Even today (and it’s 2015) we have two versions or Oracle HotSpot JDK – adjusted to 32 or 64 bits architecture. The question is do we really would like to use 32bit JVM on our servers or even laptops? There is pretty popular opinion that we should! If you need only small heap then use 32bits – it has smaller memory footprint, so your application will use less memory and will trigger shorter GC pauses. But is it true? I’ll explore three different areas:
- Memory footprint
- GC performance
- Overall performance
Let’s begin with memory consumption.
Memory footprint
It’s known that major difference between 32 and 64 bits JVM relates to memory addressing. That means all references on 64bit version takes 8 bytes instead of 4. Fortunately JVM comes with compressed object pointers which is enabled by default for all heaps less than 26GB. This limit is more than OK for us, as long as 32 bit JVM can address around 2GB (depending on target OS it’s still about 13 times less). So no worries about object references. The only thing that differs object layout are mark headers which are 4 bytes bigger on 64 bits. We also know that all objects in Java are 8 bytes aligned, so there are two possible cases:
- worst – on 64 bits object is 8 bytes bigger than on 32 bits. It’s because adding 4 bytes to header causes object is dropped into another memory slot, so we have to add 4 more bytes to fill alignment gap.
- best – objects on both architectures have the same size. It happens when on 32 bits we have 4 bytes alignment gap, which can be simply filled by additional mark header bytes.
Let’s calculate now both cases assuming two different application sizes. IntelliJ IDEA with pretty big project loaded contains about 7 million objects – that will be our smaller project. For the second option lets assume that we have big project (I’ll call it Huge) containing 50 million objects in the live set. Let’s now calculate the worst case:
IDEA -> 7 millions * 8 bytes = 53 MBHuge -> 50 millions * 8 bytes = 381 MB
Above calculations shows us that real application footprint is in the worst case raised for around 50MB heap for IntelliJ and around 400MB for some huge, highly granulated project with really small objects. In the second case it can be around 25% of the total heap, but for vast majority of projects it’s around 2%, which is almost nothing.
GC Performance
The idea is to put 8 million String objects into Cache with Long key. One test consists of 4 invocations, which means 24 million puts into cache map. I used Parallel GC with total heap size set to 2GB. Results were pretty surprising, because whole test finished sooner on 32bit JDK. 3 minutes 40 seconds compared to 4 minutes 30 seconds on 64bit Virtual Machine. After comparing GC logs we can see, that the difference mostly comes from GC pauses: 114 seconds to 157 seconds. That means 32 bit JVM in practice brings much lower GC overhead – 554 pauses to 618 for 64bits. Below you can see screenshots from GC Viewer (both with the same scale on both axis)
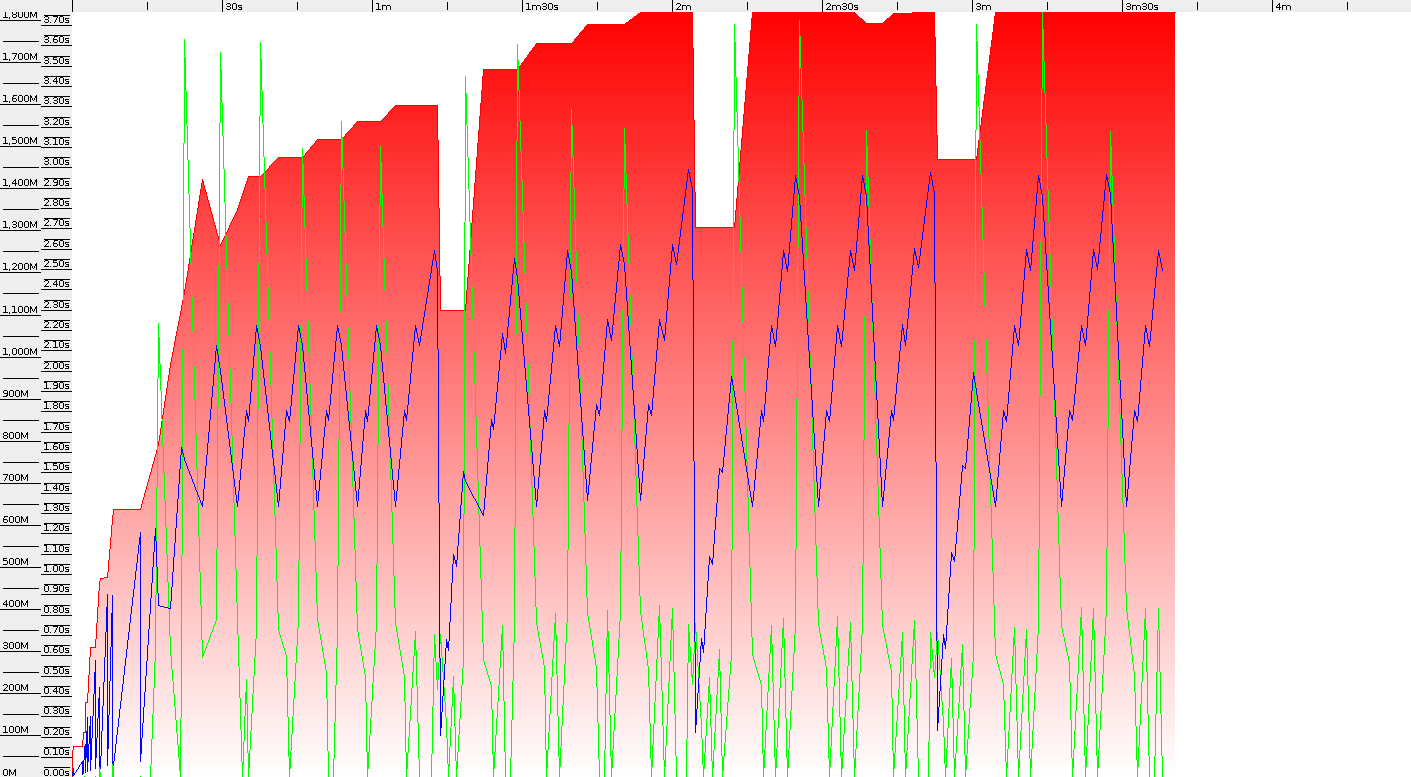
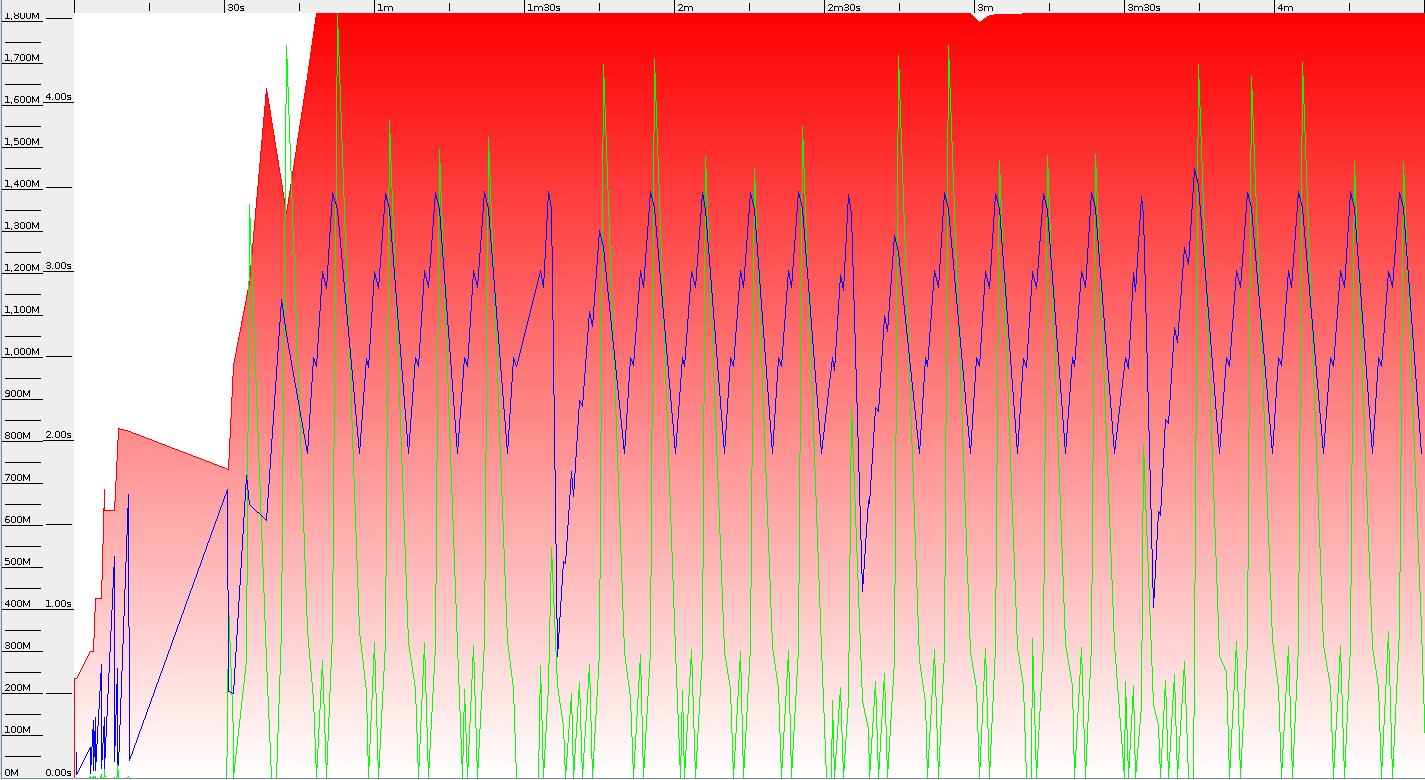
I was expecting smaller overhead of 64bits JVM but benchmarks shows that even total heap usage is similar on 32bits we are freeing more memory on Full GC. Young generation pauses are also similar – around 0.55 seconds for both architectures. But average major pause is higher on 64bits – 3.2 compared to 2.7 on 32bits. That proves GC performance for small heap is much better on 32bits JDK. The question is if your applications are so demanding to GC – in the test average throughput was around 42-48%.
Second test was performed on more “enterprise” scenario. We’re loading entities from database and invoking size() method on loaded list. For total test time around 6 minutes we have 133.7s total pause time for 64bit and 130.0s for 32bit. Heap usage is also pretty similar – 730MB for 64bit and 688MB for 32bit JVM. This shows us that for normal “enterprise” usage there are no big differences between GC performance on various JVM architectures.

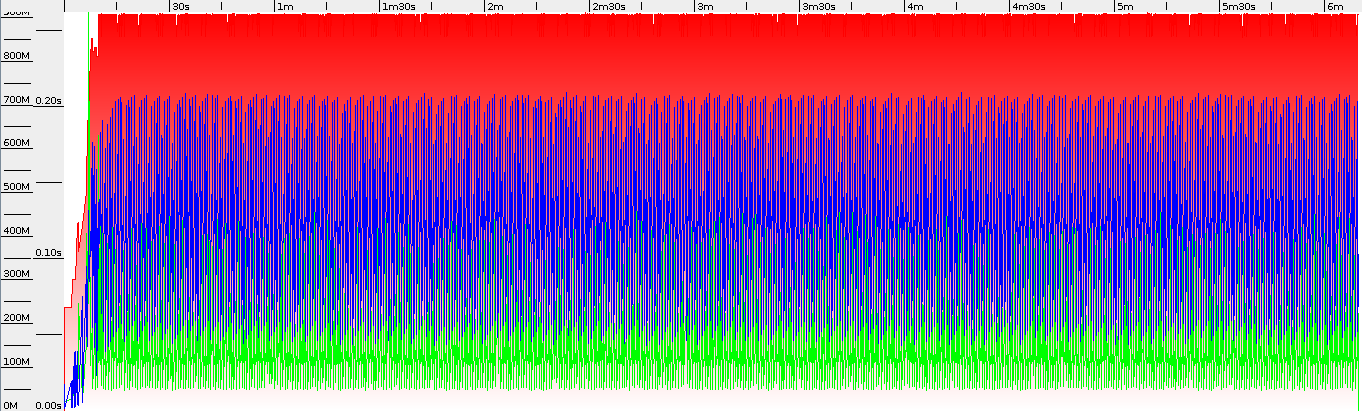
Even with similar GC performance 32bit JVM finished the work 20 seconds earlier (which is around 5%).
Overall performance
It’s of course almost impossible to verify JVM performance that will be true for all applications, but I’ll try to provide some meaningful results. At first let’s check time performance.
Benchmark 32bits [ns] 64bits [ns] ratio System.currentTimeMillis() 113.662 22.449 5.08 System.nanoTime() 128.986 20.161 6.40 findMaxIntegerInArray 2780.503 2790.969 1.00 findMaxLongInArray 8289.475 3227.029 2.57 countSinForArray 4966.194 3465.188 1.43 UUID.randomUUID() 3084.681 2867.699 1.08
As we can see the biggest and definitely significant difference is for all operations related to long variables. Those operations are between 2.6 up to 6.3 times faster on 64bits JVM. Working with integers is pretty similar, and generating random UUID is faster just around 7%. What is worth to mention is that interpreted code (-Xint) has similar speed – just JIT for the 64bits version is much more efficient. So are there any particular differences? Yes! 64bit architecture comes with additional processor registers which are used by JVM. After checking generated assembly it looks that performance boost mostly comes from possibility to use 64bit registers, which can simplify long operations. Any other changes can be found for example under wiki page. If you want to run this on your machine you can find all benchmarks on my GitHub – https://github.com/jkubrynski/benchmarks_arch
Conclusions
As in the whole IT world we cannot answer simply – “yes, you should always use **bits JVM”. It strongly depends on your application characteristics. As we saw there are many differences between 32 and 64 bits architecture. Even if JIT performance for long related operations is few hundred percents better we can see that tested batch processes finished earlier on 32bits JVM. To conclude – there is no simple answer. You should always check which architecture fits to your requirements better.
Big thanks to Wojtek Kudla for reviewing this article and enforcing additional tests :)
| Reference: | Do we really still need a 32-bit JVM? from our JCG partner Jakub Kubrynski at the Java(B)Log blog. |
