The motivation is that garbage collection related questions keeps coming up in variety of circumstances, including (for example) on the Cassandra mailing list. The problem when trying to help is that explaining the nuances of garbage collection is too much of an effort to do ad-hoc in a mailing list reply tailored to that specific situation, and you rarely have enough information about the situation to tell someone what their particular problem is caused by.
I hope that this guide will be something I can point to in answering these questions. I hope that it will be detailed enough to be useful, yet easy to digest and non-academic enough for a broad audience.
I very much appreciate any feedback on what I need to clarify, improve, rip out completely, etc.
Much of the information here is not specific to Java. However, in order to avoid constantly invoking generic and abstract terminology, I am going to speak in concrete terms of the Hotspot JVM wherever possible.
Why should anyone have to care about the garbage collector?
That is a good question. The perfect garbage collector would do its job without a human ever noticing that it exists. Unfortunately, there exists no known perfect (whatever perfection means) garbage collection algorithm. Further, the selection of garbage collectors practically available to most people is additionally limited to a subset of garbage collection algorithms that are in fact implemented. (Similarly, malloc is not perfect either and has its issues, with multiple implementations available with different characteristics. However, this post is not trying to contrast automatic and explicit memory management, although that is an interesting topic.)
The reality is that, as with many technical problems, there are some trade-offs involved. As a rule of thumb, if you’re using the freely available Hotspot based JVM:s (Oracle/Sun, OpenJDK), you mostly notice the garbage collector if you care about latency. If you do not, chances are the garbage collector will not be a bother – other than possibly to select a maximum heap size different from the default.
By latency, in the context of garbage collection, I mean pause times. The garbage collector needs to pause the application sometimes in order to do some of its work; this is often referred to as a stop-the-world pause (the “world” being the observable universe from the perspective of the Java application, or mutator in GC speak (because it is mutating the heap while the garbage collector is trying to collect it). It is important to note that while all practically available garbage collectors impose stop-the-world pauses on the application, the frequency and duration of these pauses vary greatly with the choice of garbage collector, garbage collector settings, and application behavior.
As we shall see, there exists garbage collection algorithms that attempt to avoid the need to ever collect the entire heap in a stop-the-world pause. The reason this is an important property is that if at any point (even if infrequent), you stop the application for a complete collection of the heap, the pause times suffered by the application scale proportionally to the heap size. This is typically the main thing you want to avoid when you care about latency. There are other concerns as well, but this is usually tbe big one.
Tracing vs. reference counting
You may have heard of reference counting being used (for example, cPython uses a reference counting scheme for most of it’s garbage collection work). I am not going to talk much about it because it is not relevant to JVM:s, except to say two things:
- One property that reference counting garbage collection has is that an object will be known to be unreachable immediately at the point where the last reference is removed.
- Reference counting will not detect as unreachable cyclic data structures, and has some other problems that cause it to not be the end-all be-all garbage collection choice.
The JVM instead uses what is known as a tracing garbage collector. It is called tracing because, at least at an abstract level, the process of identifying garbage involves taking the root set (things like your local variables on your stack or global variables) and tracing a path from those objects to all objects that are directly or indirectly reachable from said root set. Once all reachable (live) objects have been identified, the objects eligible for being freed by the garbage collector have been identified by a proces of elimination.
Basic stop-the-world, mark, sweep, resume
A very simple tracing garbage collector works using the following process:
- Pause the application completely.
- Mark all objects that are reachable (from the root set, see above) by tracing the object graph (i.e., following references recursively).
- Free all objects that were not reachable.
- Resume the application.
In a single-threaded world, this is pretty easy to imagine: The call that is responsible for allocating a new object will either return the new object immediately, or, if the heap is full, initiate the above process to free up space, followed by completing the allocation and returning the object.
None of the JVM garbage collectors work like this. However, it is good to understand this basic form of a garbage collector, as the available garbage collectors are essentially optimizations of the above process.
The two main reasons why the JVM does not implement garbage collection like this are:
- Every single garbage collection pause will be long enough to collect the entire heap; in other words, it has very poor latency.
- For almost all real-world applications, it is by far not the most efficient way to perform garbage collection (it has a high CPU overhead).
Compacting vs. non-compacting garbage collection
An important distinction between garbage collectors is whether or not they are compacting. Compacting refers to moving objects around (in memory) to as to collect them in one dense region of memory, instead of being spread out sparsely over a larger region.
Real-world analogy: Consider a room full of things on the floor in random places. Taking all these things and stuffing them tightly in a corner is essentially compacting them; freeing up floor space. Another way to remember what compaction is, is to envision one of those machines that take something like a car and compact it together into a block of metal, thus taking less space than the original car by eliminating all the space occupied by air (but as someone has pointed out, while the car id destroyed, objects on the heap are not!).
By contrast a non-compacting collector never moves objects around. Once an object has been allocated in a particular location in memory, it remains there forever or until it is freed.
There are some interesting properties of both:
- The cost of performing a compacting collection is a function of the amount of live data on the heap. If only 1% of data is live, only 1% of data needs to be compacted (copied in memory).
- By contrast, in a non-compacting collector objects that are no longer reachable still imply book keeping overhead as their memory locations must be kept track of as being freed, to be used in future allocations.
- In a compacting collector, allocation is usually done via a bump-the-pointer approach. You have some region of space, and maintain your current allocation pointer. If you allocate an object of n bytes, you simply bump that pointer by n (I am eliding complications like multi-threading and optimizations that implies).
- In a non-compacting collector, allocation involves finding where to allocate using some mechanism that is dependent on the exact mechanism used to track the availability of free memory. In order to satisfy an allocation of n bytes, a contiguous region of n bytes free space must be found. If one cannot be found (because the heap is fragmented, meaning it consists of a mixed bag of free and allocated space), the allocation will fail.
Real-world analogy: Consider your room again. Suppose you are a compacting collector. You can move things around on the floor freely at your leisure. When you need to make room for that big sofa in the middle of the floor, you move other things around to free up an appropriately sized chunk of space for the sofa. On the other hand, if you are a non-compacting collector, everything on the floor is nailed to it, and cannot be moved. A large sofa might not fit, despite the fact that you have plenty of floor space available – there is just no single space large enough to fit the sofa.
Generational garbage collection
Most real-world applications tend to perform a lot allocation of short-lived objects (in other words, objects that are allocated, used for a brief period, and then no longer referenced). A generational garbage collector attempts to exploit this observation in order to be more CPU efficient (in other words, have higher throughput). (More formally, the hypothesis that most applications have this behavior is known as the weak generational hypothesis.)
It is called “generational” because objects are divided up into generations. The details will vary between collectors, but a reasonable approximation at this point is to say that objects are divided into two generations:
- The young generation is where objects are initially allocated. In other words, all objects start off being in the young generation.
- The old generation is where objects “graduate” to when they have spent some time in the young generation.
The reason why generational collectors are typically more efficient, is that they collect the young generation separately from the old generation. Typical behavior of an application in steady state doing allocation, is frequent short pauses as the young generation is being collected – punctuated by infrequent but longer pauses as the old generation fills up and triggers a full collection of the entire heap (old and new). If you look at a heap usage graph of a typical application, it will look similar to this:
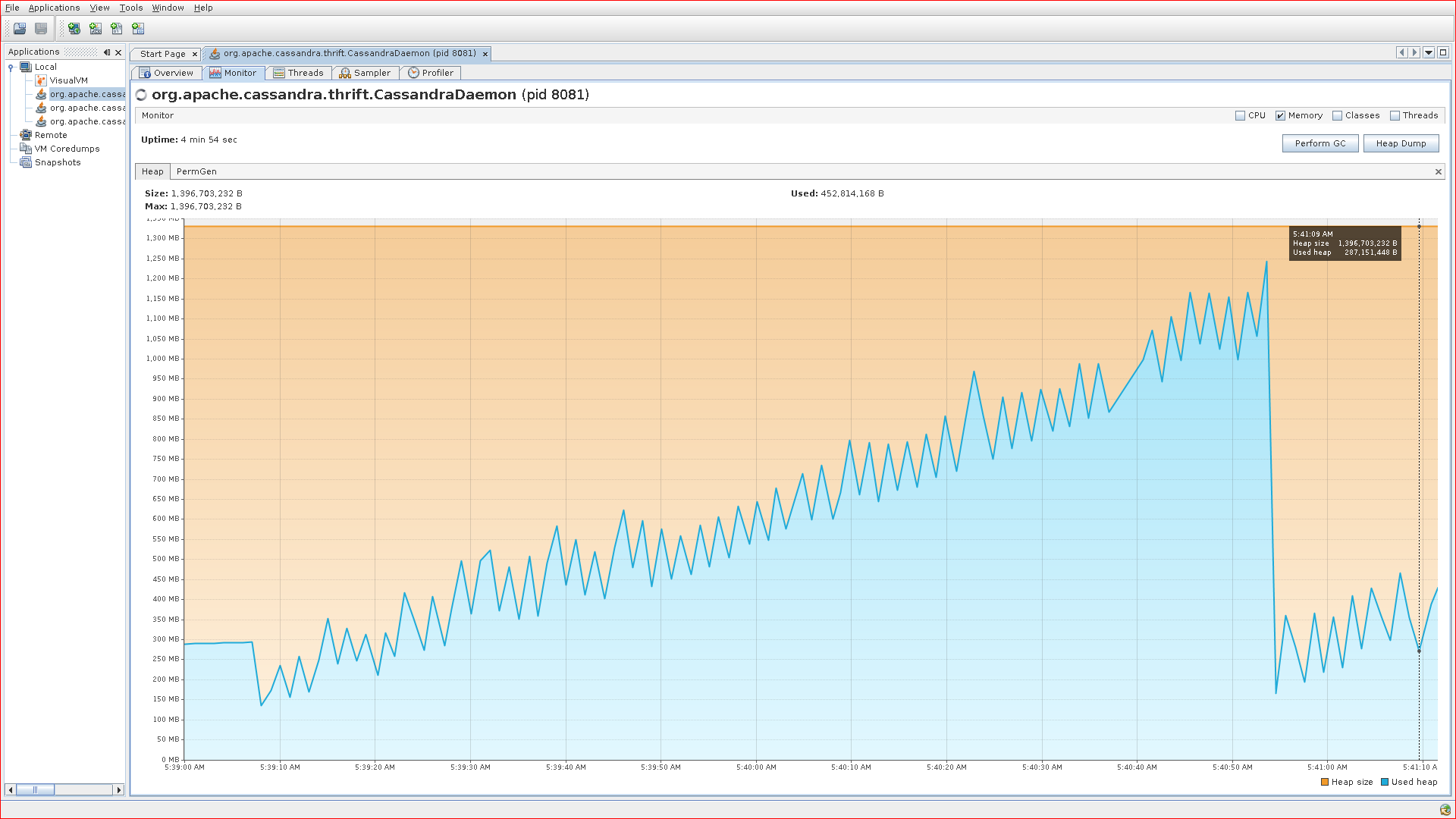 |
| Typical sawtooth behavior of heap usage with the throughput collector |
The ongoing sawtooth look is a result of young generation garbage collections. The large dip towards the end is when the old generation became full and the JVM did a complete collection of the entire heap. The amount of heap usage at the end of that dip is a reasonable approximation of the actual live set at that point in time. (Note: This is a graph from running a stress test against a Cassandra instance configured to use the default JVM throughput collector; it does not reflect out-of-the-box behavior of Cassandra.)
Note that simply picking the “current heap usage” at an arbitrary point in time on that graph will not give you an idea of the memory usage of the application. I cannot stress that point enough. What is typically considered the memory “usage” is the live set, not the heap usage at any particular time. The heap usage is much more a function of the implementation details of the garbage collector; the only effect on heap usage from the memory usage of the application is that it provides a lower bound on the heap usage.
Now, back to why generational collectors are typically more efficient.
Suppose our hypothetical application is such that 90% of all objects die young; in other words, they never survive long enough to be promoted to the old generation. Further, suppose that our collection of the young generation is compacting (see previous sections) in nature. The cost of collecting the young generation is now roughly that of tracing and copying 10% of the objects it contains. The cost associated with the remaining 90% was quite small. Collection of the young generation happens when it becomes full, and is a stop-the-world pause.
The 10% of objects that survived may be promoted to the old generation immediately, or they may survive for another round or two in young generation (depending on various factors). The important overall behavior to understand however, is that objects start off in the young generation, and are promoted to the old generation as a result of surviving in the young generation.
(Astute readers may have noticed that collecting the young generation completely separately is not possible – what if an object in the old generation has a reference to an object in the new generation? This is indeed something a garbage collector must deal with; a future post will talk about this.)
The optimization is quite dependent on the size of the young generation. If the size is too large, it may be so large that the pause times associated with collecting it is a noticeable problem. If the size is too small, it may be that even objects that die young do not die quite quickly enough to still be in the young generation when they die.
Recall that the young generation is collected when it becomes full; this means that the smaller it is, the more often it will be collected. Further recall that when objects survive the young generation, they get promoted to the old generation. If most objects, despite dying young, never have a chance to die in the young generation because it is too small – they will get promoted to the old generation and the optimization that the generational garbage collector is trying to make will fail, and you will take the full cost of collecting the object later on in the old generation (plus the up-front cost of having copied it from the young generation).
Parallel collection
The point of having a generational collector is to optimize for throughput; in other words, the total amount of work the application gets to do in a particular amount of time. As a side-effect, most of the pauses incurred due to garbage collection also become shorter. However, no attempt is made to eliminate the periodic full collections which will imply a pause time of whatever is necessary to complete a full collection.
The throughput collector does do one thing which is worth mentioning in order to mitigate this: It is parallel, meaning it uses multiple CPU cores simultaneously to speed up garbage collection. This does lead to shorter pause times, but there is a limit to how far you can go – even in an unrealistic perfect situation of a linear speed-up (meaning, double CPU count -> half collection time) you are limited by the number of CPU cores on your system. If you are collecting a 30 GB heap, that is going to take some significant time even if you do so with 16 parallel threads.
In garbage collection parlance, the word parallel is used to refer to a collector that does work on multiple CPU cores at the same time.
Incremental collection
Incremental in a garbage collection context refers to dividing up the work that needs to be done in smaller chunks, often with the aim of pausing the applications for multiple brief periods instead of a single long pause. The behavior of the generational collector described above is partially incremental in the sense that the young generation collectors constitute incremental work. However, as a whole, the collection process is not incremental because of the full heap collections incurred when the old generation becomes full.
Other forms of incremental collections are possible; for example, a collector can do a tiny bit of garbage collection work for every allocation performed by the application. The concept is not tied to a particular implementation strategy.
Concurrent collection
Concurrent in a garbage collection context refers to performing garbage collection work concurrently with the application (mutator). For example, on an 8 core system, a garbage collector might keep two background threads that do garbage collection work while the application is running. This allows significant amounts of work to be done without incurring an application pause, usually at some cost of throughput and implementation complexity (for the garbage collector implementor).
Available Hotspot garbage collectors
The default choice of garbage collector in Hotspot is the throughput collector, which is a generational, parallel, compacting collector. It is entirely optimized for throughput; total amount of work achieved by the application in a given time period.
The traditional alternative for situations where latency/pause times are a concern, is the CMS collector. CMS stands for Concurrent Mark & Sweep and refers to the mechanism used by the collector. The purpose of the collector is to minimize or even eliminate long stop-the-world pauses, limiting garbage collection work to shorter stop-the-world (often parallel) pauses, in combination with longer work performed concurrently with the application. An important property of the CMS collector is that it is not compacting, and thus suffers from fragmentation concerns (more on this in a later blog post).
As of later versions of JDK 1.6 and JDK 1.7, there is a new garbage collector available which is called G1 (which stands for Garbage First). It’s aim, like the CMS collector, is to try to mitigate or eliminate the need for long stop-the-world pauses and it does most of it’s work in parallel in short stop-the-world incremental pauses, with some work also being done concurrently with the application. Contrary to CMS, G1 is a compacting collector and does not suffer from fragmentation concerns – but has other trade-offs instead (again, more on this in a later blog post).
Observing garbage collector behavior
I encourage readers to experiment with the behavior of the garbage collector. Use jconsole (comes with the JDK) or VisualVM (which produced the graph earlier on in this post) to visualize behavior on a running JVM. But, in particular, start getting familiar with garbage collection log output, by running your JVM with (updated with jbellis’ feedback – thanks!):
-XX:+PrintGC-XX:+PrintGCDetails-XX:+PrintGCDateStamps-XX:+PrintGCApplicationStoppedTime-XX:+PrintPromotionFailure
Also useful but verbose (meaning explained in later posts):
-XX:+PrintHeapAtGC-XX:+PrintTenuringDistribution-XX:PrintFLSStatistics=1
The output is pretty easy to read for the throughput collector. For CMS and G1, the output is more opaque to analysis without an introduction. I hope to cover this in a later update.
In the mean time, the take-away is that those options above are probably the first things you want to use whenever you suspect that you have a GC related problem. It is almost always the first thing I tell people when they start to hypothesize GC issues; have you looked at GC logs? If you have not, you are probably wasting your time speculating about GC.
Conclusion
I have tried to produce a crash-course introduction that I hope was enlightening in and of itself, but is primarily intended as background for later posts. I welcome any feedback, particularly if things are unclear or if I am making too many assumptions. I want this series to be approachable by a broad audience as I said in the beginning, though I certainly do assume some level of expertise. But intimate garbage collection knowledge should not be required. If it is, I have failed – please let me know.
Reference: Practical Garbage Collection, part 1 – Introduction from our JCG partner Peter Schuller at the (mod :world :scode) blog

Hi,
Silly question – the point of GC is to clear out those objects that are no longer referenced. Given this why do we care about mutators. Definitionally if I’ve identified something as collectable then nothing, including mutators reference it / can modify it.
Thanks,
Allan.