Talk to any programmer and ask him how a merge should be: “it should understand the code, parse it, and then merge based on the structure” – he’ll most likely say.
And this is precisely what SemanticMerge for Java does: it parses the files to be merged (plus the ancestor or “how the files were before changing them”) and acts based on that information.
Why all this buzz about merging?
Developing software is a collaborative process. If you work on a team, sooner or later you’ll end up having two developers modifying the same file. Whenever that happens
you’ll have to merge. In fact, merging is not bound to creating branches (as many will say) but to developers working on the same files, even if they do it on the same branch (if two work on the same branch, on the same files, one of them will have to merge during check-in – or “commit” in Git jargon).
The new wave of distributed version control systems (DVCS) do a much better job than the previous generation when it comes to merging. That’s why many jumped to Git from SVN, CVS, and older alternatives.
The next step is not only a better algorithm in terms of how to deal with the files, the next step is creating a better mechanism to merge “inside the file”, and this is exactly what SemanticMerge is all about.
SemanticMerge is about reducing the cost of keeping the code clean
There are two graphics that we always keep in mind when developing merge tools: the cost of change by Barry Bohem back in 1981 and the same graph by Kent Beck 20 years later:
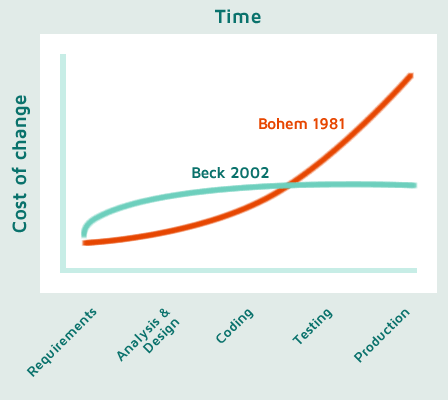
Generations of developers were taught the “Bohem’s principle”: “do a change in production and it will cost you a fortune compared to the same change introduced during the analysis phase”.
Then Beck came up with something like: “keep your code clean and the cost of change will remain constant”, which is the cornerstone behind the agile methods.
And this is precisely the mantra behind SemanticMerge: keep your code clean. Why? Because it pays off.
More often than not, you see a class that needs to be rearranged: “put these two private methods down, move the public constructor up, move the private fields to the bottom…” But the reason you don’t do it is because maybe someone else is touching the file and the merge is going to be hell. This is exactly what SemanticMerge solves: it “knows” you moved a method, so it won’t be fooled by that.
SemanticMerge in action
Let’s now look into a typical semantic merge case. Suppose you have a class with several methods. The first developer moves one of the methods to a different location within the class and also modifies the method. Meanwhile, a second developer modifies the method on the original location.
Check out the following figure:
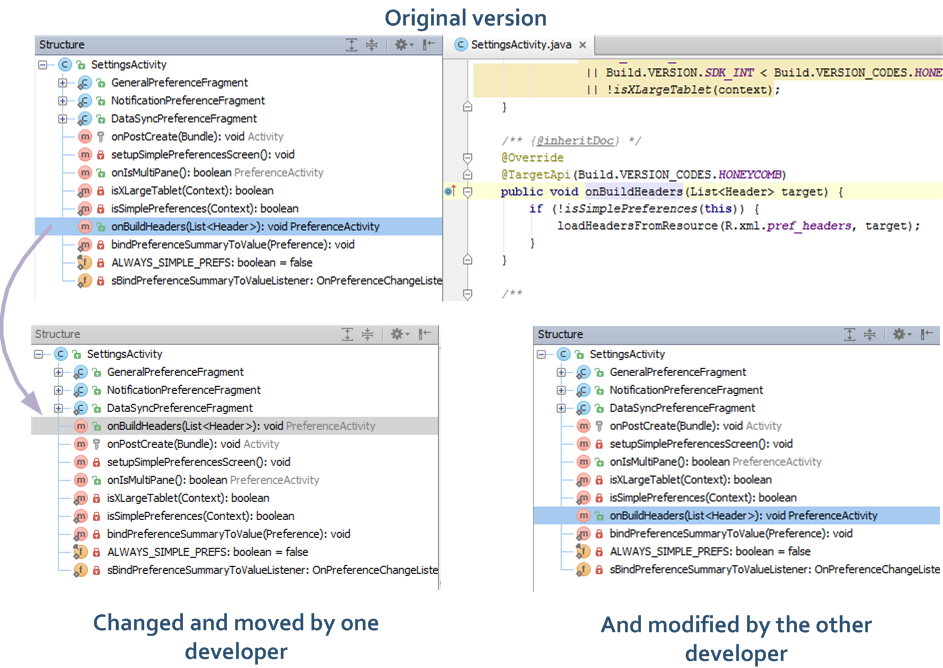
A regular, text-based merge tool would fail handling this scenario, but SemanticMerge is able to identify what happened to the method and propose the following merge situation:
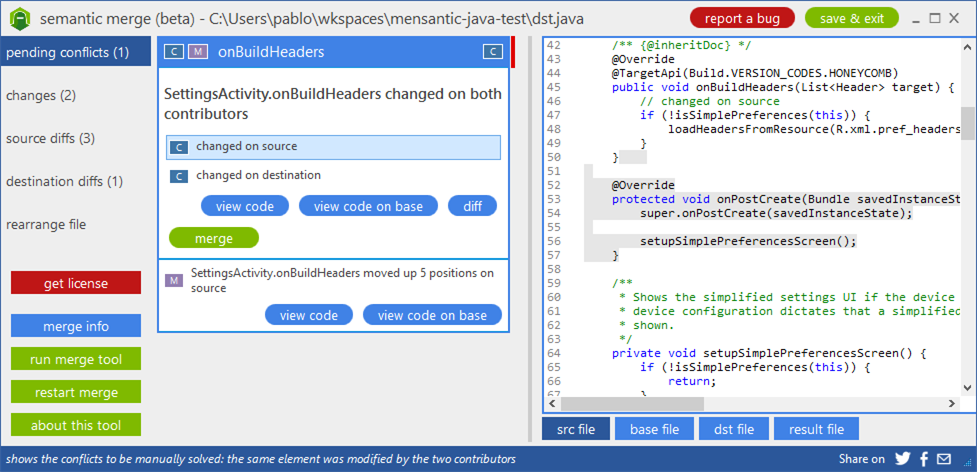
As you can see, it identifies that the method “onBuildHeaders” has been modified in parallel (check the “c” icon at both sides of the bar where the method name is printed) and also moved in one of the contributors (check the “m” icon).
Now the developer doing the merge can go and run “merge” on the “onBuildHeaders” method, which will merge only the conflicting method, preserving the new location.
How does SemanticMerge work?
As you may guess, SemanticMerge first parses the code of the 3 files involved (the original file plus the two contributors) and then calculates the structures of each of them: it is a tree-like representation of the code.
Once this is done, SemanticMerge starts working with the 3 trees: first it calculates the diffs between one of the contributors and the original version, then it repeats the process with the other contributor.
Step three is the merge calculation itself: it will walk the two pairs of diffs and will check whether they collide. If they do, then there is a merge conflict. It can happen if the same method has been moved or modified twice and so on. The calculation is slightly more complex because the conflicts must be calculated not only when the same method collides but also if there are conflicts in their containers (like doing a “divergent” rename between parent classes and so on).
It is also worth adding that in order to track methods (or fields, properties, and so on) when they are renamed, SemanticMerge calculates a “similarity index” to see how close the bodies of the methods are, and when the match is good, it assumes it is the same element.
Some numbers
We rerun about 40 thousand merges downloading close to 500 open source projects. This means we pull the repositories, find all the merges, and run them again through the SemanticMerge tool.
Doing that we found the following numbers:
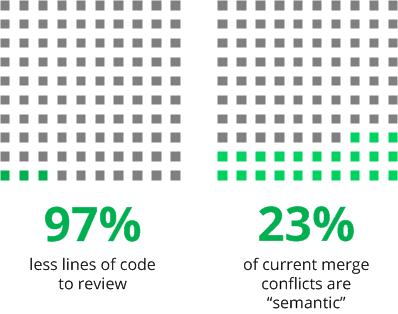
- 23% of the current merges are “semantic” – which mean they have something that is not a “changed-changed” conflict. It can be code being moved, more than one method being added on the same position, methods moved and changed, and many more.
- Out of these 40 thousand merges run, we found out that 1.54% of the merges go from manual to totally automatic. It is not a huge number which means it will grow as soon as teams start using SemanticMerge. (These numbers are the result of rerunning merges done with current language-agnostic merge tools, so developers tend to avoid complex changes on files).
- We counted the number of lines involved in merge conflicts while running the code through both SemanticMerge and a conventional text-based merge tool and we found out that using SemanticMerge, there are 97% less lines of code involved in conflicts… which means much less work to do!!
Free for Open Source
While testing SemanticMerge we pulled about 500, long-lived, frantically active, Open Source repositories and we “replayed” all their merges. In the list, there were repositories like hibernate, openjdk, apache-lucene, jbos, monodevelop, mono, monomac, monogame, nhibernate… and it was really helpful.
So we decided to make SemanticMerge free for the developers contributing to Open Source projects, because we believe in contributing back. You may check it out here!
