Itemis did it again: they just released a new very cool plugin for Jetbrains MPS. This one permits to define new tree editors.
They look like this:
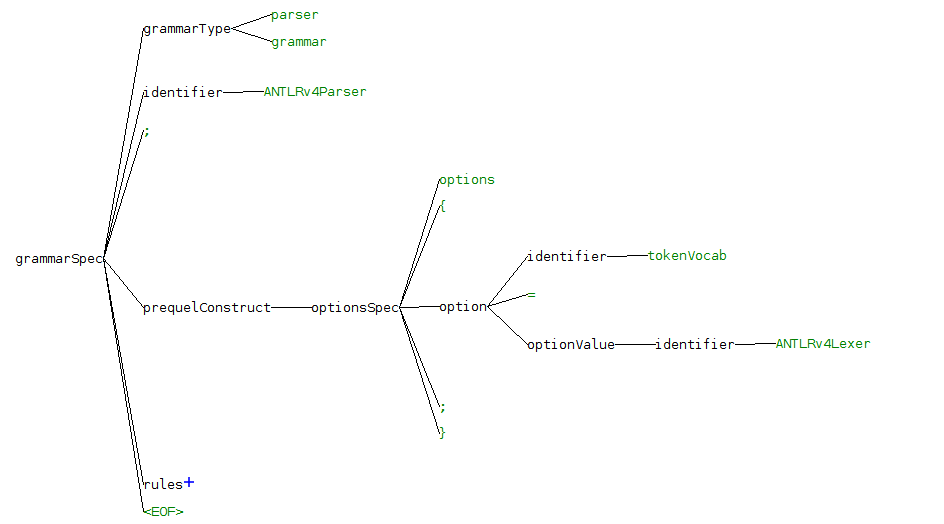
In this post we are going to see:
- how to use ANTLR parsers inside MPS
- how to represent the parsed AST using the tree notation
In particular we are going to use the ANTLR grammar which parses… ANTLR grammars. How meta is that? The very same approach could be used for every ANTLR grammar, of course.
Also always code is is available on GitHub.
Dependencies
First of all you need to install Jetbrains MPS. Grab your free copy here.
To use the tree notations you should install the mbeddr platform. Just go here, download a zip and unzip it among the plugins of your MPS installation.
All set, time to do some programming.
Packaging ANTLR to be used inside MPS
In a previous post we discussed how to use an existing ANTLR grammar in Java projects using Gradle. We will apply that technique also here.
We start by download the grammar from here: https://github.com/antlr/grammars-v4/tree/master/antlr4
We just do some minor changes by including directly LexBasic into ANTLRv4Lexer. Note that we need also the LexerAdaptor.
For simplifying the usage we create a Facade:
package me.tomasetti.mpsantlr.parser;
import me.tomassetti.antlr4.parser.ANTLRv4Lexer;
import me.tomassetti.antlr4.parser.ANTLRv4Parser;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.TokenStream;
import java.io.*;
import java.nio.charset.StandardCharsets;
public class Antlr4ParserFacade {
public ANTLRv4Parser.GrammarSpecContext parseString(String code) {
InputStream inputStream = new ByteArrayInputStream(code.getBytes(StandardCharsets.UTF_8));
return parseStream(inputStream);
}
public ANTLRv4Parser.GrammarSpecContext parseFile(File file) throws FileNotFoundException {
return parseStream(new FileInputStream(file));
}
public ANTLRv4Parser.GrammarSpecContext parseStream(InputStream inputStream) {
try {
ANTLRv4Lexer lexer = new ANTLRv4Lexer(new org.antlr.v4.runtime.ANTLRInputStream(inputStream));
TokenStream tokens = new CommonTokenStream(lexer);
ANTLRv4Parser parser = new ANTLRv4Parser(tokens);
return parser.grammarSpec();
} catch (IOException e) {
throw new RuntimeException("That is unexpected", e);
}
}
}Now we need a build file:
buildscript {
repositories {
maven {
name 'JFrog OSS snapshot repo'
url 'https://oss.jfrog.org/oss-snapshot-local/'
}
jcenter()
}
}
repositories {
mavenCentral()
jcenter()
}
apply plugin: 'java'
apply plugin: 'antlr'
apply plugin: 'idea'
dependencies {
antlr "org.antlr:antlr4:4.5.1"
compile "org.antlr:antlr4-runtime:4.5.1"
testCompile 'junit:junit:4.12'
}
generateGrammarSource {
maxHeapSize = "64m"
arguments += ['-package', 'me.tomassetti.antlr4.parser']
outputDirectory = new File("${project.buildDir}/generated-src/antlr/main/me/tomassetti/antlr4/parser".toString())
}
task fatJar(type: Jar) {
manifest {
attributes 'Implementation-Title': 'Antlr4-Parser',
'Implementation-Version': '0.0.1'
}
baseName = project.name + '-all'
from { configurations.compile.collect { it.isDirectory() ? it : zipTree(it) } }
with jar
}You may want to run:
- gradle idea to create a Jetbrains IDEA project
- gradle fatJar to create a Jar which will contain our compiled code and all the dependencies
Good. Now to use this parser into MPS we start by creating a project. In the wizard we select also the runtime and sandbox options. Once we have done that we should copy our fat jar under the models directory of the runtime solution. In my case I run from the directory of the Java project this command:
cp build/libs/parser-all.jar ../languages/me.tomassetti.mpsantlr/runtime/models/
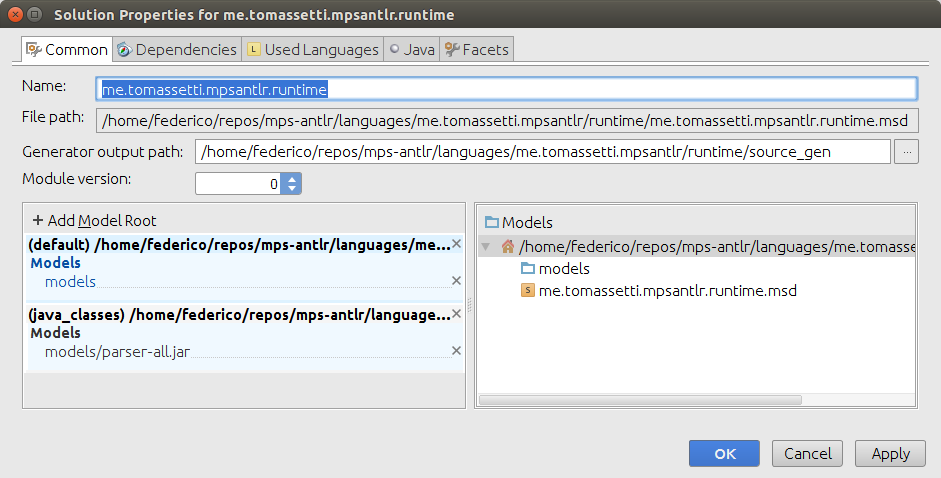
Then we add it also to the libraries:
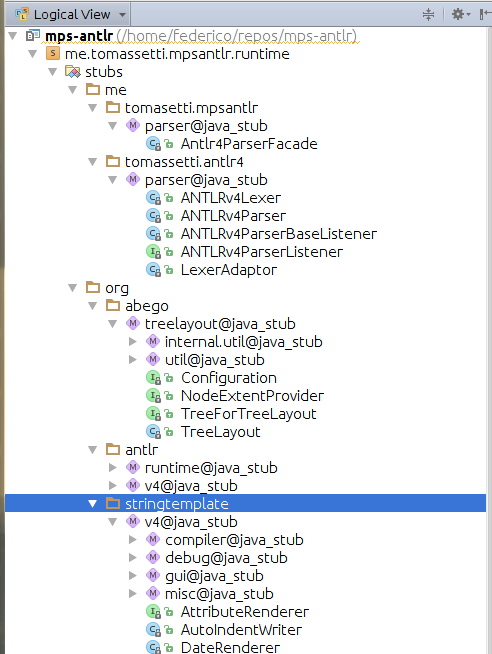
Now the content of the JAR should appear among the stubs of the runtime solution.
Creating MPS nodes from AST nodes
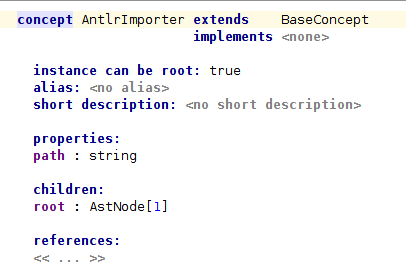
Now we are going to build a new concept named AntlrImporter. We will use it to select and import ANTLR grammars into MPS:
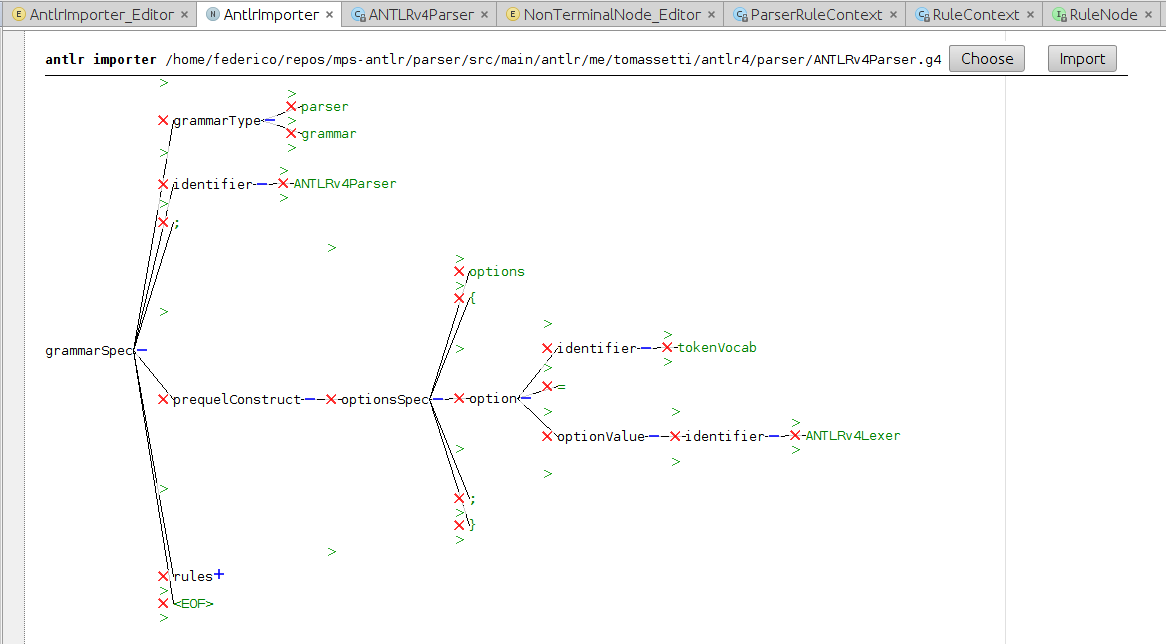
The Concept structure will be pretty simple:
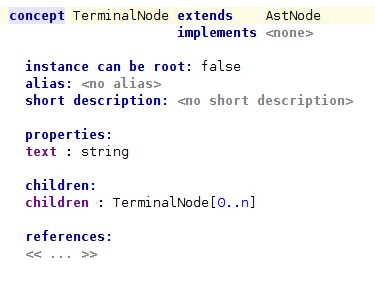
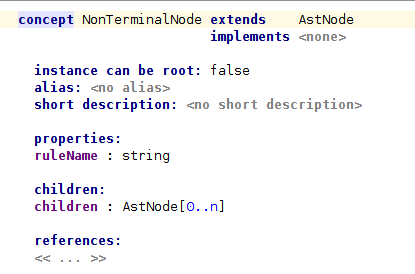
We need also concepts for the AST nodes we are going to import. First of all, we will define the abstract concept AstNode. Then we will define two subconcepts for the terminal and non-terminal AST nodes.
Now let’s take a look at the editor for the AntlrImporter.
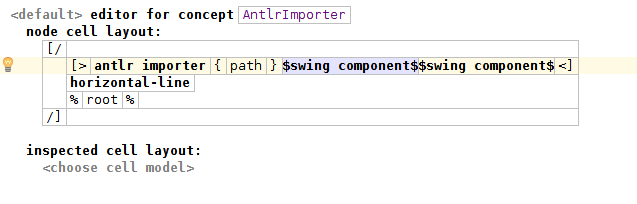
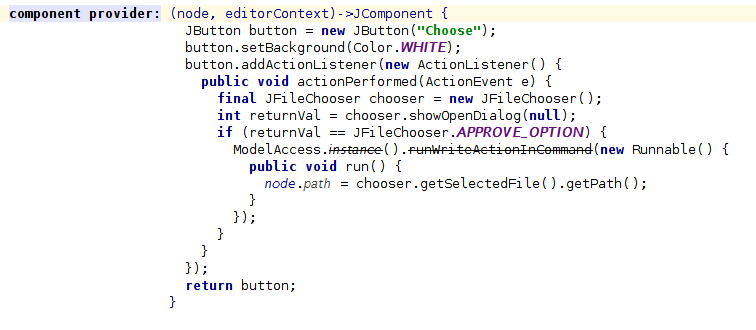
The first swing component is a button which opens a file chooser. In this way, we can easily select a file and set the property path. Or we can edit it manually if we prefer.
Once we have selected a File we can import it by clicking on the second button
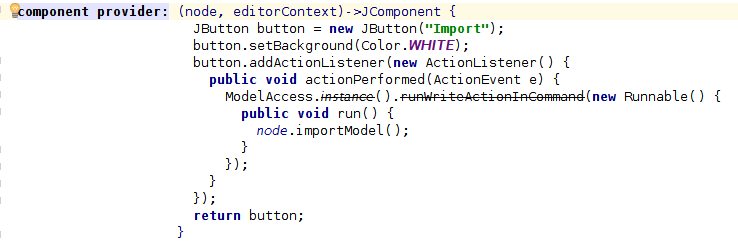
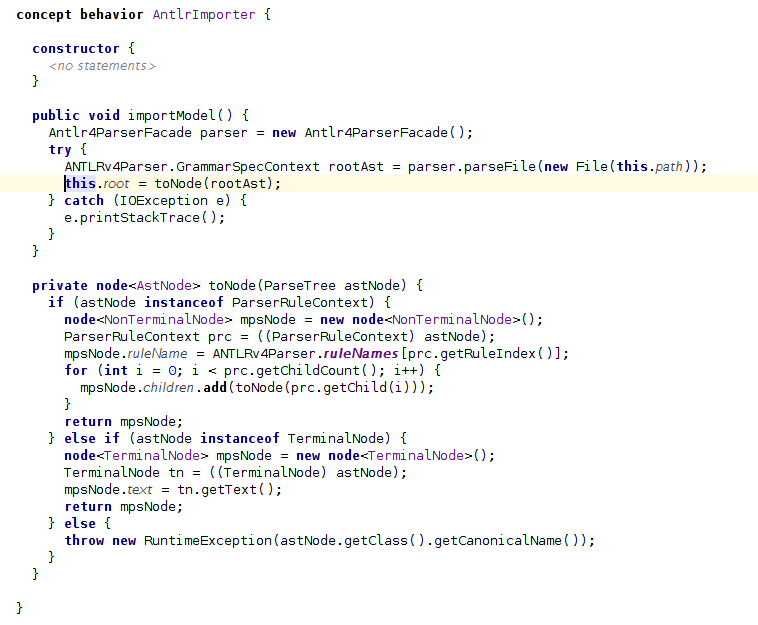
The import logic is in importModel, a method in the behavior of AntlrImporter.
Good. That is it. With that we can parse any ANTLR grammar and get it into MPS. Now we have just to use a nice representation. We are going for the tree notation.
Using the tree notation
The tree notation is surprising easily to use.
Let’s start by adding com.mbeddr.mpsutil.treenotation.styles.editor to the dependencies of the editor aspect of our language.
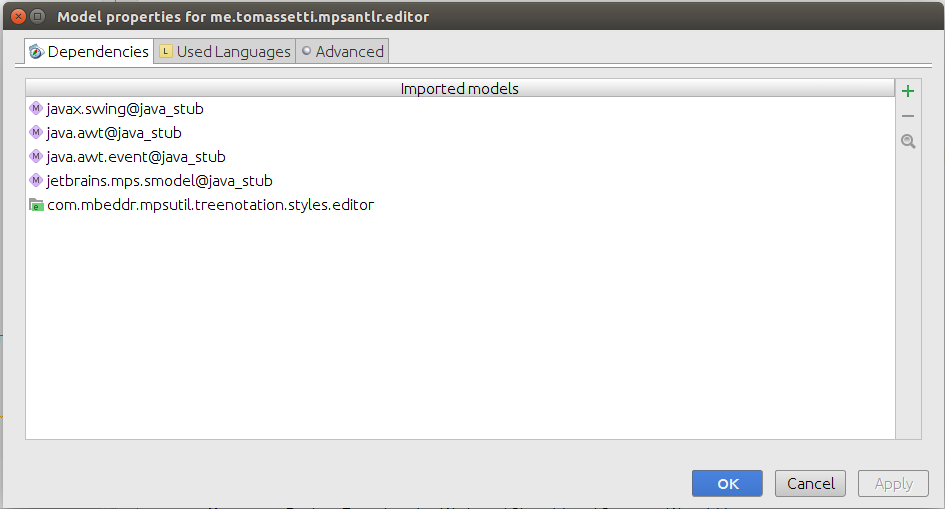
We will need also the com.mbeddr.mpsutil.treenotation to be among the used languages.
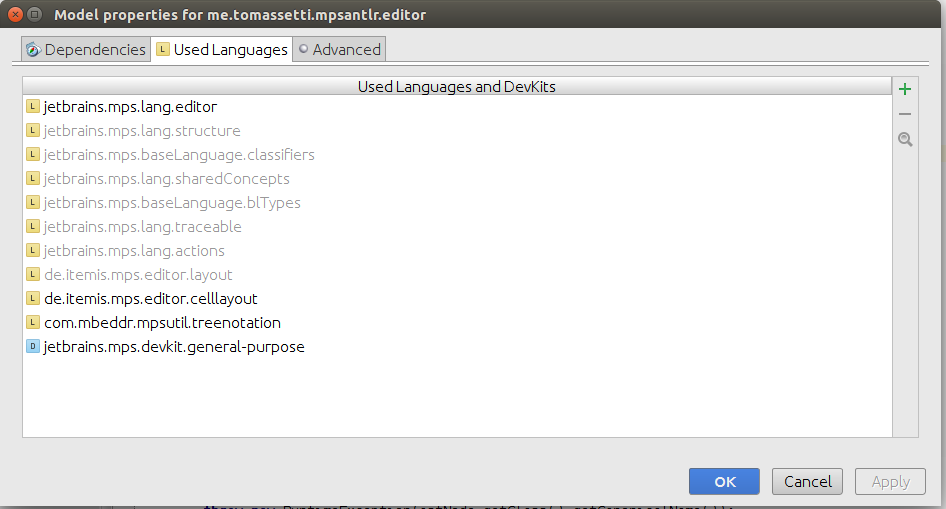
The editor for NonTerminalNode consists of a single tree cell. The top part of the tree cell represents this node. We will use the ruleName to represent it. In the bottom part instead we should pick the relation contains the children to be displayed in the tree
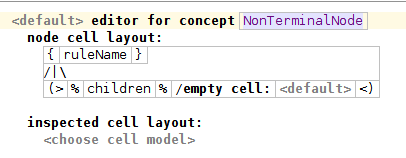
We can put the cursor on the tree drawing between the top and the bottom part (the “/|\” symbol) and open the inspector. There we can use style attributes to customize the appearance of the tree

We just decide to show the tree from left-to-right instead that top down. Then we decide to add more spaces between the parent and the children when there are too many children. In this way the lines to not overlap too much.
This is how it looks without the property

This is how it looks with the property set
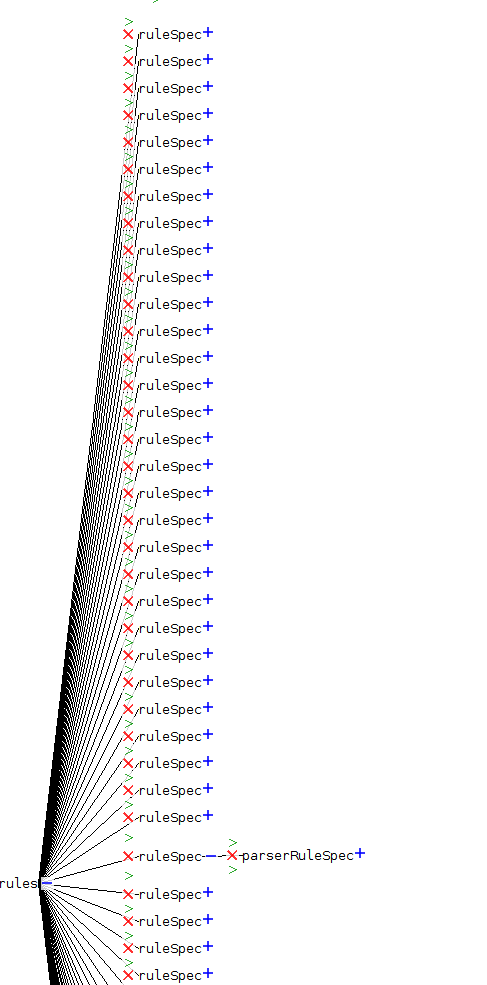
There are other properties that can be used to control the color and the thickness of the lines, for example. Or you could add shapes at the extremes of the lines. For now we do not need these features, but it is nice to know they are there.
The editor for TerminalNode is very simple

Conclusions
Over the years MPS became more stable and easier to use. It has reached the point at which you can be very productive using it. Projectional editing is an idea that has been around for a while and there are other implementations available like the Whole Platform. However MPS has reached a very high level of maturity.
What I think we still miss are:
- processes and best practices: how should we manage dependencies with other MPS projects? How should we integrate with Java libraries?
- examples: there are surprisingly few applications which are publicly available. After all, many users develop DSLs for their specific usages and do not intend to share them. However, this means we have few opportunities to learn from each other
- extensions: the Mbeddr team is doing an amazing job providing a lot of goodies as part of the Mbeddr platform. However, they seem the only ones producing reusable components and sharing them
I think this is now time to understand together what we can achieve with projectional editing. In my opinion these are going to be very interesting times.
If I have to express one wish is that I would like to hear more about how others are using MPS. If you are out there, please knock. And leave a comment
| Reference: | ANTLR and Jetbrains MPS: Parsing files and display the AST usign the tree notation from our JCG partner Federico Tomassetti at the Federico Tomassetti blog. |
