“Arien got in touch with us on twitter after seeing the results of a parallelStreams and ForkJoin benchmark we ran. It piqued his interest so he ran some tests of his own, adding Quasar fibers to the mix. Here are his results and conclusions.” – Alex Zhitnitsky, Takipi
Arien Kock is a Sr. Java Software Engineer. He enjoys stand-up comedy and used to be a competitive Street Fighter player.

How do Async ForkJoinPool, managedBlock and Quasar perform in an IO scenario?
I think Quasar has a lot of potential. In addition to allowing a much higher number of parallel operations, by not being 1 to 1 mappings of OS threads, Quasar’s fibers also let the programmer write code in synchronous fashion (using continuations). This makes it much simpler to interpret and reason about code than the trail of callbacks that vanilla async-style code tends to bring. As for the performance benefits of the lightweight threads, I consider the increased performance of suspending green-threads/fibers vs. the parking OS threads pretty much proven. Triggered by this Takipi blog post, I became curious about how Quasar would perform vs. alternatives in an IO scenario. So I made a benchmark.
New Post: Java IO Benchmark: Quasar vs. Async ForkJoinPool vs. managedBlock http://t.co/2eoi4th2ZO pic.twitter.com/IDDGYPYvfI
— Takipi (@takipid) March 9, 2015
The Setup
I used JMH to avoid reinventing a bad version of the testing wheel. I found Caliper first, but then I read somewhere on Stackoverflow that JMH was “better”. It was my first time using it, but it was a very positive experience. It comes with profilers and automatic parameter permutations and a lot of other great features for writing microbenchmarks. My benchmark compares three styles of IO. Using AsynchronousFileChannel directly (with callbacks), using a regular blocking FileChannel but with the ForkJoinPool’s managedBlock facility, and finally: Quasar (which uses a wrapper object around the AsynchronousFileChannel that allows you to write synchronous style code). I ran the tests with some computational jobs sprinkled in between the IO operations to get a good amount of context switching out of Quasar. You can find the benchmark code on my Github repo. The benchmark ran on my Windows 8 laptop in Safe mode (the best way I know to avoid interference) with an SSD drive.
The Results
With 5 warmup iterations and 15 real samples I believe this is quite accurate.
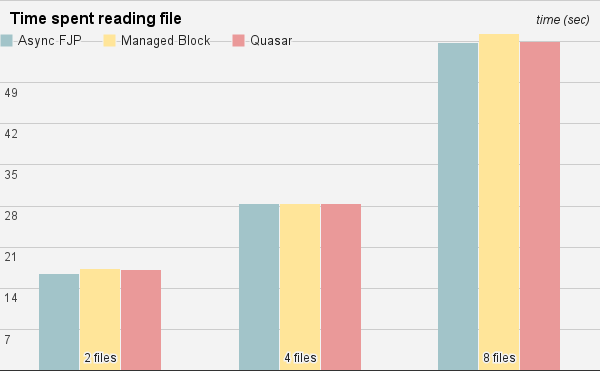
The differences are far inside the error margin and I believe it’s safe to say they are equal. Running the stack profiler only showed the difference between managed blocking and the non-blocking (Quasar and Async FJP) types, which produce very different call-stacks. I created a benchmark doing the same thing using Sockets, but I’m pretty sure there’s a bug in the implementation. If anyone wants to have a look at the code, feel free.
I expected the managed block to be slower because it will allocate additional threads when it can’t guarantee enough paralellism on the FJP, which using the computational tasks, was definitely the case. I couldn’t even start VisualVM normally while that benchmark ran. The large number of threads made loading it extremely slow. Despite frequent thread allocation there is no distinction. The same goes for Quasar. The overhead of suspending fibers, which is the action of setting aside the current state of executing process to free up the CPU core, doesn’t incur any noticeable delay. Where “noticeable” is key…
The Conclusion
In the face of IO, the differences in speed of the three implementations are insignificant. It wouldn’t matter if I had implemented a fire-hose, where the CPU is the bottleneck, because in all three implementations the regular (non-IO) code would execute at the same speed and the same parallelism. That is because Quasar doesn’t do any context switching unless a fiber actually blocks. Quasar even issues warnings if a fiber takes too long to execute without fiber-blocking. It may seem that the three styles of handling IO being equally performant, means the choice between the three for this type of application would be a matter of taste. However, I think this is only partially true. Between the callback and blocking styles, I would clearly pick the blocking style if all I had to do was process 8 files simultaneously. It’s much easier to grasp. Next, choosing between managed blocks (creating more threads) and fiber blocks, managed blocks is the least amount of work. Case not entirely closed, however…
Latency
In a web server where a client connection can be kept open for a long time (e.g. while we wait for a slow client and/or we’re fetching data from a DB), blocking a thread for the duration of the transaction can lead to thread starvation. This is where Quasar can really shine, thanks to the multiplexing of many user-space threads onto a small number of OS threads. Then there is…
The (current) “difficulty” of using Quasar
As of right now using quasar means using a java agent, which only takes a tiny bit of effort. There is also the marking of existing code as @Suspendable so that Quasar can instrument and subsequently block the fiber the code is running on. Look at the pom.xml for the maven-antrun-plugin that does the discovery/marking. If you’re using a framework that has callback-style asynchronicity, then the custom code you need to write is not that complex, but you still have to write it. Have a look at Pulsar for ready-made integrations.
Fibers for IO: Yay or Nay
The benchmark shows no penalty for using fibers when all you’re doing is continuous IO with high throughput and low parallelism. The extra effort to use Quasar (in terms of extra coding and configuration) is a series of one-off tasks, which (in my opinion) makes it negligible. Pulsar provides a good set of integrations (though the JDBC one falls a bit short). With these and your own, you can create a IO-heavy application, like a web-application, that has a pool for accepting connections and one or more pools for handling backend calls. What you end up with is pools of threads handing off tasks to each other in the background, while your logic still reads from top to bottom in synchronous fashion with a return statement at the end.
If like most small applications, you’re making something for a few hundred simultaneous users, at the most: the technique is worth checking out, but there’s no benefit. However, if your application needs to process a large number of parallel requests: I say, go for it.
| Reference: | Java IO Benchmark: Quasar vs. Async ForkJoinPool vs. managedBlock from our JCG partner Arien Kock at the Takipi blog. |
