 One of the fascinating things about our data structures is that even though we’re so familiar with them, it’s still hard for us to tell exactly how many items something as basic as a HashMap can hold in a 1GB of memory. We may learn this at school, from senior developers, or the hard way when our servers collapse due to poor choice of data structures. So I decided to do just that. I took ~20 of the most popular Java, Scala, Guava and Trove collections and tested to see how many random ints each of them can hold in a JVM with 1GB of memory (via -Xmx). For each data structure, we appended ints until we received an OutOfMemoryError, which ended the test. We ran each test 5 times on JDK 7 to ensure consistency. For such a fundamental test I found some of the results to be quite surprising. * I assume we’re all on the same page in that this isn’t a competition. Different collections have different semantics. I also didn’t include times, as the focus isn’t on micro-benchmarking performance, but on giving us a sense of how much the collections we use everyday can actually hold.
One of the fascinating things about our data structures is that even though we’re so familiar with them, it’s still hard for us to tell exactly how many items something as basic as a HashMap can hold in a 1GB of memory. We may learn this at school, from senior developers, or the hard way when our servers collapse due to poor choice of data structures. So I decided to do just that. I took ~20 of the most popular Java, Scala, Guava and Trove collections and tested to see how many random ints each of them can hold in a JVM with 1GB of memory (via -Xmx). For each data structure, we appended ints until we received an OutOfMemoryError, which ended the test. We ran each test 5 times on JDK 7 to ensure consistency. For such a fundamental test I found some of the results to be quite surprising. * I assume we’re all on the same page in that this isn’t a competition. Different collections have different semantics. I also didn’t include times, as the focus isn’t on micro-benchmarking performance, but on giving us a sense of how much the collections we use everyday can actually hold.
The Results
- Scala’s collections have greater capacity than Java’s. Scala collections seem to be slightly more efficient than their Java counterparts. While some collections such as TreeSets performed roughly the same, others such as Scala’s HashMaps were able to hold close to 15% more items. HashSets were able to hold 8% more items than their Java counterparts. I’d love to hear from the community why they think that is. Scala’s ArrayBuffer has a slight advantage over its ArrayList counterpart.
- The exception to that is Scala’s linked list which was able to hold 18% less data than Java’s LinkedList. A constraint here was that in order to append to the list it needed to receive another linked list instead of the direct value. Even so, that in itself should not affect the list’s capacity for holding within the 1GB JVM assuming the temporary list is GC’d.
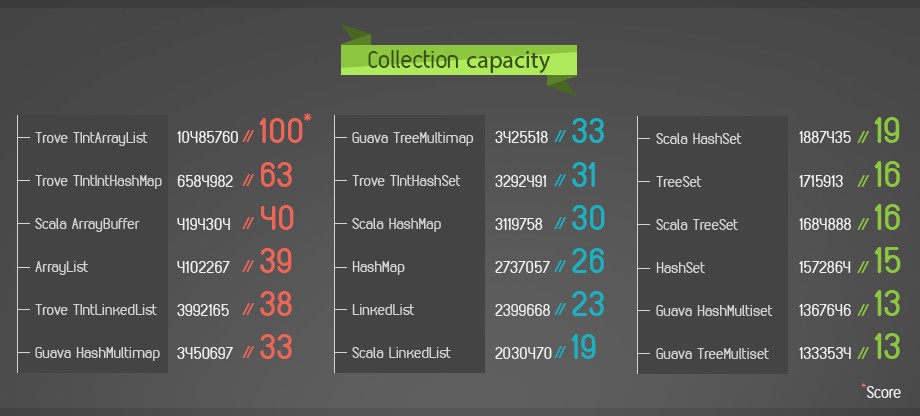
* We’re counting the number of ints held, which means 2 ints per map insertion.
- If you’re not using Trove you’re missing out. We’ve been using Trove’s collections on Takipi’s backend since day one. Well, sadly not from day one, as that would have saved us quite a lot of time optimizing server code. With TIntArrayList able to hold 250% of its Scala and Java boxed comparable, the numbers kinda speak for themselves.
- A similar ratio is observed for maps. It was quite surprising to see that Trove maps outperform Java and Scala lists by over 50% capacity. Remember that you also have Trove collections mapping between an int to an Object and vice versa, so you don’t need a fully primitive map to enjoy the capacity benefits.
- Even so, we still saw that Trove’s TIntLinkedList can hold less data than a Java ArrayList or a Scala ArrayBuffer who box their primitives. This really makes you look at a linked list which is used heavily in your code and reconsider – do I absolutely need it?
- Since there’s really no overhead in using Trove collections vs. standard library ones, I wouldn’t categorize using them as an “optimize on-demand” scenario. That’s because memory consumption bugs usually manifest under scale, where they’re the hardest to find and you have to start production debugging (of course Trove won’t save you from an inherently inefficient algorithm). It can sometime be the difference between analyzing a core dump and watching a Giants game.
- Guava – big maps, small sets. Guava’s multi sets are more costly than their Java and Scala counterparts. Compared to Scala’s set they were able to hold 19% less data. The flip side to this of course is that they can do things that aren’t possible using standard set semantics. Just make sure you need those if multisets are going to play a big part in your memory structure.
- With multimaps we see quite the reverse. Guava’s MultiHashMap was able to hold more than 20% more values than Java’s hashmap and 10% more than Scala’s. It was pretty counterintuitive to see that while Guava’s multisets underperform their Java and Scala equivalents in terms of capacity, MultiMaps actually outperform both Java and Scala.

There are a ton more collections types out there (queues, stacks, etc..), but I wanted to start with the basics and add more per popular demand. So if you want to see another collection on the list or want to shed some more light on some of the differences in capacity – the comments section is below and you know what to do.

I have a hypothesis for why the Scala List is coming out smaller. I wasn’t able to find the Scala test code on the GitHub site, so I couldn’t check to see if it is correct. The article says that you are appending to the List. I don’t know exactly what you were doing that with. The article mentions that you had to append a List instead of a single value (using ++ maybe?), but :+ or :+= should have been just fine for appending without that. However, any append operation on a Scala List uses a bunch of extra… Read more »
I would be very interested in seeing what happens with the Scala Vector type as well.
+1 for Scala Vector