Finding resource leaks using Java-monitor
Finding slow resource leaks is key to keeping your application servers up and running for very long times. Here I explain how I use Java-monitor to spot slow resource leaks and how to verify that they are actual leaks and not just extra pre-allocation into some HTTP connector or database pool. If you follow these steps you can get out of the periodic restart and really start relying on your servers.
Slow resource leaks are a problem because they force you to restart your application server periodically. That in turn means that you always have to keep your eyes on the servers because they might blow up at any time. Ultimately, you cannot rely on servers that suffer from slow resource leaks. Tracking down and resolving slow resource leaks takes time and patience. It is not really hard to do, once you did it a few times.
You also need a monitoring tool that shows statistics from your server over weeks or even months. You can do this with Java-monitor if you enable longer data storage on your servers. To enable this in Java-monitor first start using Java-monitor for your servers. On the page with the graphs of your server, you can enable the longer data by switching to the “1 week” or “1 month” view, as shown below.
The first step is to look at a server’s data over the past week. For finding resource leaks, I find that plotting data over a week gives me a better view than Java-monitor’s standard two days of data does. Peaks smooth out and the graphs allow me to look at how for example memory use develops over time.
In order to predict impending outages and slow resource leaks I look for two patterns. The first pattern to check is that the resource usage does not rise over time, but instead rises and falls with the daily tide of traffic increasing and deceasing. When a day’s traffic has subsided, I expect the resource usage to drop back to a nominal level. I check that resource usage drops back to the same level every time.
Note that I deliberately use a vague term like ‘resource’. In practise I look at all graphs for memory, file descriptors and HTTP connector and database connection pools. All of these are candidates for slow resource leakage.
When I see a resource that seems to be growing slightly I switch to the monthly view of the data, or even the yearly view. This compresses the data in the graph and makes slow resource leaks much easier to spot.
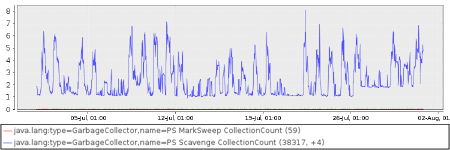
Here is an example of a suspicious change in resource usage. In this case suddenly the garbage collectors on the system became more active. There was no change in the system or the system’s load at the time of this chance.
The second pattern I look out for is steep drops of resource allocation after server restarts restarts. When there is a significant drop in resource usage when an application server was restarted, this may indicate a slow resource leak. After a restart, it is normal to lower resource usage as before a restart, since all pools and caches begin empty.
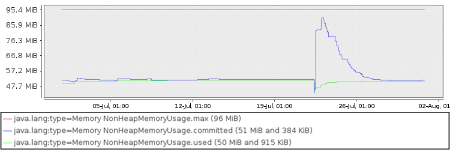
Here is an example of restart related change in resource usage that does not indicate a problem. For some time after the restart (a few days even) the resource usage has changed, but it then returns to its normal level and stays there.
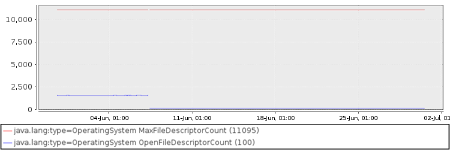
And here is another one. Even more suspicious, because the resource usage does not grow back after a restart. It just drops and stays down. This is almost certainly a problem.
Once I identified a resource usage pattern as suspicious, I have to confirm that this is actually a slow leak. It may well be a cache or a pool filled up some more, leading to higher resource usage over time, without being an actual leak. In this step I flip though the graphs of thread and database pools and the graphs for HTTP sessions. I try to explain the elevated resource use from there graphs.
For example, here we see the threads that are active in a JVM, with some strange dips in the number of threads. These dips show around system restarts.
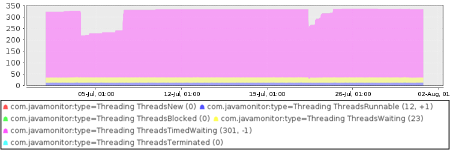
However, if I compare that graph with the HTTP connector pool graph on the same server I see that the number of pre-allocated threads in an HTTP connector pool has similarly wobbled up and down.
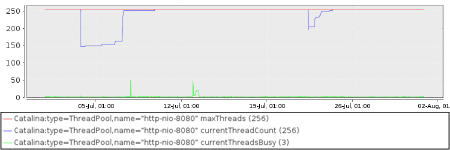
This probably means there is no slow resource leak. Most likely, the extra threads in the pool keep state around that causes the other resources to also grow. I might make a note to keep an eye on this server specifically, but I don’t start digging into the resource leak just yet.
Only when I cannot explain the extra resources allocated from the pools and number of active HTTP session I start really digging. As explained next: how to find the root cause of slow resource leaks.
Fixing Slow Resource Leaks
We looked at how to spot slow memory leaks earlier. In that, we saw how to find slow resource leaks and how to distinguish those from the expected pool growth behaviour.
Here, I’d like to explain how I go about identifying the root cause of slow resource leaks and ultimately how to fix them. Fixing slow resource leaks almost always requires code changes, so if you are not in the position to change the code, you cannot fix slow resource leaks. In that case, you will have to find someone who can.
The process of identifying the root cause of a slow resource leak is similar to the process of finding a fast leak. The main difference is that time is very much against you. Where for a fast leak you can easily do a few iterations, slow leaks may take weeks or months to manifest. There iterations may well be a quarter of a year. For faster leaks, you can get away with some quick code changes and ‘see how it does on live’. For slower leaks that just means you’ll never find the real problem.
Steps to follow are:
- identify leaking resource (done, yay!)
- gather evidence regarding that resource
- develop a thesis on what is the problem and see if the evidence supports you
- present your analysis to someone you know will rip your proof to shreds
- devise and implement fix
Note how we usually only quickly do step 3 and then spend all of our energy on step 5, only to find that the real problem was something else. I should know, because I too make that mistake more often than I care to admit.
Once I know what resource is leaking (e.g. memory, file descriptors, CPU cycles, threads), I start gathering evidence about the leak. This evidence comes from several sources. If the leaking resource is something that is used only very little in your code, the application source code is a good place to start gathering. If this is something that is used everywhere (like memory for instance) looking at the source code is usually time consuming and not very productive. So here’s a cheat sheet where I look for evidence:
- Memory
—-> heap dumps - File descriptors
—-> Java-monitor’s thread pool graphs and also lsof or sockstat - CPU
—-> thread dumps - Threads
—-> Java-monitor’s thread pool graphs and thread dumps - database connections
—-> enable resource leak detection on JDBC driver
When gathering evidence, it is important to keep an open mind. It is very tempting to jump to conclusions about what is happening. Instead, just look at the cool evidence and eliminate possible problems.
A critical step is to present your evidence and line of thought to someone that is not afraid to challenge you. This step is to guard you from making a mistake in the analysis and having to wait a few weeks before you find out you were wrong. At this stage, someone who just nods and applauds may do more harm than good, however good that person’s intentions. Find the right person and tell that person that you need a critical review.
Once your analysis survived that challenge, you can finally start thinking about a solution. The solution needs to have two parts: 1) it needs to improve logging and monitoring in such a way that the system gives you evidence about the problem you just found and 2) it needs to actually solve the problem.
In the off chance that your solution was not correct, the improved logging will give you fresh new evidence to look at for your second (and hopefully final!) iteration.
