectangles and polygons)
- completion – dedicated data type to back auto-complete/search-as-you-type functionality
- token_count – dedicated data type to count the number of tokens in a string
- percolator – specialized data type to store the query which is going to be used by percolate query to match the documents
- Range data types:
- integer_range – indexes a range of signed 32-bit integers
- float_range – indexes a range of single-precision 32-bit IEEE 754 floating point values
- long_range – indexes a range of signed 64-bit integers
- double_range – indexes a range of double-precision 64-bit IEEE 754 floating point values
- date_range – indexes a range of date values represented as unsigned 64-bit integer milliseconds elapsed since system epoch
Cannot stress it enough, choosing the proper data type for the fields (properties) of your documents is a key for fast, effective search which delivers really relevant results. There is one catch though: the fields in each mapping type are not entirely independent of each other. The fields with the same name and within the same index but in different mapping types must have the same mapping definition. The reason is that internally those fields are mapped to the same field.
Getting back to our application data model, let us try to define the simplest mapping type for books collections, utilizing our just acquired knowledge about data types.

For most of the book properties the mapping data types are pretty straightforward but what about authors and categories? Those properties essentially contain the collection of values for which Elasticsearch has no direct data type yet, … or has it?
2.5. Advanced Mappings
Interestingly, indeed Elasticsearch has no dedicated array or collection type but by default, any field may contain zero or more values (of its data type).
In case of complex data structures, Elasticsearch supports mapping using object and nested data types as well as establishing parent/child relationships between documents within the same index. There are pros and cons of each approach but in order to learn how to use those techniques let us store categories as nested property of the books mapping type, while authors are going to be represented as a dedicated mapping which refers to books as parent.
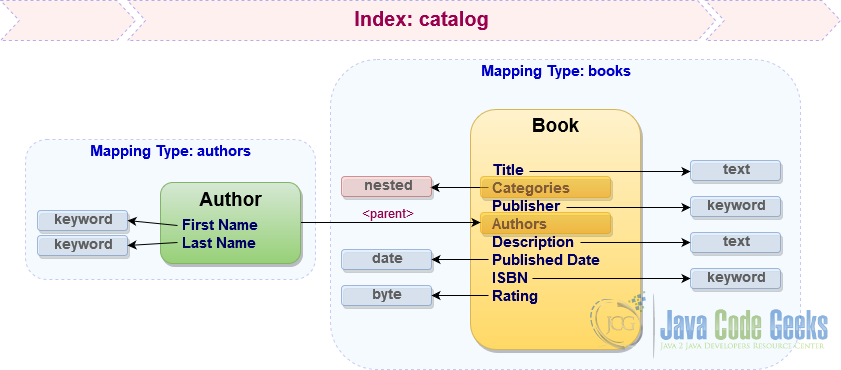
These are our close to final mapping types for the catalog index. As we already know, JSON is a first class citizen in Elasticsearch, so let us get a feeling of how the typical index mapping looks like in the format Elasticsearch actually understands.
{
"mappings": {
"books": {
"_source" : {
"enabled": true
},
"properties": {
"title": { "type": "text" },
"categories" : {
"type": "nested",
"properties" : {
"name": { "type": "text" }
}
},
"publisher": { "type": "keyword" },
"description": { "type": "text" },
"published_date": { "type": "date" },
"isbn": { "type": "keyword" },
"rating": { "type": "byte" }
}
},
"authors": {
"properties": {
"first_name": { "type": "keyword" },
"last_name": { "type": "keyword" }
},
"_parent": {
"type": "books"
}
}
}
}
You may be surprised but explicit definition of the fields and mapping types could be omitted. Elasticsearch supports dynamic mapping thereby new mapping types and new field names will be added automatically when document is indexed (in this case Elasticsearch makes a decision what the field data types should be).
Another important detail to mention is that each mapping type can have custom metadata associated with it by using special _meta property. It is exceptionally useful technique which will be used by us later on in the tutorial.
2.6. Indexing
Once Elasticsearch has all your indices and their mapping types defined (or inferred using dynamic mapping), it is ready to analyze and index the documents. It is quite complex but interesting process which involves at least analyzers, tokenizers, token filters and character filters.
Elasticsearch supports quite a rich number of mapping parameters which let you tailor the indexing, analysis and search phases precisely to your needs. For example, every single field (or property) could be configured to use own index-time and search-time analyzers, support synonyms, apply stemming, filter out stop words and much, much more. By carefully crafting these parameters you may end up with superior search capabilities, however the opposite also holds true, having them loose, and a lot of irrelevant and noisy results may be returned every time.
If you don’t need all that, you are good to go with the defaults as we have done in the previous section, omitting the parameters altogether. However, it is rarely the case. To give a realistic example, most of the time our applications have to support multiple languages (and locales). Luckily, Elasticsearch shines here as well.
Before we move on to the next topic, there is an important constraint you have to be aware of. Once the mapping types are configured, in majority of cases they cannot be updated as it automatically assumes that all the documents in the corresponding collections are not up to date anymore and should be re-indexed.
2.7. Internalization (i18n)
The process of indexing and analyzing the documents is very sensitive to the native language of the document. By default, Elasticsearch uses standard analyzer if none is specified in the mapping types. It works well for most of the languages but Elasticsearch supplies the dedicated analyzers for Arabic, Armenian, Basque, Brazilian, Bulgarian, Czech, Danish, Dutch, English, Finnish, French, German, Greek, Hindi, Hungarian, Indonesian, Irish, Italian, Latvian, Lithuanian, Norwegian, Persian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish, Thai and a few more.
There are couple of ways to approach the indexing of the same document in multiple languages, depending on your data model and business case. For example, if document instances physically exist (translated) in multiple languages, than it probably makes sense to have one index per language.
In case when documents are partially translated, Elasticsearch has another interesting option hidden in the sleeves called multi-fields. Multi-fields allow indexing the same document field (property) in different ways to be used for different purposes (like, for example, supporting multiple languages). Getting back to our books mapping type, we may have defined the title property as a multi-field one, for example:
"title": {
"type": "text",
"fields": {
"en": { "type": "text", "analyzer": "english" },
"fr": { "type": "text", "analyzer": "french" },
"de": { "type": "text", "analyzer": "german" },
...
}
}Those are not the only options available but they illustrate well enough the flexibility and maturity of the Elasticsearch in fulfilling quite sophisticated demands.
3. Running Elasticsearch
Elasticsearch embraces simplicity in many ways and one of those is exceptionally easy way to get started on mostly any platform in just two steps: download and run. In the next couple of sections we are going to talk about quite a few different ways to get your Elasticsearch up and running.
3.1. Standalone Instance
Running Elasticsearch as a standalone application (or instance) is the fastest and simplest route to take. Just download the package of your choice and run the shell script on Linux/Unix/Mac operating systems:
bin/elasticsearch
Or from the batch file on Windows operating system:
bin\elasticsearch.bat
And that is it, pretty straightforward, isn’t it? However, before we go ahead and talk about more advanced options, it would be useful to get a taste what it actually means to run an instance of Elasticsearch. To be more precise, every time we say we are starting the instance of Elasticsearch, we are actually starting an instance of a node. As such, depending on provided configuration (by default, it is stored in conf/elastisearch.yml file) there are multiple node types which Elasticsearch supports at the moment. In this regards, every running standalone instance of Elasticsearch could be configured to run as one (or combination) of those node types:
- data node: these kind of nodes are maintaining the data and performing operations over this data (it is controlled by
node.dataconfiguration setting which is set totrueby default) - ingest node: these are special kind of nodes which are able to apply an ingest pipeline in order to transform and enrich the document before indexing it (it is controlled by
node.ingestconfiguration setting which is set totrueby default)
Please take a note that this is not an exhaustive list of node types yet, we are going to learn quite a few more in just a moment.

3.2. Clustering
Running Elasticsearch as a standalone instance is good for development, learning or testing purposes but certainly is not an option for production systems. Generally, in most real-world deployments Elasticsearch is configured to run in a cluster: a collection of one or more nodes preferably split across multiple physical instances. Elasticsearch cluster manages all the data and also provides federated indexing, aggregations and search capabilities across all its nodes.
Every Elasticsearch cluster is identified by a unique name which is controlled by cluster.name configuration setting (set to "elasticsearch" by default). The nodes are joining the cluster by referring to its name so it is quite important piece of configuration. Last but not least, each cluster has a dedicated master node which is responsible for performing cluster-wide actions and operations.
Specifically applicable to the clustered configuration, Elasticsearch supports a couple of more node types, in addition to the ones we already know about:
- master-eligible node: these kind of nodes are marked as eligible to be elected as the master node (it is controlled by
node.masterconfiguration setting which is set totrueby default) - coordinating-only node: these are special kind of nodes which are able to only route requests, handle some search phases, and distribute bulk indexing, essentially behaving as load balancers (the node automatically becomes coordinating-only when
node.master,node.dataandnode.ingestsettings are all set tofalse) - tribe node: these are special kind of coordinating-only nodes that can connect to multiple clusters and execute search or other operations across all of them (it is controlled by
tribe.*configuration settings)
By default, if configuration is not specified, each Elasticsearch node is configured to be master-eligible, data node and ingest node. Similarly to the standalone instance, Elasticsearch cluster instances could be started quickly from the command line:
bin/elasticsearch -Ecluster.name=<cluster-name> -Enode.name=<node-name>
Or on Windows platform:
bin\elasticsearch.bat -Ecluster.name=<cluster-name> -Enode.name=<node-name>
Along with sharding and replication, an Elasticsearch cluster has all the properties of a highly available and scalable system which will organically evolve to meet the needs of your applications. To be noted, despite significant efforts invested into stabilizing Elasticsearch clustering implementation and covering a lot of edge cases related to a different kind of failure scenarios, as of now Elasticsearch is still not recommended to serve as a system of record (or primary storage engine of your data).
3.3. Embedding Into Application
Not a long time ago (right till 5.0 release branch) Elasticsearch fully supported the option to be run as part of the application, within the same JVM process (the technique commonly referred as embedding). Although it is certainly not a recommended practice, sometimes it was very useful and saves a lot of effort, for example during integration / system / component test runs.
The situation has changed recently and embedded version of the Elasticsearch is not officially supported nor recommended anymore. Luckily, in case you really need the embedded instance, for example while slowly migrating from older Elasticsearch releases, it is still possible.
@Configuration
public class ElasticsearchEmbeddedConfiguration {
private static class EmbeddedNode extends Node {
public EmbeddedNode(Settings preparedSettings) {
super(
InternalSettingsPreparer.prepareEnvironment(preparedSettings, null),
Collections.singletonList(Netty4Plugin.class)
);
}
}
@Bean(initMethod = "start", destroyMethod = "stop")
Node elasticSearchTestNode() throws NodeValidationException, IOException {
return new EmbeddedNode(
Settings
.builder()
.put(NetworkModule.TRANSPORT_TYPE_KEY, "netty4")
.put(NetworkModule.HTTP_TYPE_KEY, "netty4")
.put(NetworkModule.HTTP_ENABLED.getKey(), "true")
.put(Environment.PATH_HOME_SETTING.getKey(), home().getAbsolutePath())
.put(Environment.PATH_DATA_SETTING.getKey(), data().getAbsolutePath())
.build());
}
@Bean
File home() throws IOException {
return Files.createTempDirectory("elasticsearch-home-").toFile();
}
@Bean
File data() throws IOException {
return Files.createTempDirectory("elasticsearch-data-").toFile();
}
@PreDestroy
void destroy() throws IOException {
FileSystemUtils.deleteRecursively(home());
FileSystemUtils.deleteRecursively(data());
}
}Although this code snippet is based on the terrific Spring Framework, the idea is pretty simple and could be used in any JVM-based application. With that being said, be warned though and reconsider the long-term solution without the need to embed Elasticsearch.
3.4. Running As Container
The rise of such tools as Docker, CoreOS and tremendous popularization of the containers and container-based deployments significantly changed our thinking about infrastructure and, in many cases, the development approaches as well.
To say it in other words, there is no need to download Elasticsearch and run it using the shell scripts or batch files. Everything is the container and could be pulled, configured and run using the single docker command (thankfully, there is an official Elasticseach Dockerhub repository).
Assuming you have Docker installed on your machine, let us run the single Elasticsearch instance relying on the default configuration:
docker run -d -p 9200:9200 -p 9300:9300 elasticsearch:5.2.0
Spinning an Elasticsearch cluster is a little bit more complicated but certainly much easier than doing that manually using shell scripts. By and large, Elasticsearch cluster needs multicast support in order for nodes to auto-discover each other, but with Docker you would need to fall back to unicast discovery unfortunately (unless you have subscription to unlock commercial features).
docker run -d -p 9200:9200 -p 9300:9300 --name es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es1 -E transport.host=0.0.0.0
docker run -d --name es2 --link=es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es2 -E transport.host=0.0.0.0 -E discovery.zen.ping.unicast.hosts=es1
docker run -d --name es3 --link=es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es3 -E transport.host=0.0.0.0 -E discovery.zen.ping.unicast.hosts=es1
Once the containers are started, the cluster of three Elasticsearch nodes should be created, with master node accessible at http://localhost:9200 (in case of native Docker support). If for some reasons you are still on Docker Machine (or even older boot2docker), the master node will be exposed at http://<docker-machine-ip>:9200 respectively.
If you are actively using Docker Compose, there are certain limitations which will complicate your life at this point. At the moment Elasticsearch images need some arguments to be passed to the entry point (everything you see at the end of the command line as -E option) however such feature is not supported by Docker Compose yet (although you may build your own images as a workaround).
Along this tutorial we are going to use only Elasticsearch started as Docker containers, hopefully this is something you have already adopted a long time ago.
4. Where Elasticsearch Fits
Search is one of the key features of the Elasticsearch and it does that exceptionally well. But Elasticsearch goes well beyond just search and provides a rich analytics capabilities shaped as aggregations framework which does data aggregations based on a search query. In case you would need to do some analytics around your data, Elasticsearch is a great fit here as well.
Although it may be not immediately apparent, Elasticsearch could be used to manage time series data (for example, metrics, stock prices) and even back search for images. One of the misconceptions about Elasticsearch is that it could be used as a data store. In some extent it is true, it does store the data however it does not provide the same guarantees yet you would expect from the typical data store.
5. Conclusion
Although we have talked about many things here, tons of interesting details and useful features of the Elasticsearch have not been covered at all yet. Our focus was kept on development side of things, and as such, the emphasis has been made on understanding the basics of Elasticsearch and starting off quickly. Hopefully, you are already thrilled and excited enough to start reading the official documentation reference right away as more interesting topics are on the way.
6. What’s next
In the next section we are going to jump right from the discussions into the actions by exploring and playing with the myriads of RESTful APIs exposed by Elasticsearch, armed only with command line and the brilliant curl / http tools.
The source code for this post is available here for download.

Very Good Summary. Thanks.