Have you ever wondered how a commit and its content is stored in Git? Well, I have, and I had some spare time over the last rainy weekend, so I did a little research.
Because I feel more at home with Java than with Bash, I used JGit and a couple of learning tests to explore the Git internals of commits. Here are my findings:
Git – an Object Database
Git at the core is a simple content-addressable data store. This means that you can insert any kind of content into it and it will return a key that you can use to retrieve the data again at a later point in time.
In the case of Git, the key is the 20 byte SHA-1 hash that is computed from the content. The content is also referred to as an object in Git terminology and consequently the data store is also called an object database.
Let’s see how JGit can be used to store and retrieve content.
Blobs
In JGit, the ObjectInserter is used to store content into the object database. It can be seen as the rough equivalent to git hash-object in Git.
With its insert() method you can write an object to the data store whereas its idFor() methods only compute the SHA-1 hash of the given bytes. Hence the code to store a string looks like this:
ObjectInserter objectInserter = repository.newObjectInserter(); byte[] bytes = "Hello World!".getBytes( "utf-8" ); ObjectId blobId = objectInserter.insert( Constants.OBJ_BLOB, bytes ); objectInserter.flush();
All code examples assume that the repository varaible points to an empty repository that was created outside of the snippet.
The first parameter denotes the object type of the object to be inserted, a blob type in this case. There are further object types as we will learn later. The blob type is used to store arbitrary content.
The payload must be given in the second parameter, as a byte array in this case. An overloaded method that accepts an InputStream is also available.
And finally, the ObjectInserter needs to be flushed to make the changes visible to others accessing the repository.
The insert() method returns the SHA-1 hash that is computed from the type, the content length and the content bytes. In JGit, though, a SHA-1 hash is represented through the ObjectId class, an immutable data structure that can be converted to and from bytes, ints, and strings.
Now you can use the returned blobId to retrieve the content back and thus ensure that the above code actually wrote the content.
ObjectReader objectReader = repository.newObjectReader(); ObjectLoader objectLoader = objectReader.open( blobId ); int type = objectLoader.getType(); // Constants.OBJ_BLOB byte[] bytes = objectLoader.getBytes(); String helloWorld = new String( bytes, "utf-8" ) // Hello World!
The ObjectReader’s open() method returns an ObjectLoader that can be used to access the object identified by the given object ID. With the help of an ObjectLoader you can get an object’s type, its size and of course its content as a byte array or stream.
To verify that the object written by JGit is compatible with native Git you can retrieve its content with git cat-file.
$ git cat-file -p c57eff55ebc0c54973903af5f72bac72762cf4f4 Hello World! git cat-file -t c57eff55ebc0c54973903af5f72bac72762cf4f4 blob
If you look inside the .git/objects directory of the repository, you’ll find a directory named ‘c5′ with a file named ‘7eff55ebc0c54973903af5f72bac72762cf4f4′ in it. This is how the content is stored initially: as a single file per object, named with the SHA-1 hash of the content. The subdirectory is named with the first two characters of the SHA-1 and the filename consists of the remaining characters.
Now that you can store the content of a file, the next step is to store its name. And probably also more than just one file, since a commit usually consists of a group of files. To hold this kind of information, Git uses so called tree objects.
Tree Objects
A tree object can be seen as a simplified file system structure that contains information about files and directories.
It contains any number of tree entries. Each entry has a path name, a file mode and points to either the content of a file (a blob object) or another (sub) tree object if it represents a directory. The pointer of course is a SHA-1 hash of either the blob object or the tree object.
To start with, you can create a tree that holds a single entry for a file named ‘hello-world.txt’ that points to the above stored ‘Hello World!’ content.
TreeFormatter treeFormatter = new TreeFormatter(); treeFormatter.append( "hello-world.txt", FileMode.REGULAR_FILE, blobId ); ObjectId treeId = objectInserter.insert( treeFormatter ); objectInserter.flush();
The TreeFormatter is used here to construct an in-memory tree object. By calling append() an entry is added with the given path name, mode and the ID under which its content is stored.
Fundamentally, you are free to chose any path name. However, Git expects the path name to be relative to the working directory without a leading ‘/’.
The file mode used here indicates a normal file. Other modes are EXECUTABLE_FILE, which means it’s an executable file, and SYMLINK, which specifies a symbolic link. For directory entries, the file mode is always TREE.
Again, you will need an ObjectInserter. One of its overloaded insert() methods accepts a TreeFormatter and writes it to the object database.
You can now use a TreeWalk to retrieve and examine the tree object:
TreeWalk treeWalk = new TreeWalk( repository ); treeWalk.addTree( treeId ); treeWalk.next(); String filename = treeWalk.getPathString(); // hello-world.txt
Actually, a TreeWalk is meant to iterate over the added trees and their subtrees. But since we know that there is exactly one entry, a single call to next() is sufficient.
If you look at the just written tree object with native Git you will see the following:
$ git cat-file -p 44d52a975c793e5a4115e315b8d89369e2919e51 100644 blob c57eff55ebc0c54973903af5f72bac72762cf4f4 hello-world.txt
Now that you have the necessary ingredients for a commit, let’s create the commit object itself.
Commit Objects
A commit object references the files (through the tree object) that constitute the commit along with some meta data. In detail a commit consists of:
- a pointer to the tree object
- pointers to zero or more parent commits (more on that later)
- a commit message
- and an author and committer
Since a commit object is just another object in the object database, it is also sealed with the SHA-1 hash that was computed over its content.
To form a commit object, JGit offers the CommitBuilder utility class.
CommitBuilder commitBuilder = new CommitBuilder(); commitBuilder.setTreeId( treeId ); commitBuilder.setMessage( "My first commit!" ); PersonIdent person = new PersonIdent( "me", "me@example.com" ); commitBuilder.setAuthor( person ); commitBuilder.setCommitter( person ); ObjectInserter objectInserter = repository.newObjectInserter(); ObjectId commitId = objectInserter.insert( commitBuilder ); objectInserter.flush();
Using it is straightforward, it has setter methods for all the attributes of a commit.
The author and committer are represented through the PersonIdent class which holds the name, email, timestamp and time zone. The constructor used here applies the given name and email and takes the current time and time zone.
And the rest should be familiar already: an ObjectInserter is used to actually write the commit object and returns the commit ID.
To retrieve the commit object from the repository, you can again use the ObjectReader:
ObjectReader objectReader = repository.newObjectReader(); ObjectLoader objectLoader = objectReader.open( commitId ); RevCommit commit = RevCommit.parse( objectLoader.getBytes() );
The resulting RevCommit represents a commit with the same attributes that were specified in the CommitBuilder.
And once again – to double-check – the output of git cat-file:
$ git cat-file -p 783341299c95ddda51e6b2393c16deaf0c92d5a0 tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904 author me <me@example.com> 1412872859 +0200 committer me <me@example.com> 1412872859 +0200 My first commit!
Parents
The chain of parents form the history of a Git repository and model a directed acyclic graph. This means that the commits ‘follow’ one direction
A commit can have zero or more parents. The first commit in a repository does not have a parent (aka root commit). The second commit in turn has the first as its parent, and so on.
It is perfectly legal to create more than one root commit. If you use git checkout --orphan new_branch a new orphan branch will be created and switched to. The first commit made on this branch will have no parents and will form the root of a new history that is disconnected from all other commits.
If you start branching and eventually merge the divergent lines of changes, this usually results in a merge commit. And such a commit has the head commits of the divergent branches as its parents.
In order to construct a parented commit, the ID of the parent commit needs to be specified in the CommitBuilder.
commitBuilder.setParents( parentId );
A RevCommit class, which represents a commit within the repository, can also be queried about its parents. Its getParents() and getParent(int) methods return all or the nth parent RevCommit.
Be warned however, that though the methods return RevCommits these are not fully resolved. While their ID attribute is set, all other attributes (fullMessage, author, committer, etc.) are not. Thus, an attempt to call parent.getFullMessage() for example will throw a NullPointerException. In order to actually use the parent commit you need to either retrieve a full RevCommit by means of the ObjectReader like outlined above or use a RevWalk to load and parse the commit header:
RevWalk revWalk = new RevWalk( repository ); revWalk.parseHeaders( parentCommit );
All in all, keep in mind to treat the returned parent commits as if they were ObjectIds instead of RevCommits.
More on Tree Objects
If you are to store files in sub-directories you need to construct the sub-trees yourself. Say you want to store the content of a file ‘file.txt’ in folder ‘folder’.
First, create and store a TreeFormatter for the subtree, the one that has an entry for the file:
TreeFormatter subtreeFormatter = new TreeFormatter(); subtreeFormatter.append( "file.txt", FileMode.REGULAR_FILE, blobId ); ObjectId subtreeId = objectInserter.insert( subtreeFormatter );
And then, create and store a TreeFormatter with an entry that denotes the folder and points to the just created subtree.
TreeFormatter treeFormatter = new TreeFormatter(); treeFormatter.append( "folder", FileMode.TREE, subtreeId ); ObjectId treeId = objectInserter.insert( treeFormatter );
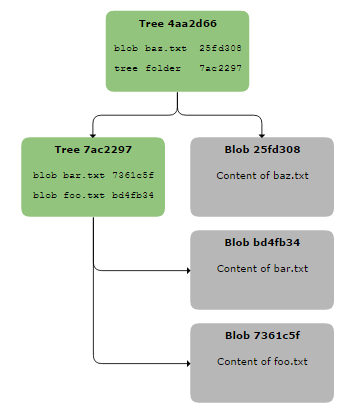
The file mode of the entry is TREE to indicate a directory and its ID points to the subtree that holds the file-entry. The returned treeId is the one that would be passed to the CommitBuilder.
Git requires a certain sort order for entries in tree objects. The ‘Git Data Formats’ document that I found here states that:
Tree entries are sorted by the byte sequence that comprises the entry name. However, for the purposes of the sort comparison, entries for tree objects are compared as if the entry name byte sequence has a trailing ASCII ‘/’ (0x2f).
To read the contents of the tree object you can again use a TreeWalk. But this time, you need to tell it to recurse into subtrees if you which to visit all entries. And also, don’t forget to set the postOrderTraversal to true if you whish to see entries that point to a tree. They would be skipped otherwise.
The whole TreeWalk loop will look like this in the end:
TreeWalk treeWalk = new TreeWalk( repository );
treeWalk.addTree( treeId );
treeWalk.setRecursive( true );
treeWalk.setPostOrderTraversal( true );
while( treeWalk.next() ) {
int fileMode = Integer.parseInt( treeWalk.getFileMode( 0 ).toString() );
String objectId = treeWalk.getObjectId( 0 ).name();
String path = treeWalk.getPathString();
System.out.println( String.format( "%06d %s %s", fileMode, objectId, path ) );
}…and will lead to this output:
100644 6b584e8ece562ebffc15d38808cd6b98fc3d97ea folder/file.txt 040000 541550ddcf8a29bcd80b0800a142a7d47890cfd6 folder
Although I find the API not very intuitive it gets the job done and reveals all the details of the tree object.
Concluding Git Internals
No doubt, that for common use cases the high-level Add- and CommitCommands are the recommended way to commit files to the repository. Still, I found it worthwhile digging in to the deeper levels of JGit and Git and hope you did so, too. And in the – admittedly less common – case that you need to commit files to a repository without a working directory and/or index, the information provided here might help.
If you like to try out the examples listed here for yourself, I recommend to setup JGit with access to its sources and JavaDoc so that you have meaningful context information, content assist, debug-sources, etc.
- The complete source code is hosted here: https://gist.github.com/rherrmann/02d8d4fe81bb60d9049e
For brevity, the samples shown here omit the code to release allocated resources. Please refer to the complete source code to get all the details.
| Reference: | Explore Git Internals with the JGit API from our JCG partner Rudiger Herrmann at the Code Affine blog. |
