Our research labs are humming at full speed. With the recent injection of capital, we can only warrant that the pace at which we keep innovating will only increase. Part of the research we conduct is related to GC optimizations. While dealing with the problems in this interesting domain, we thought to share some insights to GC algorithm usage.
For this we conducted a study on how often a particular GC algorithm is being used. The results are somewhat surprising. Let me start with the background of the data – we had access to data from 84,936 sessions representing 2670 different environments to use in the study. 13% of the environments had explicitly specified a GC algorithm. The rest left the decision to the JVM. So out of the 11,062 sessions with explicit GC algorithm, we were able to distinguish six different GC algorithms:
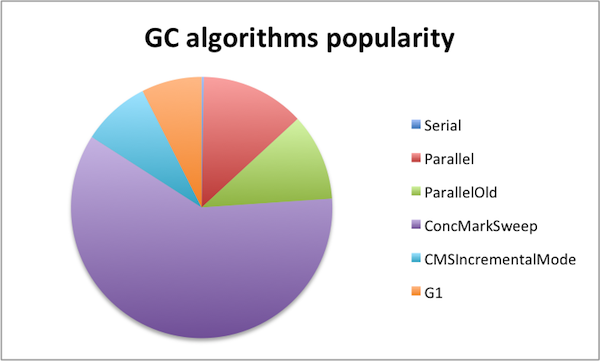
Before understanding the details about the GC algorithm usage, we should stop for a minute and try to understand why 87% of the runs are missing from the pie chart above. In our opinion, this is a symptom of two different underlying reasons
- First and good reason is that – the JVM has gotten so good at picking reasonable defaults that the developers just do not need to dig under the hood anymore. If your application throughput and latency are sufficient then indeed – why bother?
- The second likely cause for the lack of the GC algorithm indicates that the application performance has not been a priority to the team. As our case study from last year demonstrated – significant improvements in throughput and latency can be just one configuration tweak away.
So, we have close to 83,000 JVMs running with the default GC selection. But what is the default? The answer is both simple and complex at the same time. If you are considered to be running on a client JVM, the default applied by the JVM would be Serial GC (-XX:+UseSerialGC). On server-class machines the default would be Parallel GC (-XX:+UseParallelGC). Whether you are running on a server or client class machine can be determined based on the following decision table:
| Architecture | CPU/RAM | OS | Default |
| i586 | Any | MS Windows | Client |
| AMD64 | Any | Any | Server |
| 64-bit SPARC | Any | Solaris | Server |
| 32-bit SPARC | 2+ cores & > 2GB RAM | Solaris | Server |
| 32-bit SPARC | 1 core or < 2GB RAM | Solaris | Client |
| i568 | 2+ cores & > 2GB RAM | Linux or Solaris | Server |
| i568 | 1 core or < 2GB RAM | Linux or Solaris | Client |
But lets go back to the 13% who have explicitly specified the GC algorithm in the configuration. It starts with the good old serial mode, which, by no surprise has so small user base that it is barely visible from the diagram above. Indeed, just 31 environments were sure this is the best GC algorithm and had specified this explicitly. Considering that most of the platforms today are running on multi-core machines you should not be surprised – when you have several cores at your disposal, the switch from serial mode is almost always recommended.
| GC | Count |
| Serial | 31 |
| Parallel | 1,422 |
| ParallelOld | 1,193 |
| ConcMarkSweep | 6,655 |
| CMSIncrementalMode | 935 |
| G1 | 826 |
The rest of the configuration can be divided into three groups – parallel, concurrent and G1. The winner is clear – Concurrent Mark and Sweep algorithms combined represent more than two thirds of the samples. But let us look at the results in more depth.
Parallel and ParallelOld modes are roughly in the same neighbourhood with 1,422 and 1,193 samples. It should not be a surprise – if you have decided that parallel mode is suitable for your young generation then more often than not the same algorithm for the old generation is also performing well. Another interesting aspect in parallel modes is that – as seen from the above, the parallel mode is default on the most common platforms, so the lack of explicit specification does not imply it is less popular than the alternatives.
With CMS usage, our expectations were different though. Namely – that the incremental mode was switched on only on 935 occasions compared to the classical CMS with its 6,655 configurations. To remind you – during a concurrent phase the garbage collector thread is using one or more processors. The incremental mode is used to reduce the impact of long concurrent phases by periodically stopping the concurrent phase to yield back the processor to the application. This results in shorter pause times especially on machines with low processor numbers. Whether the environments were all having bazillion cores or the people responsible for configuration are just not aware of the incremental mode benefits is currently unclear.
But our biggest surprise was related to the G1 adoption rate. 826 environments were running with G1 as the garbage collection algorithm. Based on our experience, independent of whether you are after throughput or latency, the G1 tends to perform worse than CMS. Maybe the selection of test cases we have had access to has been poor, but at the moment we consider G1 to need more time to be actually delivering on its promises. So if you are a happy G1 user, maybe you can share your experience with us?
