A large part of the art of software development is keeping the complexity of a system as low as possible. But what is complexity anyway? While the exact semantics vary quite a bit, depending on who you ask, probably most agree that it has a lot to do with the number of parts in a system and their interactions.
Consider a marble in space, i.e a planet, moon or star. Without any interaction this is as boring as a system can get. Nothing happens. If the marble moves, it keeps moving in exactly the same way. To be honest there isn’t even a way to determine if it is moving. Boooring.
Add a second marble to the system and let them attract each other, like earth and moon. Now the system is a more interesting. The two objects circle each other if they aren’t too fast. Somewhat interesting.
Now add a third object. In the general case things go so interesting that we can’t even predict what is going to happen. The whole system didn’t just became complex it became chaotic. You now have a three body problem In the general case this problem cannot be solved, i.e. we cannot predict what will happen with the system. But there are some special cases. Especially the case where two of the objects a very close to each other like earth and moon and the third one is so far away that the two first object behave just like one. In this case you approximate the system with two particle systems.
But what has this to do with Java? This sounds more like physics.
I think software development is similar in some aspects. A complete application is way to complicated to be understood as a whole. To fight this complexity we divide the system into parts (classes) that can be understood on their own, and that hide their inner complexity so that when we look at the larger picture we don’t have to worry about every single code line in a class, but only about the class as one entity. This is actually very similar to what physicists do with systems.
But let’s look at the scale of things. The basic building block of software is the code line. And to keep the complexity in check we bundle code lines that work together in methods. How many code lines go into a single method varies, but it is in the order of 10 lines of code.
Next you gather methods into classes. How many methods go into a single class? Typically in the order of 10 methods!
And then? We bundle 100-10000 classes in a single jar! I hope I’m not the only one who thinks something is amiss.
I’m not sure what comes out of project jigsaw, but currently Java only offers packages as a way to bundle classes. Package aren’t a powerful abstraction, yet it is the only one we have, so we better use it.
Most teams do use packages, but not in a very well structured, but ad hoc way. The result is similar to trying to consider moon and sun as on part of the system, and the earth as the other part. The result might work, but it is probably as intuitive as Ptolemy’s planetary model. Instead decide on criteria how you want to differentiate your packages. I personally call them slicings, inspired by an article by Oliver Gierke. Possible slicings in order of importance are:
- the deployable jar file the class should end up in
- the use case / feature / part of the business model the class belongs to
- the technical layer the class belongs to
The packages this results in will look like this: <domain>.<deployable>.<domain part>.<layer>
It should be easy to decide where a class goes. And it should also keep the packages at a reasonable size, even when you don’t use the separation by technical layer.
But what do you gain from this? It is easier to find classes, but that’s about it. You need one more rule to make this really worth while: There must be no cyclic dependencies!
This means, if a class in a package A references a class in package B no class in B may reference A. This also applies if the reference is indirect via multiple other packages. But that is still not enough. Slices should be cycle free as well, so if a domain part X references a different domain part Y, the reverse dependency must not exist!
This will in deed put some rather strict rules on your package and dependency structure. The benefit of this is, that it becomes very flexible.
Without such a structure splitting your project in multiple parts will probably be rather difficult. Ever tried to reuse part of an application in a different one, just to realize that you basically have to include most of the the application in order to get it to compile? Ever tried to deploy different parts of an application to different servers, just to realize you can’t? It certainly happend to me before I used the approach mentioned above. But with this more strict structure, the parts you may want to reuse, will almost on their own end up on the end of the dependency chain so you can take them and bundle them in their own jar, or just copy the code in a different project and have it compile in very short time.
Also while trying to keep your packages and slices cycle free you’ll be forced to think hard, what each package involved is really about. Something that improved my code base considerably in many cases.
So there is one problem left: Dependencies are hard to see. Without a tool, it is very difficult to keep a code base cycle free. Of course there are plenty of tools that check for cycles, but cleaning up these cycles is tough and the way most tools present these cycles doesn’t help very much. I think what one needs are two things:
- a simple test, that can run with all your other tests and fails when you create a dependency circle.
- a tool that visualizes all the dependencies between classes, while at the same time showing in which slice each class belongs.
Surprise! I can recommend such a great tool: Degraph! (I’m the author, so I might be biased)
You can write tests in JUnit like this:
assertThat(
classpath().including("de.schauderhaft.**")
.printTo("degraphTestResult.graphml")
.withSlicing("module", "de.schauderhaft.(*).*.**")
.withSlicing("layer", "de.schauderhaft.*.(*).**"),
is(violationFree())
);The test will analyze everything in the classpath that starts with de.schauderhaft. It will slice the classes in two ways: By taking the third part of the package name and by taking the forth part of the package name. So a class name de.schauderhaft.customer.persistence.HibernateCustomerRepository ends up in the module customer and in the layer persistence. And it will make sure that modules, layers and packages are cycle free.
And if it finds a dependency circle, it will create a graphml file, which you can open using the free graph editor yed. With a little layouting you get results like the following where the dependencies that result in circular dependencies are marked in red.
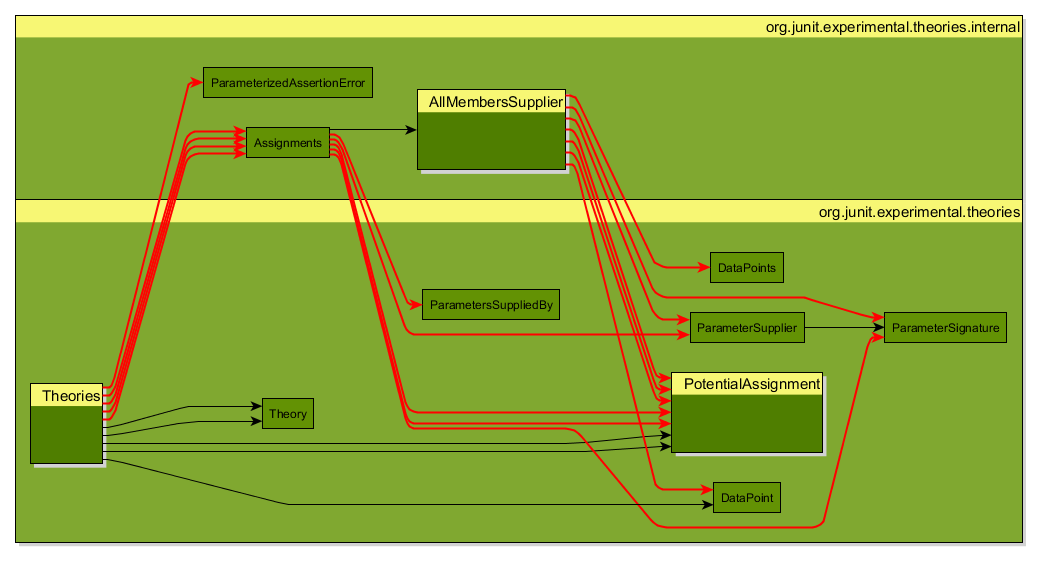
Again for more details on how to achieve good usable layouts I have to refer to the documentation of Degraph.
Also note that the graphs are colored mainly green with a little red, which nicely fits the season!
| Reference: | Managing Package Dependencies with Degraph from our JCG partner Jens Schauder at the Java Advent Calendar blog. |
