This article is part of our Academy Course titled Java Concurrency Essentials.
In this course, you will dive into the magic of concurrency. You will be introduced to the fundamentals of concurrency and concurrent code and you will learn about concepts like atomicity, synchronization and thread safety. Check it out here!
Table Of Contents
1. Introduction
This article discusses the topic of performance for multi-threaded applications. After defining the terms performance and scalability, we take a closer look at Amdahl’s Law. Further in the course we see how we can reduce lock contention by applying different techniques, which are demonstrated with code examples.
2. Performance
Threads can be used to improve the performance of applications. The reason behind this may be that we have multiple processors or CPU cores available. Each CPU core can work on its own task, hence dividing on big task into a series of smaller tasks that run independently of each other, can improve the total runtime of the application. An example for such a performance improvement could be an application that resizes images that lie within a folder structure on the hard disc. A single threaded approach would just iterate over all files and scale each image after the other. If we have a CPU with more than one core, the resizing process would only utilize one of the available cores. A multi-threaded approach could for example let a producer thread scan the file system and add all found files to a queue, which is processed by a bunch of worker threads. When we have as many worker threads as we have CPU cores, we make sure that each CPU core has something to do until all images are processed.
Another example where multi-threading can improve the overall performance of an application are use cases with a lot of I/O waiting time. Let’s assume we want to write an application that mirrors a complete website in form of HTML files to our hard disc. Starting with one page, the application has to follow all links that point to the same domain (or URL part). As the time between issuing the request to the remote web server up to the moment until all data has been received may be long, we can distribute the work over a few threads. One or more threads can parse the received HTML pages and put the found links into a queue, while other threads issue the requests to the web server and then wait for the answer. In this case we use the waiting time for newly requested pages with the parsing of the already received ones. In contrast to the previous example, this application may even gain performance if we add more threads than we have CPU cores.
These two examples show that performance means to get more work done in a shorter time frame. This is of course the classical understanding of the term performance. But the usage of threads can also improve the responsiveness of our applications. Imagine as simple GUI application with an input form and a “Process” button. When the user presses the button, the application has to render the pressed button (the button should lock like being pressed down and coming up again when releasing the mouse) and the actual processing of the input data has to be done. If this processing takes longer, a single threaded application could not react to further user input, i.e. we need an additional thread that processes events from the operating system like mouse clicks or mouse pointer movements.
Scalability means the ability of a program to improve the performance by adding further resources to it. Imagine we would have to resize a huge amount of images. As the number of CPU cores of our current machine is limited, adding more threads does not improve the performance. The performance may even degrade as the scheduler has to manage more threads and thread creation and shutdown also costs CPU power.
2.1. Amdahl’s Law
The last section has shown that in some cases the addition of new resources can improve the overall performance of our application. In order to able to compute how much performance our application may gain when we add further resources, we need to identify the parts of the program that have to run serialized/synchronized and the parts of the program that can run in parallel. If we denote the fraction of the program that has to run synchronized with B (e.g. the number of lines that are executed synchronized) and if we denote the number of available processors with n, then Amdahl’s Law lets us compute an upper limit for the speedup our application may be able to achieve:
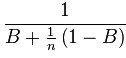
If we let n approach infinity, the term (1-B)/n converges against zero. Hence we can neglect this term and the upper limit for the speedup converges against 1/B, where B is the fraction of the program runtime before the optimization that is spent within non-parallelizable code. If B is for example 0.5, meaning that half of the program cannot be parallelized, the reciprocal value of 0.5 is 2; hence even if we add an unlimited number of processor to our application, we would only gain a speedup of about two. Now let’s assume we can rewrite the code such that only 0.25 of the program runtime is spent in synchronized blocks. Now the reciprocal value of 0.25 is 4, meaning we have built an application that would run with a large number of processors about four times faster than with only one processor.
The other way round, we can also use Amdahl’s Law to compute the fraction of the program runtime that has to be executed synchronized to achieve a given speedup. If we want to achieve a speedup of about 100, the reciprocal value is 0.01, meaning we should only spent about 1 percent of the runtime within synchronized code.
To summarize the findings from Amdahl’s Law, we can conclude that the maximum speed up a program can get through the usage of additional processor is limited by the reciprocal value of the fraction of time the program spends in synchronized code parts. Although it is not always easy to compute this fraction in practice, even not if you think about large business applications, the law gives us a hint that we have to think about synchronization very carefully and that we have to keep the parts of the program runtime small, that have to be serialized.
2.2. Performance impacts of threads
The writings of this article up to this point indicate that adding further threads to an application can improve the performance and responsiveness. But on the other hand, this does not come for free. Threads always have some performance impact themselves.
The first performance impact is the creation of the thread itself. This takes some time as the JVM has to acquire the resources for the thread from the underlying operating system and prepare the data structures in the scheduler, which decides which thread to execute next.
If you use as many threads as you have processor cores, then each thread can run on its own processor and might not be interrupted much often. In practice the operating system may require of course its own computations while your application is running; hence even in this case threads are interrupted and have to wait until the operating system lets them run again. The situation gets even worse, when you have to use more threads than you have CPU cores. In this case the scheduler can interrupt your thread in order to let another thread execute its code. In such a situation the current state of the running thread has to be saved, the state of the scheduled thread that is supposed to run next has to be restored. Beyond that the scheduler itself has to perform some updates on its internal data structures which again use CPU power. All together this means that each context switch from one thread to the other costs CPU power and therefore introduces performance degeneration in comparison to a single threaded solution.
Another cost of having multiple threads is the need to synchronize access to shared data structures. Next to the usage of the keyword synchronized we can also use volatile to share data between multiple threads. If more than one thread competes for the shared data structured we have contention. The JVM has then to decide which thread to execute next. If this is not the current thread, costs for a context switch are introduced. The current thread then has to wait until it can acquire the lock. The JVM can decide itself how to implement this waiting. When the expected time until the lock can be acquired is small, then spin-waiting, i.e. trying to acquire the lock again and again, might be more efficient compared to the necessary context switch when suspending the thread and letting another thread occupy the CPU. Bringing the waiting thread back to execution entails another context switch and adds additional costs to the lock contention.
Therefore it is reasonable to reduce the number of context switches that are necessary due to lock contention. The following section describes two approaches how to reduce this contention.
2.3. Lock contention
As we have seen in the previous section, two or more thread competing for one lock introduce additional clock cycles as the contention may force the scheduler to either let one thread spin-waiting for the lock or let another thread occupy the processor with the cost of two context switches. In some cases lock contention can be reduced by applying one of the following techniques:
- The scope of the lock is reduced.
- The number of times a certain lock is acquired is reduced.
- Using hardware supported optimistic locking operations instead of synchronization.
- Avoid synchronization where possible
- Avoid object pooling
2.3.1 Scope reduction
The first technique can be applied when the lock is hold longer than necessary. Often this can be achieved by moving one or more lines out of the synchronized block in order to reduce the time the current thread holds the lock. The less number of lines of code to execute the earlier the current thread can leave the synchronized block and therewith let other threads acquire the lock. This is also aligned with Amdahl’s Law, as we reduce the fraction of the runtime that is spend within synchronized blocks.
To better understand this technique, take a look at the following source code:
public class ReduceLockDuration implements Runnable {
private static final int NUMBER_OF_THREADS = 5;
private static final Map<String, Integer> map = new HashMap<String, Integer>();
public void run() {
for (int i = 0; i < 10000; i++) {
synchronized (map) {
UUID randomUUID = UUID.randomUUID();
Integer value = Integer.valueOf(42);
String key = randomUUID.toString();
map.put(key, value);
}
Thread.yield();
}
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[NUMBER_OF_THREADS];
for (int i = 0; i < NUMBER_OF_THREADS; i++) {
threads[i] = new Thread(new ReduceLockDuration());
}
long startMillis = System.currentTimeMillis();
for (int i = 0; i < NUMBER_OF_THREADS; i++) {
threads[i].start();
}
for (int i = 0; i < NUMBER_OF_THREADS; i++) {
threads[i].join();
}
System.out.println((System.currentTimeMillis()-startMillis)+"ms");
}
}
In this sample application, we let five threads compete for the access of the shared Map. To let only one thread at a time access the Map, the code that accesses the Map and adds a new key/value pair is put into a synchronized block. When we take a closer look at the block, we see that the computation of the key as well as the conversion of the primitive integer 42 into an Integer object must not be synchronized. They belong conceptually to the code that accesses the Map, but they are local to the current thread and the instances are not modified by other threads. Hence we can move them out of the synchronized block:
public void run() {
for (int i = 0; i < 10000; i++) {
UUID randomUUID = UUID.randomUUID();
Integer value = Integer.valueOf(42);
String key = randomUUID.toString();
synchronized (map) {
map.put(key, value);
}
Thread.yield();
}
}
The reduction of the synchronized block has an effect on the runtime that can be measured. On my machine the runtime of the whole application is reduced from 420ms to 370ms for the version with the minimized synchronized block. This makes a total of 11% less runtime just by moving three lines of code out of the synchronized block. The statement Thread.yield() is introduced to provoke more context switches, as this method call tells the JVM that the current thread is willing to give the processor to another waiting thread. This again provokes more lock contention as otherwise one thread may run too long on the processor without any competing thread.
2.3.2 Lock splitting
Another technique to reduce lock contention is to split one lock into a number of smaller scoped locks. This technique can be applied if you have one lock for guarding different aspects of your application. Assume we want to collect some statistical data about our application and implement a simple counter class that holds for each aspect a primitive counter variable. As our application is multi-threaded, we have to synchronize access to these variables, as they are accessed from different concurrent threads. The easiest way to accomplish this is to use the synchronized keyword within the method signature for each method of Counter:
public static class CounterOneLock implements Counter {
private long customerCount = 0;
private long shippingCount = 0;
public synchronized void incrementCustomer() {
customerCount++;
}
public synchronized void incrementShipping() {
shippingCount++;
}
public synchronized long getCustomerCount() {
return customerCount;
}
public synchronized long getShippingCount() {
return shippingCount;
}
}
This approach also means that each increment of a counter locks the whole instance of Counter. Other threads that want to increment a different variable have to wait until this single lock is released. More efficient in this case is to use separate locks for each counter like in the next example:
public static class CounterSeparateLock implements Counter {
private static final Object customerLock = new Object();
private static final Object shippingLock = new Object();
private long customerCount = 0;
private long shippingCount = 0;
public void incrementCustomer() {
synchronized (customerLock) {
customerCount++;
}
}
public void incrementShipping() {
synchronized (shippingLock) {
shippingCount++;
}
}
public long getCustomerCount() {
synchronized (customerLock) {
return customerCount;
}
}
public long getShippingCount() {
synchronized (shippingLock) {
return shippingCount;
}
}
}
This implementation introduces two separate synchronization objects, one for each counter. Hence a thread trying to increase the number of customers in our system only has to compete with other threads that also increment the number of customers but it has not to compete with threads trying to increment the number of shipping.
By using the following class we can easily measure the impact of this lock splitting:
public class LockSplitting implements Runnable {
private static final int NUMBER_OF_THREADS = 5;
private Counter counter;
public interface Counter {
void incrementCustomer();
void incrementShipping();
long getCustomerCount();
long getShippingCount();
}
public static class CounterOneLock implements Counter { ... }
public static class CounterSeparateLock implements Counter { ... }
public LockSplitting(Counter counter) {
this.counter = counter;
}
public void run() {
for (int i = 0; i < 100000; i++) {
if (ThreadLocalRandom.current().nextBoolean()) {
counter.incrementCustomer();
} else {
counter.incrementShipping();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[NUMBER_OF_THREADS];
Counter counter = new CounterOneLock();
for (int i = 0; i < NUMBER_OF_THREADS; i++) {
threads[i] = new Thread(new LockSplitting(counter));
}
long startMillis = System.currentTimeMillis();
for (int i = 0; i < NUMBER_OF_THREADS; i++) {
threads[i].start();
}
for (int i = 0; i < NUMBER_OF_THREADS; i++) {
threads[i].join();
}
System.out.println((System.currentTimeMillis() - startMillis) + "ms");
}
}
On my machine the implementation with one single lock takes about 56ms in average, whereas the variant with two separate locks takes about 38ms. This is a reduction of about 32 percent.
Another possible improvement is to separate locks even more by distinguishing between read and write locks. The Counter class for example provides methods for reading and writing the counter value. While reading the current value can be done by more than one thread in parallel, all write operations have to be serialized. The java.util.concurrent package provides a ready to use implementation of such a ReadWriteLock.
The ReentrantReadWriteLock implementation manages two separate locks. One for read accesses and one for write accesses. Both the read and the write lock offer methods for locking and unlocking. The write lock is only acquired, if there is no read lock. The read lock can be acquired by more than on reader thread, as long as the write lock is not acquired. For demonstration purposes the following shows an implementation of the counter class using a ReadWriteLock:
public static class CounterReadWriteLock implements Counter {
private final ReentrantReadWriteLock customerLock = new ReentrantReadWriteLock();
private final Lock customerWriteLock = customerLock.writeLock();
private final Lock customerReadLock = customerLock.readLock();
private final ReentrantReadWriteLock shippingLock = new ReentrantReadWriteLock();
private final Lock shippingWriteLock = shippingLock.writeLock();
private final Lock shippingReadLock = shippingLock.readLock();
private long customerCount = 0;
private long shippingCount = 0;
public void incrementCustomer() {
customerWriteLock.lock();
customerCount++;
customerWriteLock.unlock();
}
public void incrementShipping() {
shippingWriteLock.lock();
shippingCount++;
shippingWriteLock.unlock();
}
public long getCustomerCount() {
customerReadLock.lock();
long count = customerCount;
customerReadLock.unlock();
return count;
}
public long getShippingCount() {
shippingReadLock.lock();
long count = shippingCount;
shippingReadLock.unlock();
return count;
}
}
All read accesses are guarded by an acquisition of the read lock, while all write accesses are guarded by the corresponding write lock. In case the application uses much more read than write accesses, this kind of implementation can even gain more performance improvement than the previous one as all the reading threads can access the getter method in parallel.
2.3.3 Lock striping
The previous example has shown how to split one single lock into two separate locks. This allows the competing threads to acquire only the lock that protects the data structures they want to manipulate. On the other hand this technique also increases complexity and the risk of dead locks, if not implemented properly.
Lock striping on the other hand is a technique similar to lock splitting. Instead of splitting one lock that guards different code parts or aspects, we use different locks for different values. The class ConcurrentHashMap from JDK’s java.util.concurrent package uses this technique to improve the performance of applications that heavily rely on HashMaps. In contrast to a synchronized version of java.util.HashMap, ConcurrentHashMap uses 16 different locks. Each lock guards only 1/16 of the available hash buckets. This allows different threads that want to insert data into different sections of the available hash buckets to do this concurrently, as their operation is guarded by different locks. On the other hand it also introduces the problem to acquire more than one lock for specific operations. If you want to copy for example the whole Map, all 16 locks have to be acquired.

2.3.4 Atomic operations
Another way to reduce lock contention is to use so called atomic operations. This principle is explained and evaluated in more detail in one of the following articles. The java.util.concurrent package offers support for atomic operations for some primitive data types. Atomic operations are implemented using the so called compare-and-swap (CAS) operation provided by the processor. The CAS instruction only updates the value of a certain register, if the current value equals the provided value. Only in this case the old value is replaced by the new value.
This principle can be used to increment a variable in an optimistic way. If we assume our thread knows the current value, then it can try to increment it by using the CAS operation. If it turns out, that another thread has meanwhile incremented the value and our value is no longer the current one, we request the current value and try with it again. This can be done until we successfully increment the counter. The advantage of this implementation, although we may need some spinning, is that we don’t need any kind of synchronization.
The following implementation of the Counter class uses the atomic variable approach and does not use any synchronized block:
public static class CounterAtomic implements Counter {
private AtomicLong customerCount = new AtomicLong();
private AtomicLong shippingCount = new AtomicLong();
public void incrementCustomer() {
customerCount.incrementAndGet();
}
public void incrementShipping() {
shippingCount.incrementAndGet();
}
public long getCustomerCount() {
return customerCount.get();
}
public long getShippingCount() {
return shippingCount.get();
}
}
Compared to the CounterSeparateLock class the total average runtime decreases from 39ms to 16ms. This is a reduction in runtime of about 58 percent.
2.3.5 Avoid hotspots
A typical implementation of a list will manage internally a counter that holds the number of items within the list. This counter is updated every time a new item is added to the list or removed from the list. If used within a single-threaded application, this optimization is reasonable, as the size() operation on the list will return the previously computed value directly. If the list does not hold the number of items in the list, the size() operation would have to iterate over all items in order to calculate it.
What is a common optimization in many data structures can become a problem in multi-threaded applications. Assume we want to share an instance of this list with a bunch of threads that insert and remove items from the list and query its size. The counter variable is now also a shared resource and all access to its value has to be synchronized. The counter has become a hotspot within the implementation.
The following code snippet demonstrates this problem:
public static class CarRepositoryWithCounter implements CarRepository {
private Map<String, Car> cars = new HashMap<String, Car>();
private Map<String, Car> trucks = new HashMap<String, Car>();
private Object carCountSync = new Object();
private int carCount = 0;
public void addCar(Car car) {
if (car.getLicencePlate().startsWith("C")) {
synchronized (cars) {
Car foundCar = cars.get(car.getLicencePlate());
if (foundCar == null) {
cars.put(car.getLicencePlate(), car);
synchronized (carCountSync) {
carCount++;
}
}
}
} else {
synchronized (trucks) {
Car foundCar = trucks.get(car.getLicencePlate());
if (foundCar == null) {
trucks.put(car.getLicencePlate(), car);
synchronized (carCountSync) {
carCount++;
}
}
}
}
}
public int getCarCount() {
synchronized (carCountSync) {
return carCount;
}
}
}
The CarRepository implementation holds two lists: One for cars and one for trucks. It also provides a method that returns the number of cars and trucks that are currently in both lists. As an optimization it increments the internal counter each time a new car is added to one of the two lists. This operation has to be synchronized with the dedicated carCountSync instance. The same synchronization is used when the count value is returned.
In order to get rid of this additional synchronization, the CarRepository could have also been implemented by omitting the additional counter and computing the number of total cars each time the value is queried by calling getCarCount():
public static class CarRepositoryWithoutCounter implements CarRepository {
private Map<String, Car> cars = new HashMap<String, Car>();
private Map<String, Car> trucks = new HashMap<String, Car>();
public void addCar(Car car) {
if (car.getLicencePlate().startsWith("C")) {
synchronized (cars) {
Car foundCar = cars.get(car.getLicencePlate());
if (foundCar == null) {
cars.put(car.getLicencePlate(), car);
}
}
} else {
synchronized (trucks) {
Car foundCar = trucks.get(car.getLicencePlate());
if (foundCar == null) {
trucks.put(car.getLicencePlate(), car);
}
}
}
}
public int getCarCount() {
synchronized (cars) {
synchronized (trucks) {
return cars.size() + trucks.size();
}
}
}
}
Now we need to synchronized with the cars and trucks list in the getCarCount() method and compute the size, but the additional synchronization during the addition of new cars can be left out.
2.3.6 Avoid object pooling
In the first versions of the Java VM object creation using the new operator was still an expensive operation. This led many programmers to the common pattern of object pooling. Instead of creating certain objects again and again, they constructed a pool of these objects and each time an instance was needed, one was taken from the pool. After having used the object, it was put back into the pool and could be used by another thread.
What makes sense at first glance can be a problem when used in multi-threaded applications. Now the object pool is shared between all threads and access to the objects within the pool has to be synchronized. This additional synchronization overhead can now be bigger than the costs of the object creation itself. This is even true when you consider the additional costs of the garbage collector for collecting the newly created object instances.
As with all performance optimization this example shows once again, that each possible improvement should be measured carefully before being applied. Optimizations that seem to make sense at first glance can turn out to be even performance bottlenecks when not implemented correctly.
