In one design patterns class, I had an interesting discussion about modelling domain logic. Specifically, it was about isolating the domain logic. An application would typically be divided into three parts:
- Presentation (e.g. desktop GUI, browser, web service)
- Domain logic
- Infrastructure (e.g. persistence storage, e-mail)
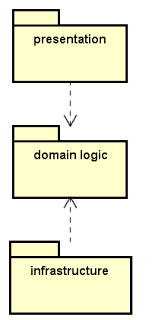
The class found it interesting that the dependency arrows were pointing towards the domain logic part. They asked, “Is the diagram intentionally made wrong? Shouldn’t the domain logic part be dependent on the persistence storage?” It was a great question. And I wanted to share and post the discussion and explanation here.
Often Misunderstood
Most developers would usually have this misunderstanding in mind.
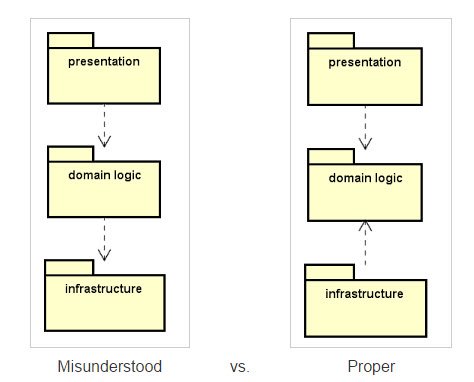
And this misunderstanding is largely due to the sequence of operations. It usually starts with a trigger (e.g. a user clicking a button or a link) in the presentation layer, which then calls something within the domain logic layer, which then calls something within the infrastructure layer (e.g. update a database table record).
While this is the correct sequence of operations, there’s something subtle in the way in which the domain logic layer can be implemented. This has something to do with dependency inversion.
Dependency Inversion Principle
The domain logic layer may need something from the infrastructure layer, like some form of access to retrieve from persistence storage. The usual patterns for this are: DAO and repository. I won’t explain these two patterns here. Instead, I would point out that the interface definitions are placed within the domain logic layer, and their implementations are placed in another separate layer.
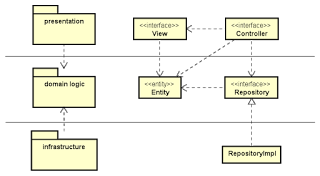
Placing the (DAO and repository) interface definitions inside the domain logic layer means that it is the domain logic layer that defines it. It is the one that dictates which methods are needed, and what return types are expected. This also marks the boundaries of the domain logic.
This separation between interface and implementation may be subtle, but key. Placing just the interface definitions allows the domain logic part to be free from infrastructure details, and allows it to be unit-tested without actual implementations. The interfaces can have mock implementations during unit testing. This subtle difference makes a big difference in rapid verification of (the development team’s understanding of) business rules.
This separation is the classic dependency inversion principle in action. Domain logic (higher-level modules) should not depend on DAO and repository implementations (low-level modules). Both should depend on abstractions. The domain logic defines the abstractions, and infrastructure implementations depend on these abstractions.
Most novice teams I’ve seen, place the DAO and repository interfaces together with their infrastructure-specific implementations. For example, say we have an StudentRepository and its JPA-specific implementation StudentJpaRepository. I would usually find novice teams placing them in the same package. While this is fine, since the application will still compile successfully. But the separation is gone, and domain logic is no longer isolated.
Now that I’ve explained why and how the domain logic part does not depend on the infrastructure part, I’d like to touch on how the presentation part is accidentally entangled with the domain logic.
Separated Presentation
Another thing I often see with novice teams is how they end up entangling their domain logic with their presentation. And this results into this nasty cyclic dependency. This cyclic dependency is more logical than physical. Which makes it all the more difficult to detect and prevent.
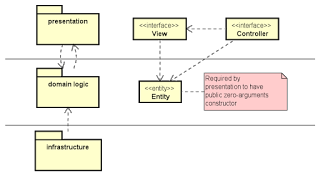
I won’t use a rich GUI presentation example here, since Martin Fowler has already written a great piece on it. Instead, I’ll use a web-browser-based presentation as an example.
Most web-based systems would use a web framework for its presentation. These frameworks usually implement some form of MVC (model-view-controller). The model used is usually the model straight from the domain logic part. Unfortunately, most MVC frameworks require something about the model. In the Java world, most MVC frameworks require that the model follow JavaBean conventions. Specifically, it requires the model to have a public zero-arguments constructor, and getters and setters. The zero-arguments constructor and setters are used to automatically bind parameters (from HTTP POST) to the model. The getters are used in rendering the model in a view.
Because of this implied requirement by MVC frameworks used in the presentation, developers would add a public zero-arguments constructor, getter and setters, to all their domain entities. And they would justify this as being required. Unfortunately, this gets the in the way of implementing domain logic. It gets entangled with the presentation. And worse, I’ve seen domain entities being polluted with code that emits HTML-encoded strings (e.g. HTML code with less-than and greater-than signs encoded) and XML, just because of presentation.
If it is all right to have your domain entity implemented as a JavaBean, then it would be fine to have it used directly in your presentation. But if the domain logic gets a bit more complicated, and requires the domain entity to lose its JavaBean-ness (e.g. no more public zero-arguments constructor, no more setters), then it would be advisable for the domain logic part to implement domain logic, and have the presentation part adapt by creating another JavaBean object to satisfy its MVC needs.
An example I use often is a UserAccount that is used to authenticate a user. In most cases, when a user wishes to change the password, the old password is also needed. This helps prevent unauthorized changing of the password. This is clearly shown in the code below.
public class UserAccount {
...
public void changePassword(
String oldPassword, String newPassword) {…}
}But this does not follow JavaBean conventions. And if the MVC presentation framework would not work well with the changePassword method, a naive approach would be to remove the erring method and add a setPassword method (shown below). This weakens the isolation of the domain logic, and causes the rest of the team to implement it all over the place.
public class UserAccount {
...
public void setPassword(String password) {…}
}It’s important for developers to understand that the presentation depends on the domain logic. And not the other way around. If the presentation has needs (e.g. JavaBean convention), then it should not have the domain logic comply with that. Instead, the presentation should create additional classes (e.g. JavaBeans) that have knowledge of the corresponding domain entities. But unfortunately, I still see a lot of teams forcing their domain entities to look like JavaBeans just because of presentation, or worse, having domain entities create JavaBeans (e.g. DTOs) for presentation purposes.
Arrangement Tips
Here’s a tip in arranging your application. Keep your domain entities and repositories in one package. Keep your repository and other infrastructure implementations in a separate package. Keep your presentation-related classes in its own package. Be mindful of which package depends on which package. The package that contains the domain logic is preferrably at the center of it all. Everything else depends on it.
When using Java, the packages would look something like this:
com.acme.myapp.context1.domain.model- Keep your domain entities, value objects, and repositories (interface definitions only) here
com.acme.myapp.context1.infrastructure.persistence.jpa- Place your JPA-based repository and other JPA persistence-related implementations here
com.acme.myapp.context1.infrastructure.persistence.jdbc- Place your JDBC-based repository and other JDBC persistence-related implementations here
com.acme.myapp.context1.presentation.web- Place your web/MVC presentation components here. If the domain entities needed for presentation do not comply with MVC framework requirements, create additional classes here. These additional classes will adapt the domain entities for presentation-purposes, and still keep the domain entities separated from presentation.
Note that I’ve used context1, since there could be several contexts (or sub-systems) in a given application (or system). I’ll discuss about having multiple contexts and having multiple models in a future post.
That’s all for now. I hope this short explanation can shed some light to those who wonder why their code is arranged and split in a certain way.
Thanks to Juno Aliento for helping me with the class during this interesting discussion.
Happy holidays!
| Reference: | Isolating the Domain Logic from our JCG partner Lorenzo Dee at the Adapting and Learning blog. |

In response to: https://www.javacodegeeks.com/2017/01/isolating-domain-logic.html As is becoming more and more common as the years pass, what was supposed to be a basically simple idea has become corrupted so that all traces of the original idea have been completely lost, just like in the game “Chinese Whispers”. You have forgotten what the word “dependency” means, and you have forgotten what the term “Dependency Inversion” means. The wikipedia article https://en.wikipedia.org/wiki/Dependency “dependency” is described as follows: “In computer science dependency, or coupling, is a state in which one object uses a function of another object” As an example, let us take two modules:… Read more »
Tony Marston, thank you for the much-needed clarification – and education to the masses of programmers out there. In my nearly four decades of programming and (later) software engineering, I have seen new terminology arise for things that already exist. I have also seen a shift away from pedantic (i.e., a well-defined standard) definition of terms to a free-for-all, in which everyone has their own private meaning for what is otherwise a well-established term. Obviously, such chaotic practices lead to nothing but confusion, especially when debating the merits of certain programming practices, methodologies, or languages. I cannot help but be… Read more »