While trying to get Java to #1 in the regexdna challenge for The Computer Language Benchmarks Game I was researching the performance of regular expression libraries for Java. The most recent website I could find was tusker.org from 2010. Hence I decided to redo the tests using the Java Microbenchmarking Harness and publish the results (spoiler alert: I got Java to #1 by some unorthodox solutions).
TL;DR: regular expressions are good for ad-hoc querying but if you have something performance sensitive, you should hand-code your solution (this doesn’t mean that you have to start from absolute zero – the Google Guava library has for example some nice utilities which can help in writing readable but also performant code).
And now, for some charts summarizing the performance – the test was run on an 64bit Ubuntu 15.10 machine with OpenJDK 1.8.0_66:
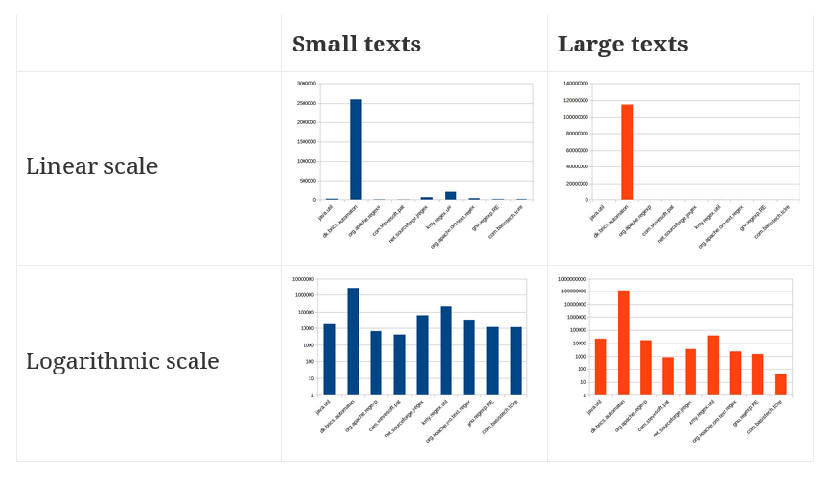
Observations
- there is no “standard” for regular expressions, so different libraries can behave differently when given a particular regex and a particular string to match against – ie. one might say that it matches but the other might say that it doesn’t. For example, even though I used a very reduced set of testcases (5 regexes checked against 6 strings), only two of the libraries managed to match / not match them all correctly (one of them being java.util.Pattern).
- it probably takes more than one try to get your regex right (tools like regexpal or The Regex Coach are very useful for experimenting)
- the performance of a regex is hard to predict (and sometimes it can have exponential complexity based on the input length) – because of this you need to think twice if you accept a regular expression from arbitrary users on the Internet (like a search engine which would allow search by regular expressions for example)
- none of the libraries seems to be in active development any more (in fact quite a few from the original list on tusker.org are now unavailable) and many of them are slower than the built-in j.u.Pattern, so if you use regexes that should probably be the first choice.
- that said, the performance of both the hardware and JVM has been considerable, so if you are using one of these libraries, it is running generally an order of magnitude faster than it was five years ago. So there is no need to quickly replace working code (unless your profiler says that it is a problem :-))
- watch out for calls to String.split in loops. While it has some optimization for particular cases (such as one-char regexes), you should almost always:
- see if you can use something like Splitter from Google Guava
- if you need a regular expression, at least pre-compile it outside of the loop
- the two surprises were dk.brics.automaton which outperformed everything else by several orders of magnitude, however:
- the last release was in 2011 and seems to be more an academic project
- it doesn’t support the same syntax as java.util.Pattern (but doesn’t give you a warning if you try to use a j.u.Pattern – it just won’t match the strings you think it should)
- doesn’t have an API as comfortable as j.u.Pattern (for example it’s missing replacements)
- the other surprise was kmy.regex.util.Regex, which – although not updated since 2000 – outperformed java.util.Pattern and passed all the tests (of which there weren’t admittedly many).
The complete list of libraries used:
| Library name and version (release year) | Available in Maven Central | License | Average ops/second | Average ops/second (large text) | Passing tests |
|---|---|---|---|---|---|
| j.util.Pattern 1.8 (2015) | no (comes with JRE) | JRE license | 19 689 | 22 144 | 5 out of 5 |
| dk.brics.automaton.Automaton 1.11-8 (2011) | yes | BSD | 2 600 225 | 115 374 276 | 2 out of 5 |
| org.apache.regexp 1.4 (2005) | yes | Apache (?) | 6 738 | 16 895 | 4 out of 5 |
| com.stevesoft.pat.Regex 1.5.3 (2009) | yes | LGPL v3 | 4 191 | 859 | 4 out of 5 |
| net.sourceforge.jregex 1.2_01 (2002) | yes | BSD | 57 811 | 3 573 | 4 out of 5 |
| kmy.regex.util.Regex 0.1.2 (2000) | no | Artistic License | 217 803 | 38 184 | 5 out of 5 |
| org.apache.oro.text.regex.Perl5Matcher 2.0.8 (2003) | yes | Apache 2.0 | 31 906 | 2383 | 4 out of 5 |
| gnu.regexp.RE 1.1.4 (2005?) | yes | GPL (?) | 11 848 | 1 509 | 4 out of 5 |
| com.basistech.tclre.RePattern 0.13.6 (2015) | yes | Apache 2.0 | 11 598 | 43 | 3 out of 5 |
| com.karneim.util.collection.regex.Pattern 1.1.1 (2005?) | yes | ? | – | – | 2 out of 5 |
| org.apache.xerces.impl.xpath.regex.RegularExpression 2.11.0 (2014) | yes | Apache 2.0 | – | – | 4 out of 5 |
| com.ibm.regex.RegularExpression 1.0.2 (no longer available) | no | ? | – | – | – |
| RegularExpression.RE 1.1 (no longer available) | no | ? | – | – | – |
| gnu.rex.Rex ? (no longer available) | no | ? | – | – | – |
| monq.jfa.Regexp 1.1.1 (no longer available) | no | ? | – | – | – |
| com.ibm.icu.text.UnicodeSet (ICU4J) 56.1 (2015) | yes | ICU License | – | – | – |
If you want to re-run the tests, check out the source code and run it as follows:
# we need to skip tests since almost all libraries fail a test or an other mvn -Dmaven.test.skip=true clean package # run the benchmarks java -cp lib/jint.jar:target/benchmarks.jar net.greypanther.javaadvent.regex.RegexBenchmarks
And finally, what about the regexdna challenge for The Computer Language Benchmarks Game? I got Java to #1 by using bit operations to check blocks of 8 bytes if they are potential matches and only then test them against the regular expressions. As I said earlier: if you want performance, you need to write your custom parsers.
| Reference: | Java regular expression library benchmarks – 2015 from our JCG partner Attila Mihaly Balazs at the Java Advent Calendar blog. |

A couple of years ago I found the fastest solution for long strings (1-2MB) was to use RE2 C++ library. I have modified, working bindings for it at https://github.com/Szumo/re2-java
Hey Attila,
I just developed an API-compatible reimplementation of java.util.regex; maybe you want to include that in your comparison? I yielded about a 300% performance improvement for the “Mark Twain” regex performance test suite.
CU Arno