JDK 7 is well into the hands of developers by now and most people have heard of ForkJoin, yet not so many have the time or chance in daily work to try it.
It caused, and probably still causes a bit of confusion on how is it any different than a normal thread pool.[1]
My goal in this article is to present a more elaborate, yet still simple example of ForkJoin usage through a code example.
I time and measure the performance of a Serial vs a Thread pool vs a ForkJoin aproach.
Here is the github upfront : https://github.com/fbunau/javaadvent-forkjoin
Practical problem
Imagine we have some sort of component in our system that keeps the last price of a stock for every millisecond of time.
This could be held in memory as an array of integers. (if we count in bps)
The clients of this component make queries like : what is the moment of time between time1 and time2 when the price was the lowest?
This could either be an automated algorithm or just someone in a GUI making rectangle selections.
![]()
7 queries in the example image
Let us also imagine that we get many such queries from a client batched up in a Task.
They may be batched up for reducing network traffic and round trip time.
We have different sizes of tasks that the component might get, up to 10 queries (someone with a GUI), up to 100, .. up to 1 000 0000 (some automated algorithm). We have many such clients for the component each producing tasks of different sizes. See Task.TaskType
Core problem and solution
The problem at it’s core we have to solve is the RMQ problem. Here is Wikipedia on it [2]:
"Given an array of objects taken from a well-ordered set (such as numbers), a Range Minimum Query (or RMQ) from i to j asks for the position of a minimum element in the sub-array A[i, j]."
"For example, A = [0, 5, 2, 5, 4, 3, 1, 6, 3] when , then the answer to the range minimum query for the A[3, 8] = [2, 5, 4, 3, 1, 6] is 7, as A[7] = 1 ."
There exists an efficient datastructure for solving this problem called “Segment Tree”.
I won’t go into detail on this as it is excellently covered in this classic Topcoder article [3]. This in itself is not important for this ForkJoin example, I have chosen this because it’s more interesting than a simple sum and it’s essence is kind of in the spirit of fork-join. It divides the task to be computed and then it join the results!
The data structure has O(n) initialization time and O(log N) query time, where N is the number of elements in our price per time unit value array.
So a task T contains M such queries to be made.
In an academic Computer Science approach you would just say that we’ll process each task with this efficient data structure and the complexity will be :
![]()
You can’t get more efficient than that !? Yes, in a theoretical von Neumann machine, but you can in practice.
An easy confusion to make is that because O(n/4) == O(n), then when writing a program constant factors don’t count, but they do!
Stop and think, is it the same to wait 10 or 40 minutes / hours / years ?
Going parallel
So thinking on the problem to be solved, how can we make it faster? Since every computing device now has more cores for computations, let’s put them to good use and do more things at once.
We can easily do that using the Fork Join framework.
I was first tempted to tweek the RMQ data structure and execute it’s operations in parallel. I attacked something that was already log N. But it was a big failure, it’s too much overhead for the scheduler to micromanage such short running logic.
The answer was in the end attack the M_i constant factor.
Thread pool
Before presenting how a ForkJoin solution might be applied, let’s imagine how we might apply a thread pool. See : TaskProcessorPool.java
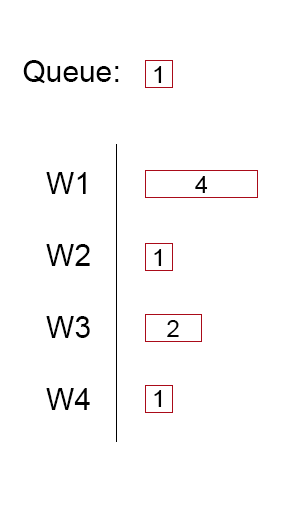
We can have a pool of 4 workers, when we have a Task to do, we add it to the queue. As soon as a worker is available, it will retrieve from the head of the queue a pending task, and execute it.
While this is fine for tasks having the same size, and the size is relatively medium and predictable, it runs into problems when the tasks to be executed are of different sizes. One worker might be choked up with a long running task, and the others sit doing nothing.
In this image the threadpool will do only 9 out of 16 possible units of work in the 4 units of time (56% efficiency), if no more tasks will be added to the queue
Fork Join
Fork join is useful when you are in a problem domain where you can split the task to be solved into smaller ones.
What is special about a fork-join pool is that it is a work-stealing thread pool.
Each worker thread maintains a local dequeue of tasks. When taking a new task for execution it can either :
- split the task into smaller ones
- execute the task if it’s small enough
When a thread has no local threads in it’s dequeue, it ‘steals’ , pops tasks from the back of the queue of another random thread, and puts it in his own. There is a high chance that this task is not yet split. So he’ll have quite some work on his hands.
Comparing to the thread pool, instead of the other threads waiting for some new work, they could split the existing task into smaller ones and help the other thread with that large task.
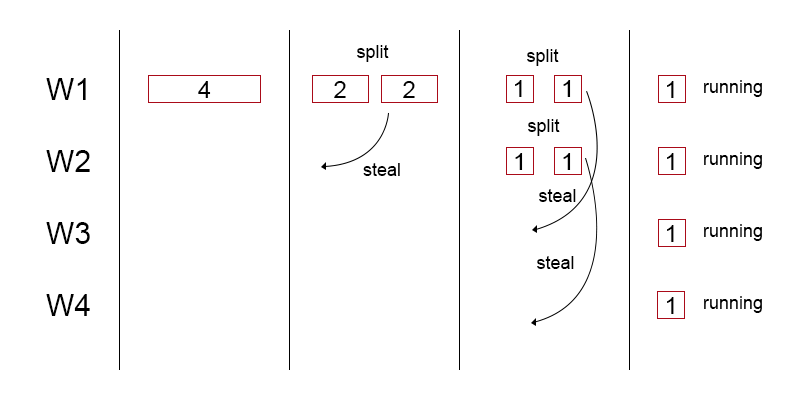
Here is the original paper by Doug Lea for a more detailed explanation : http://gee.cs.oswego.edu/dl/papers/fj.pdf
Coming back to our example a large batch of operations could be split into multiple batches of smaller number of operations. See : TaskProcessorFJ.java
Most problems have linear series of operations like this one, it doesn’t have to be a special parallel problem for which we need to apply a specialized parallel algorithm to leverage the cores we have on the processor.
How much do you split? You split a task until you reach a threshold where generally splitting makes no sense anymore. Ex : ( splitting + a thread getting a job + context switching is more than actually executing the task as it is )
For a big XXL, task we have to do 1000000 query operations. We could split this into 2 500000 operation tasks, and do that in parallel. Is 500000 still large? Yes, we can split it more. I have chosen a group of 10000 operations to be the threshold under which there is no use in splitting and we can just execute them on the current thread.
Fork join does not split all the tasks upfront, but rather as it works through it.
Performance results
I ran 4 iterations for each implementation of processor on my i5-2500 CPU @ 3.30GHz that has 4 cores / 4 threads, after a clean reboot
Here are the results :
Doing 4 runs for each of the 3 processors. Pls wait ... TaskProcessorSimple: 7963 TaskProcessorSimple: 7757 TaskProcessorSimple: 7748 TaskProcessorSimple: 7744 TaskProcessorPool: 3933 TaskProcessorPool: 2906 TaskProcessorPool: 4477 TaskProcessorPool: 4160 TaskProcessorFJ: 2498 TaskProcessorFJ: 2498 TaskProcessorFJ: 2524 TaskProcessorFJ: 2511 Test completed.
Conclusions
Even if you have chosen the right optimal data structure, it’s not fast until you use all the resources you have. i.e. exploiting all cores
ForkJoin is definetly an improvement over the thread pool in certain problem domains and it’s worth exploring where it can be applied, and we’ll get to see more and more parallel code.
This is the kind of processor you can buy today 12 cores / 24 threads. Now we just have to write the software to exploit the cool hardware that we have and will get in the future.
The code is here : https://github.com/fbunau/javaadvent-forkjoin if you want to play with it
Thanks for your time, drop some comments if you see any errors or have things to add.
