In this Post:
- What is JLBH
- Why did we write JLBH
- Differences between JMH and JLBH
- Quick start guide
What is JLBH?
JLBH is a tool that can be used to measure latency in Java programs. It has these features:
- Aimed at running code that would be larger than a micro benchmark.
- Suitable for programs that use asynchronous activity like the producer consumer pattern.
- Ability to benchmark individual points within the program
- Ability to adjust the throughput into the benchmark
- Adjusts for coordinated omission i.e. end to end latencies of iterations impact each other if they back up
- Reports and runs its own jitter thread
Why did we write JLBH?
JLBH was written because we needed a way of benchmarking Chronicle-FIX. We created it to benchmark and diagnose issues in our software. It has proved extremely useful and it is now available in the Chronicle open source libraries.
Chronicle-FIX is an ultra low latency Java fix engine. It guarantees latencies, for example, that parsing a NewOrderSingle message into the object model will not exceed 6us all the way to the 99.9th percentile. In fact we needed measure all the way along the percentile range.
This is latency / percentile typical profile.
50 -> 1.5us 90 -> 2us 99 -> 2us 99.9 -> 6us 99.99 -> 12us 99.999 -> 35us Worst -> 500us
Chronicle Fix guarantees these latencies with various throughputs ranging from 10k messages / second to 100k messages / second. So we needed a test harness where we could easily vary the throughput.
We also needed to account for co-ordinated omission. In other words we couldn’t just ignore the effect of a slow run on the following run. If run A was slow and that caused run B to be delayed, even if run B had no latency in its own run, that fact that it was delayed still had to be recorded.
We needed to try to differentiate between OS jitter, JVM jitter, and jitter caused by our own code. For that reason we added the option to have a jitter thread that did nothing but sample jitter in the JVM. This would show up a combination of OS jitter e.g. thread scheduling and general OS interrupts and global JVM events such as GC pauses.
We needed to attribute the latencies as best possible to individual routines or even lines of code, for this reason we also created the possibility of adding custom sampling into the program. The addition of NanoSamplers adds very little overhead to the benchmark and allows you to observe where your program introduces latency.
This is a schematic view of the benchmark we constructed to measure Chronicle-FIX.
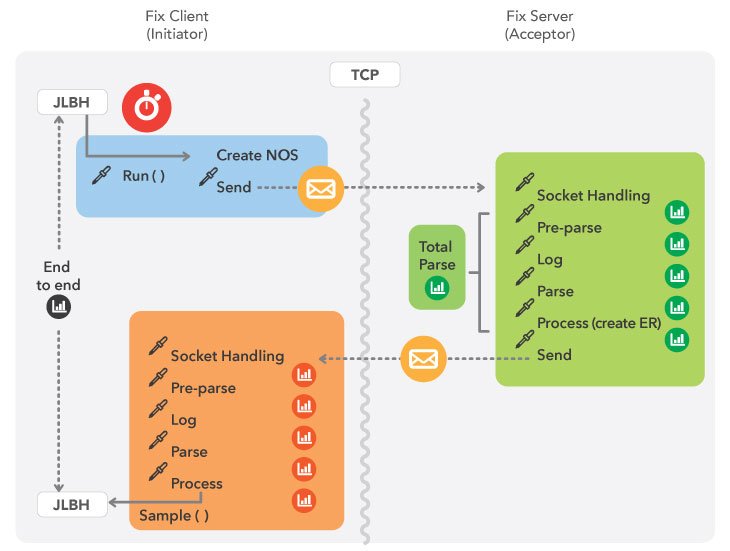
We ended up with results like these:
This was typical run:
Run time: 100.001s Correcting for co-ordinated:true Target throughput:50000/s = 1 message every 20us End to End: (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 11 / 15 17 / 20 121 / 385 - 541 Acceptor:1 init2AcceptNetwork (4,998,804) 50/90 99/99.9 99.99/99.999 - worst was 9.0 / 13 15 / 17 21 / 96 - 541 Acceptor:1.1 init2AcceptorNetwork(M) (1,196) 50/90 99/99.9 99.99 - worst was 22 / 113 385 / 401 401 - 401 Acceptor:2 socket->parse (4,998,875) 50/90 99/99.9 99.99/99.999 - worst was 0.078 / 0.090 0.11 / 0.17 1.8 / 2.1 - 13 Acceptor:2.0 remaining after read (20,649,126) 50/90 99/99.9 99.99/99.999 99.9999/worst was 0.001 / 0.001 0.001 / 0.001 0.001 / 1,800 3,600 / 4,590 Acceptor:2.1 parse initial (5,000,100) 50/90 99/99.9 99.99/99.999 - worst was 0.057 / 0.061 0.074 / 0.094 1.0 / 1.9 - 4.7 Acceptor:2.5 write To Queue (5,000,100) 50/90 99/99.9 99.99/99.999 - worst was 0.39 / 0.49 0.69 / 2.1 2.5 / 3.4 - 418 Acceptor:2.9 end of inital parse (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.17 / 0.20 0.22 / 0.91 2.0 / 2.2 - 7.6 Acceptor:2.95 on mid (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.086 / 0.10 0.11 / 0.13 1.4 / 2.0 - 84 Acceptor:3 parse NOS (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.33 / 0.38 0.41 / 2.0 2.2 / 2.6 - 5.5 Acceptor:3.5 total parse (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 1.1 / 1.2 1.8 / 3.0 3.5 / 5.8 - 418 Acceptor:3.6 time on server (4,998,804) 50/90 99/99.9 99.99/99.999 - worst was 1.1 / 1.2 1.8 / 3.1 3.8 / 6.0 - 418 Acceptor:4 NOS processed (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.21 / 0.23 0.34 / 1.9 2.1 / 2.8 - 121 Jitter (5,000,000) 50/90 99/99.9 99.99/99.999 - worst was 0.035 / 0.035 0.035 / 0.037 0.75 / 1.1 - 3.3 OS Jitter (108,141) 50/90 99/99.9 99.99 - worst was 1.2 / 1.4 2.5 / 4.5 209 - 217
All samples are summarised across runs at the end of the benchmark here are couple:
-------------------------------- SUMMARY (Acceptor:2.95 on mid)---------------------- Percentile run1 run2 run3 run4 run5 % Variation var(log) 50: 0.09 0.09 0.09 0.09 0.09 0.00 3.32 90: 0.10 0.10 0.10 0.10 0.10 0.00 3.58 99: 0.11 0.11 0.11 0.11 0.11 2.45 3.69 99.9: 0.13 0.13 0.62 0.78 0.13 76.71 6.01 99.99: 1.50 1.38 1.82 1.89 1.70 19.88 9.30 worst: 1.95 2.02 2.11 2.24 2.24 6.90 9.90 ------------------------------------------------------------------------------------- -------------------------------- SUMMARY (Acceptor:3 parse NOS)---------------------- Percentile run1 run2 run3 run4 run5 % Variation var(log) 50: 0.33 0.33 0.34 0.36 0.36 6.11 5.75 90: 0.38 0.38 0.46 0.46 0.46 12.42 6.24 99: 0.41 0.41 0.50 0.53 0.50 16.39 6.47 99.9: 2.11 2.02 2.11 2.11 2.11 3.08 9.76 99.99: 2.37 2.24 2.37 2.37 2.37 3.67 10.05 worst: 2.88 2.62 3.14 3.14 2.88 11.51 10.67 -------------------------------------------------------------------------------------
Using JLBH we were able to both benchmark our application against the criteria in the specification as well as diagnosing some of the latency spikes.
By varying the throughput and the run time of the benchmark and especially by adding sampling to various points in the code patterns started to emerge which lead us to the source of the latency. A particular example of this was an issue with DateTimeFormatter casing a TLB cache miss but that will be the subject of another post.
Differences between JMH and JLBH
I would expect most of those reading this article to be familiar with JMH (Java MicroBenchmarking Harness), this is an excellent tool for micro benchmarks and if you haven’t already used it it’s a worthwhile tool every Java developer should have in their locker. Especially those concerned with measuring latencies.
As you will see from JLBH design much of it was inspired by JMH.
So if JMH is so great why did we have to create another benchmark harness?
I guess at a high level the answer is in the name. JMH is squarely aimed at micro benchmarks whilst JLBH is there to find latencies in larger programs.
But it’s not just that. After reading the last section you will see that there are a number of reasons you might want to choose JLBH over JMH for a certain class of problem.
Btw although you can always use JLBH instead of JMH, if you have a genuine micro benchmark that you want measured as cleanly and as exactly as possible I would always recommend you use JMH over JLBH. JMH is an extremely sophisticated tool and does what it does really well for example JMH forks JVMs for each run which at the present moment JLBH does not.
When you would use JLBH over JMH:
- If you want to see your code running in context. The nature of JMH is to take a very small sample of your code, let’s say in the case of a FIX engine just the parsing, and time it in isolation. In our tests the exact same fix parsing took over twice as long when run in context i.e. as part of the fix engine, as they did when run out of context i.e. in a micro benchmark. I have a good example of that in my Latency examples project DateSerialise where I demonstrate that serialising a Date object can take twice as long when run inside a TCP call. The reason for this is all to do with CPU caches and something we will return to in a later blog.
- If you want to take into account coordinated omission. In JMH, by design, all iterations are independent of each other, so if one iteration of the code is slow it will have no effect on the next one. We can see a good example of this in the my Latency examples SimpleSpike where we see the huge effect that accounting for coordinated omission can have. Real world examples should almost always be measured when accounting for coordinated omission.
For example let’s imagine you are waiting for a train and get delayed in the station for an hour because the train in front of you was late. Let’s then imagine you get on the train an hour late and the train takes it’s usual half an hour to reach it’s destination. If you don’t account for coordinated omission you will not consider yourself to have suffered any delay as your journey took exactly the correct amount of time even though you waited for an hour at the station before departing! - If you want to vary throughput into your test. JLBH allows you to set the throughput as a parameter to your benchmark. The truth is that latency makes little sense without a defined throughput so it’s extremely important that you are able to see the results of varying the throughput on your latency profile. JMH does not allow you to set throughput. (In fact this goes hand in hand with the fact that JMH does not account for coordinated omission.)
- You want to be able to sample various points within your code. An end to end latency is great as a start but then what? You need to be able to record a latency profile for many points within the code. With JLBH you can add probes into your codes wherever you choose at very little overhead to the program. JMH is designed so that you only measure from the start of your method (@Benchmark) to the end.
- You want to measure OS and JVM global latencies. JLBH runs a separate jitter thread. This runs in parallel to your program and does nothing but sample latency by repeatedly calling System.nanoTime(). Whilst this doesn’t in of itself tell you all that much it can be indicative as to what is going on side your JVM during the time of the benchmark. Additionally you can add a probe which does nothing (this will be explained later on) where you can sample latency inside the thread that runs the code you are benchmarking. JMH does not have this sort of functionality.
As I mentioned earlier, if you don’t want to use one or more of these functionalities than favour JMH over JLBH.
Quick Start Guide
The code for JLBH can be found in Chronicle-Core library which can be found on GitHub over here.
To download from Maven-Central include this in your pom.xml (check the latest version):
<dependency>
<groupId>net.openhft</groupId>
<artifactId>chronicle-core</artifactId>
<version>1.4.7</version>
</dependency>To write a benchmark you have implement the JLBHTask interface:
It has just two methods you need to implement:
- init(JLBH jlbh) you are passed a reference to JLBH which you will need to call back on (jlbh.sampleNanos()) when your benchmark is complete.
- run(long startTime) the code to run on each iteration. You will need to retain the start time when you work out how long your benchmark has taken and call back on jlbh.sampleNanos(). JLBH counts the number of times sampleNanos() is called and it must exactly match the number of times run() is called. This is not the case for other probes you can create.
- There is third optional method complete()that might be useful for cleanup for certain benchmarks.
All this is best seen in a simple example:
In this case we measure how long it takes to put an item on an ArrayBlockingQueue and to take it off again.
We add probes to see how long the call to put() and poll() take.
I would encourage you to run this varying the throughput and the size of the ArrayBlockingQueue and see what difference it makes.
You can also see the difference it makes if you set accountForCoordinatedOmission to true or false.
package org.latency.prodcon;
import net.openhft.chronicle.core.jlbh.JLBH;
import net.openhft.chronicle.core.jlbh.JLBHOptions;
import net.openhft.chronicle.core.jlbh.JLBHTask;
import net.openhft.chronicle.core.util.NanoSampler;
import java.util.concurrent.*;
/**
* Simple test to demonstrate how to use JLBH
*/
public class ProducerConsumerJLBHTask implements JLBHTask {
private final BlockingQueue<Long> queue = new ArrayBlockingQueue(2);
private NanoSampler putSampler;
private NanoSampler pollSampler;
private volatile boolean completed;
public static void main(String[] args){
//Create the JLBH options you require for the benchmark
JLBHOptions lth = new JLBHOptions()
.warmUpIterations(40_000)
.iterations(100_000)
.throughput(40_000)
.runs(3)
.recordOSJitter(true)
.accountForCoordinatedOmmission(true)
.jlbhTask(new ProducerConsumerJLBHTask());
new JLBH(lth).start();
}
@Override
public void run(long startTimeNS) {
try {
long putSamplerStart = System.nanoTime();
queue.put(startTimeNS);
putSampler.sampleNanos(System.nanoTime() - putSamplerStart);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void init(JLBH lth) {
putSampler = lth.addProbe("put operation");
pollSampler = lth.addProbe("poll operation");
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.submit(()->{
while(!completed) {
long pollSamplerStart = System.nanoTime();
Long iterationStart = queue.poll(1, TimeUnit.SECONDS);
pollSampler.sampleNanos(System.nanoTime() - pollSamplerStart);
//call back JLBH to signify that the iteration has ended
lth.sample(System.nanoTime() - iterationStart);
}
return null;
});
executorService.shutdown();
}
@Override
public void complete(){
completed = true;
}
}Take a look look at all the options with which you can set up your JLBH benchmark which are contained in JLBHOptions.
In the next post we will look at some more examples of JLBH benchmarks.
Please let me know if you have any feedback on JLBH – if you want to contribute feel free to fork Chronicle-Core and issue a pull request!
| Reference: | JLBH – Introducing Java Latency Benchmarking Harness from our JCG partner Daniel Shaya at the Rational Java blog. |
