A bit of history
One thing that never ceases to amaze me is how Activiti is being used in some very large organisations at some very impressive scales. In the past, this has led to various optimizations and refactorings, amongst which was the async executor – replacement for the old job executor. For the uninitiated: these executors handle timers and async continuations in process instances. In the last two years especially, we’ve seen the use of it grow substantially. The introduction of the async executor boosted performance significantly. However, last year at our community event in Paris we learned that when dealing with an enormous amount of jobs, the queries used by the executor could lead to the need for table scans. Which is never a good thing.
So, we knew there was one thing we really wanted to do before finalising version 6, and that is refactoring the async executor such that all queries it used were dead simple. This did mean we had to split the job data into various tables that match the different types and states, while still keeping API compatible with previous Activiti releases.
In the last couple of months, we’ve been doing exactly that (amongst many other things), with some nice results and some new nice APIs that enrich the platform. I could fill another blog on how the ‘new’ async executor works, but I’ve done that yesterday for the documentation, so if you are interested in how it all works, go and check the online docs or check the source code on the v6 branch.
The architectural design is of course influenced by what we have learned from the past two implementations, but it’s also heavy influenced by concepts from message queueing systems. One of the design goals was that it should be super-easy to plug in a message queue and run with it, as we had a gut feeling that this would be beneficial for performance.
And so we did. Making the async executor work together with a message queue proved to be almost trivial due to the new architecture. If you are interested in the implementation, I also added a section in the docs on this very topic.
And, of course, you know me, I just wanted to benchmark these two executor implementations against each other ��
Benchmark project
You can find the code I used on Github: https://github.com/jbarrez/queue-based-async-executor-benchmark
Basically, what it does is run the Main.java with a configuration properties file.
- Booting up a process engine with a decent config (I’ve seen some Activiti benchmarks recently online that benchmarked Activiti’s performance without using a decent connection pooled datasource. Sigh, but anyway.)
- If running as ‘producer’, 10 000 process instances will be started, one every 10 milliseconds. Periodically stats will be printed to the console.
- If running as ‘executor’, the process engine is configured to have the async executor enabled.
- There can be an arbitrary number of producers/executors, but all go to the same database.
The process definition used in the project looks as follows:
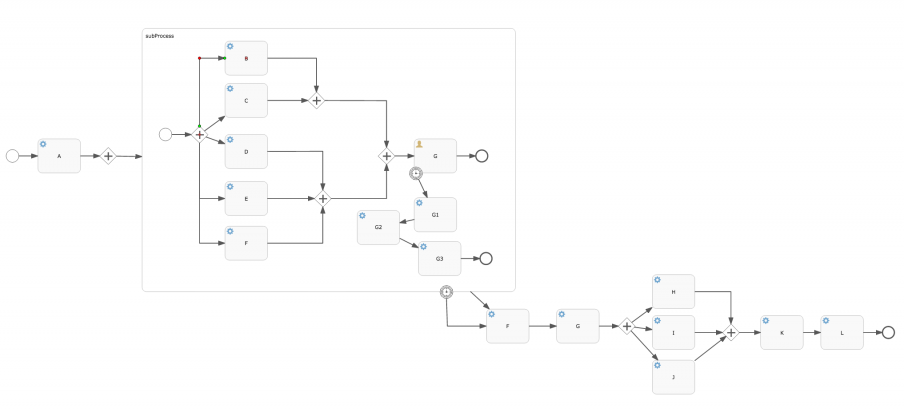
Important to note (and not visible on the diagram) is that all service tasks are asynchronous in this non-trivial process definition. The service tasks after a parallel fork are configured to be exclusive, as are the joining parallel gateways. There are two timers here, where the one on the user task is 1 second and the one on the subprocess is 50 minutes. All in all, when starting a process instance, it leads to 27 jobs needing to be executed to reach the end. For 10 000 instances, this means we’re testing effectively the throughput of 270 000 jobs.
Note that, as with any benchmarks, raw numbers say something but not everything. It all depends on the server hardware, the actual process definitions and many other small bits. Relative numbers however, they do teach us a lot, if the exact same code is being executed on the exact same hardware. Keep that in mind when reading the next sections.
Test environment
All benchmarks were run on Amazon Web Services (AWS), using EC2 servers for the producers/executors and using RDS PostgresQL (as Postgres is an awesome database and very easy to set up) for the database on a r3.4xlarge (16 vCPUs, 122 GiB memory) .
Following EC2 configs were used
- RDS (postgres) : r3.4xlarge (16 vCPUs, 122 GiB memory)
- Producer engine: c3.4xlarge (16 vCPUs, 30 GiB memory)
- Executor engine: c3.8xlarge (32 vCPUs, 60 GiB memory)
All severs ran in the EU-West zone. All test results thus have real network latencies (None of that running on localhost benchmarking and thus skipping networking as often seen online). When running the project above, 8GB was given to the JVM.
The metric we’ll use is throughput of jobs, expressed in jobs/second. Simply said, after test run, we verify the data in the database to be correct (i.e. 10K finished process instances), take the first start time and the last end time which gives us x seconds. The throughput is then x/270000 (as we know each process instance equals to 27 jobs).
Baseline Measurements
The first thing benchmarked was the ‘baseline’, meaning the regular async executor that is backed by a threadpool (i.e. the improved design of the async executor in v5). For this test we used 2 servers, with following configurations (note: 6.0.0.Beta3 here is actually the snapshot version):
| A | B | C | D | |
| Activiti version | 6.0.0.Beta3 | 6.0.0.Beta3 | 6.0.0.Beta3 | 5.21.0 |
| Producer engines | 1 | 1 | 1 | 1 |
| Executor engines | 1 | 1 | 2 | 2 |
| # threads in pool | 32 | 10 | 10 | 10 |
| Blockingqueue size | 256 | 100 | 100 | 100 |
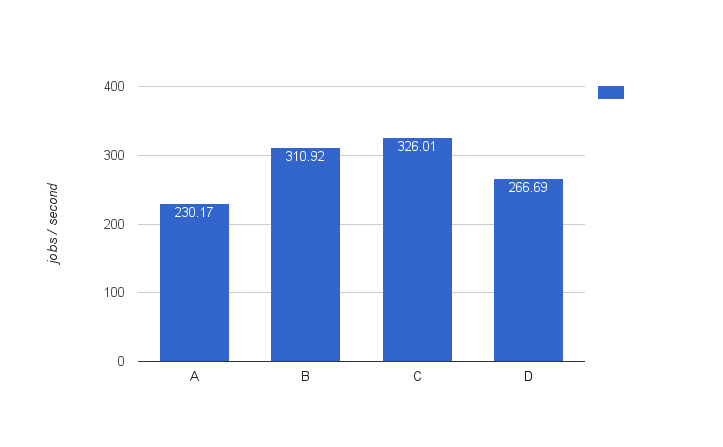
Some interesting observations:
I assumed config A would be better then config B, as the machine had 32 CPU’s after all, so matching the threadpool number of threads with this would make sense. However, config B, which has a very similar setup except only 10 threads and a smaller blockingqueue beats it significantly (310 vs 210 jobs/second). A possible explanation could be that 32 threads is too much contention? I do remember when choosing the default of ’10’ back in the day, we did some benchmarks and 10 was the ‘magic number’ where throughput was best (but I do think it will depend on the machine used.
I expected that adding another executor node would have more impact, after all we’re adding a 32 CPU machine into the mix, but the gain is minimal (310 to 326). We’ll learn why and fix this in a later stage in this article.
Config D, using Activiti version 5.21.0 uses the same setup as config C. However, the improved async executor of version 6 clearly wins here (326 vs 266). Which was of course what we hoped for :-).
So far, our best result is 326 jobs/second (and using two servers).
Variations on the baseline
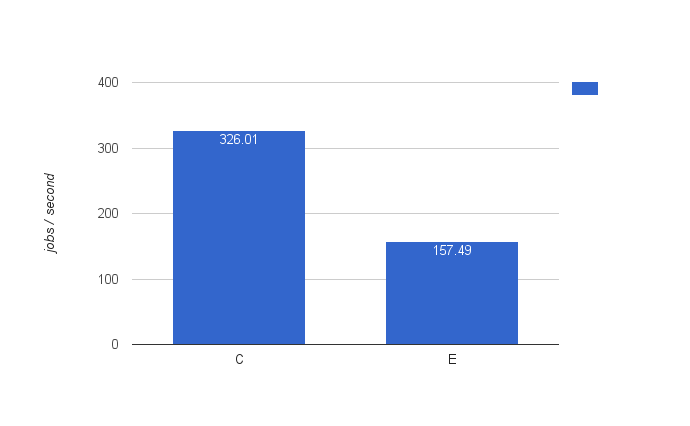
Given the setups above, one can ask what the influence is when running a mixed producer/executor. Which is the default Activiti engine way of running it: the engine will both be responsible for starting process instances and executing them now. This is config E (the same as config C, except both engines are now producers/executors) and the result is shown below. And it’s clearly less performant. One explanation could be that the machine is already using 10 threads to start process instance every 10 ms, which probably leads to quite a bit contention with the 10 threads of the async executor. Probably this setup can be tweaked a lot to get better numbers, but that wasn’t the goal of this blog. But the result is interesting nonetheless.
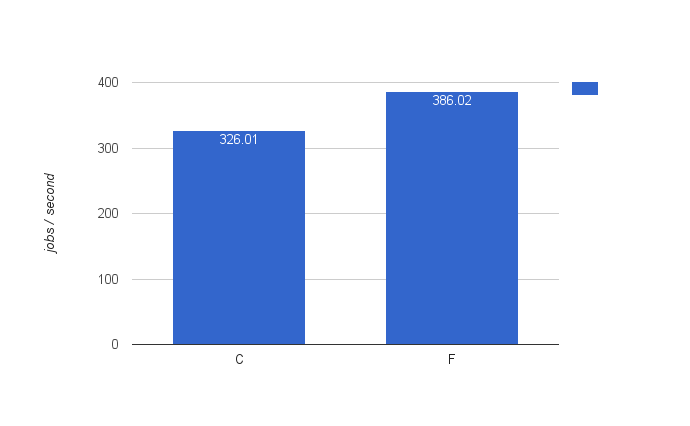
So given that two executor engines were better than one, the logical thing is to try three executors. This is config F.
Similar to going from one to two executors, the throughput goes up. But not in a spectacular linear way.
Introducing the Message Queue based Async Executor
Time to switch to the message queue based async executor, now we have our baseline numbers. I chose the latest version of ActiveMQ, as I’m familiar with it and setting it up is super-easy. I did not spent any time tweaking ActiveMQ, switching persistence strategies or trying alternatives. So there’s probably some margins to gain there too.
In the benchmark project, I used Spring with the following config: https://github.com/jbarrez/queue-based-async-executor-benchmark/blob/master/src/main/java/org/activiti/MyConfigMessageExecutor.java. The reason for going with Spring is that the MessageListenerContainer gives an easy way to have a message queue listener work nicely with multiple threads (which application servers like JBoss would give you otherwise). More specifically, the concurrenConsumers setting of the MessageListenerContainer allows setting the number of threads being used for listening to messages in a smart way. Yes, this class does have a lot of properties that probably can influence the results for the better, but again that was not the point here. Relative numbers, remember.
We’re using a similar setup as config C (our best result so far with two servers), for this config, called config G: 1 producer engine, 2 executor engine. Note that we’re also adding a ‘queue server’ to the mix now, that’s using a c3.8xlarge machine (32 vCPUs, 60 GiB RAM) like the executor engine server.
The results are below … and they are simply awesome: the message queue async executor in a equivalent setup (but with an extra message queue server) is four times faster than the threadpool based async executor.
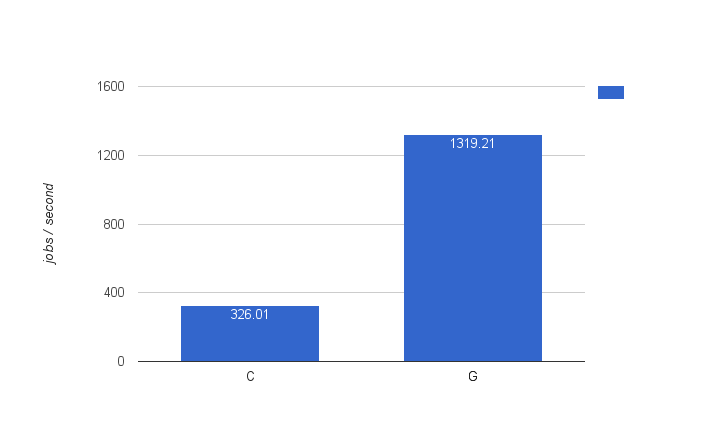
One small implementation note: we had to switch to the UUID ID generator, as the throughput was too high for the default one. Bearing in mind that the UUID generator is slower than the default, the results are even more awesome (as we’re really talking about milliseconds here).
Interesting observations!
If you’d run the benchmark project, you’d see that it periodically spits out some stats so you can follow how many jobs, timers, user tasks, historic activity instances, process instances, etc. are in the system.
While running the message queue setup, one pattern became very clear from these numbers. The threadpool based asyncexecutor was finishing process instances quicker (i.e. after like 1 minute, we saw a batch of process instance being completed), while for the message based async executor, the process instances were practically all finished in one big burst at the end. This indicates that the latter would spread the execution of process instance activities more, while the thread-based would hammer on until one is finished.
Some discussions in the team led to the explanation for this: the threadpool based one will always pass the next async job to the executor, while the message based one puts it on the queue, where already thousands of messages are waiting. Add now the fact that we have quite a bit exclusive async jobs for the process instance, this means that for the threadpool based one, many threads are trying to get the process instance lock, but failing as an exclusive one is being executed. However, the job was unacquired and quickly picked up again. For the message queue based one, they are added again to the end of the message queue. Which has thousand of other messages waiting. When it comes back to executing this particular message, the exclusive lock is most likely already long passed.
This led to some refactoring in the threadpool based async executor: instead of simply releasing the lock on the job, the job is deleted and reinserted, effectively mimicking the queue behavior. This is the fix: https://github.com/Activiti/Activiti/commit/d08a247570336c872bb17ce513c1fb95b3ba47a2#diff-bd9c7efdb4c57462f6fe71641b280942R212.
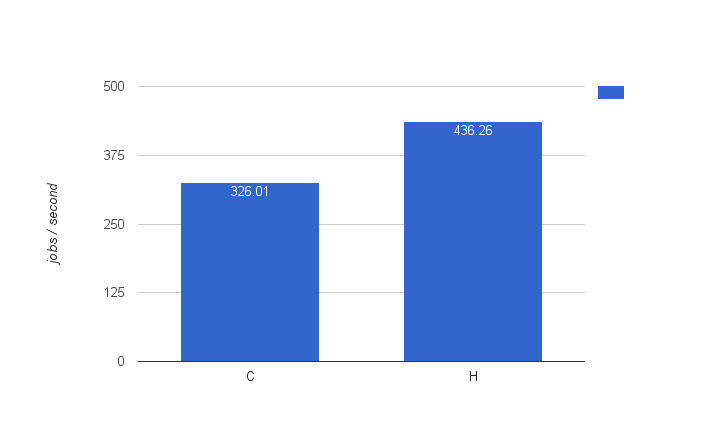
Benchmarking these in an exact same setup as config C, called config H (1 producer, 2 executors), shows us that this simple fix gives a 34% boost to throughput! We now have a new baseline
Even better message queue async executor results
So, in the message queue result (config G), we used a fairly conservative setting of 10 threads for listening to messages. The idea was that we also had 10 threads for the threadpool. Of course, a message queue consumer is fundamentally different from threads that poll: such a consumer has a persistent connection with the queue and the queue broker actually pushes work to its consumers. This should be more efficient. So we’ve tried following configurations, where we vary the amount of consumers (and thus threads used to consume) and executor nodes.
| I | J | K | L | |
| Producer engines | 1 | 1 | 1 | 1 |
| Executor engines | 2 | 2 | 3 | 3 |
| # consumers / engine | 32 | 64 | 32 | 64 |
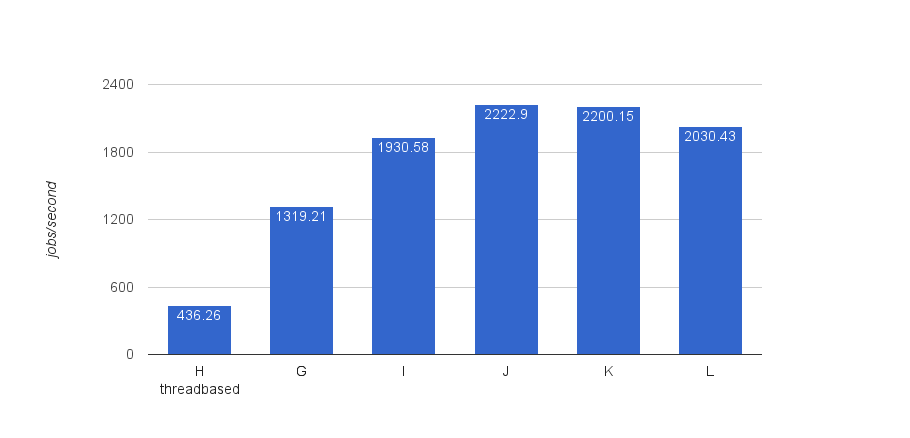
So one nice observation is that adding more consumers is super effective. We’re getting up to a throughput of 2222.9 jobs/second. That is blazingly fast if you ask me, and five times as fast as the threadpool based async executor.
Sadly, adding more executor machines to the mix is actually bad for performance. I think that the bottleneck now becomes the database and how it handles all this concurrency going on at high scale. Of course, I did not tweak the database at all, just a regular RDS postgres instance. Or experiment with Aurora or Oracle (which got the best results in my previous benchmarks). However, the point here was relative numbers, not squeezing out the last bit of throughput. I think the relative number point has been made ��
Conclusions
The numbers speak for themselves: the new message queue based async executor beats the threadpool based async executor hands down. Does this mean you have to switch immediately? No, the regular async executor is also seriously fast (436 jobs/second is still fast), but more importantly, the setup is way simpler, as the Activiti engine takes care of everything. Adding a message queue to your project means additional complexity: another thing that can fail or crash, extra monitoring, maintenance, etc. However, when you’re doing a lot (and I do mean _a lot_) of async jobs, and you’re hitting the limits of what the default async executor can do, it’s nice to know there’s an alternative.
Let’s also not forget the other conclusion made here: the new async executor implementation in version 6 is a major improvement over the version 5 one!
Further Work
The current implementation is Spring/JMS only. However, the implementation is trivial to port to other systems and/or protocols (application servers, STOMP, AMPQ, AWS SQS, etc.). Feedback is appreciated as to what would be a popular next choice ��
Interestingly, this message queue based async executor makes implementing ‘priority queues’ very simple. Priority queues are a feature that many of our large users have asked for: to give certain process definitions/instances/on certain conditions/… priority vs regular jobs. It’s easy to imagine how to set up multiple queues and/or allocate less or more consumers to give certain use cases priority.
| Reference: | Benchmarking the message queue based Activiti Async Executor from our JCG partner Joram Barrez at the Small steps with big feet blog. |
