In this post I am going to share my experience with categorizing unstructured data in URLs. I ended up applying TF-IDF algorithm to solve the problem at hand and thought the experience would be interesting to share.
The post is focusing solely on the problem solving, but as the context used is related to Plumbr then first some background for readers unfamiliar with Plumbr:
- Plumbr monitors end user interactions with the applications. Each of such interactions is called a transaction
- Transactions are grouped together by the actual endpoint consumed. For example if the user clicked on the “Add to shopping cart” button in the web application, the endpoint extracted from such an URL might be “/cart/add/{item}”. These endpoints are called services.
Plumbr also exposes the root cause in source code for situations where a transaction consuming a particular service either fails or is slower than expected. Being a key benefit for Plumbr users, this part of the product was not anyhow related to the content of this post; so feel free to forget about this feature.
As a full disclosure: the post is summarizing of my recently graduated Master thesis in the Comp. Sci. institute in the Tartu University. Besides chasing my degree in the university, I am also a member of the engineering team in Plumbr, so it was somewhat natural that I linked my work and research to benefit on both fronts.
The Problem
The problem I tackled was related to matching the transactions to actual services. To understand the issue at hand, lets take a look at an example.
Let us have a web application, being accessed by end users via traditional HTTP GET/POST methods at http://www.example.com. Actual transactions hitting this application might look like the following:
- http://www.example.com/invoices/12345?action=pay
- http://www.example.com/invoices/98765?action=pay
- http://www.example.com/invoices/search?from=01-01-2015
- http://www.example.com/invoices/search?from=01-01-2015&to=31-01-2015
For the human reader it is obvious that the four transactions above are accessing two different services. First two transactions are payment attempts to invoices “12345” and “98765” and the last two are searching invoices within a specific time range.
The problem at hand is now staring right at us. As the identifier of the particular resource or parameters in the URL tend to change, then the naïve approach of just applying string comparison would fail us for anything but the simplest applications.
To be certain about whether or not this is really the case, I did ran the test on the dataset from real production deployments of Plumbr. The test applied the naïve grouping of transactions to services by the application being monitored.
It resulted in clear confirmation of my hypotheses, as 39.5% of the applications ended up with more than 5,000 services detected. In 11.6% of the applications, the number of services exceeded 50,000.
This is confirming our expectations. Nobody in their right mind should ever consider coupling even 500 different functions into a single applications, let alone 5,000 or 50,000.
The Solution
Having confirmed the presence of the problem I now had to make sure that whenever the transaction has any dynamic part in the URL such as parameter or the resource identifier, we would be able to identify the dynamic sections from the URL and group the transactions correctly.
The requirements for the upcoming data analysis can thus be aggregated as:
- Distinguish between “dynamic” and “static” parts in the URL.
- Normalize the URLs by removing the dynamic parts from the URLs.
- Generate service name from the normalized URLs, which would still bear enough semantics for humans to understand what the actual service was.
- Generate regular expressions grouping URLs to services.
Preparing the data
Before describing the actual algorithm used, let us explore one of the challenges needed to be solved prior actual analysis. To start identifying dynamic and static parts from the URL, we needed to tokenize the URL. Tokenized URLs can then be used to compare each part of the URL while identifying dynamic and static parts.
Seems like an easy task at first. The naïve approach at tokenizing at every forward slash and ampersands was apparently not enough as less than half of the applications in the data set formatted the URLs according using just slashes and ampersands. The remaining half of the applications used truly different approaches. To give you an idea, just look at the following examples derived from the real dataset:
- http://www.example.com/invoices.pay.12345
- http://www.example.com/invoices-pay-12345
- http://www.example.com/invoices/pay&id=12345
Apparently despite the popularity of REST standards, URL design is application specific and there is no guarantee that characteristics that apply to one application will be the same for another one.
So I ended up with extracting a set of known delimiters from the data I had access to and running the algorithm selecting the right delimiter for each application. The selection criteria was based upon choosing the delimiter appearing in more than 90% of cases for forthcoming analysis.
Picking the algorithm
Now having URLs tokenized, we needed a way to perform categorization on completely unstructured and unpredictable data. Such categorization would build us the foundation to dynamic/static token detection. Having distilled the task at hand to categorization, the algorithm of choice was rather easy. I implemented a popular text mining and information retrieval algorithm called TF-IDF using MapReduce programming model.
TF-IDF is combination of two statistical techniques, TF – Term Frequency and IDF – Inverse Document Frequency. Main benefit of TF-IDF score is that its value increases with the corresponding number of times a word appears in the document, but is offset by the occurrence of the word in the collection of documents. This helps to confirm the fact that some words in our case URL parts appear more frequently. There are numerous variations for TF and IDF, with a different score calculation techniques. Figures 1 and 2 (courtesy of Wikimedia) illustrates several adaptations for TF and IDF score calculation, respectively.


As far as this blog post is concerned we should treat URLs as text document without any predefined structure. For better illustration let’s analyze a text-mining case for books. Suppose we want to find list of most important words across 10 books, so that when I type certain word I want to select the book where this word seems to be the most “relevant”. For example if I write word “gunslinger” I would like to see The Dark Tower: The Gunslinger by Stephen King.
For this case we want to exclude commonly used words such as: “and”, “or”, “with”, etc. We can accomplish this task by computing Term Frequency using Raw Frequency formula along with Inverse Document Frequency. The only thing that we need is delimiter for words and as far as we already know in the books it is usually space.
If computed score is close to 0, this means that given word is rarely seen among the books, meaning that it can be marked as specific for certain book. On the other hand high score illustrates that selected word is observed across the most of the books. Usually words like: “and”, “or”, “with” have high TF-IDF score.
So we can think about transactions in a single application consuming different URLs the same way. Given the fact that we already have identified the delimiter we can compute TF-IDF score for each part of the URL for any application, handing us score value. Based on this value we can categorize URL part as dynamic or static.
TF-IDF Using MapReduce
Through the years MapReduce programming model justified its efficiency for text mining, information retrieval and various other large data processing tasks. The model was influenced by map and fold functions commonly used almost in any functional programming language. MapReduce programming model is based on key value pairs, where map generates values for a specific key and values for the same keys goes to the same reducer. But before going into MapReduce implementation details, we need to take a look at how map and fold functions look like in functional programming.
Map applies given function to each element of the list and gives modified list as an output.
map f lst: (’a -> ’b) -> (’a list) -> (’b list)
Fold applies given function to one element of the list and the accumulator (initial value of accumulator must be set in advance). After that result is stored in the accumulator and this is repeated for every element in the list.
fold f acc lst: (acc -> ’a -> acc) -> acc -> (’a list) -> acc
Lets take a look simple sum of squres example using map and fold functions. As we already described Map applies given function to every element of the list and gives us modified list. For the task stated above we have list of integers and we want to have each number in power of two. So our map function would look like this:
(map (lambda (x) (* x x)) '(1 2 3 4 5)) → '(1 4 9 16 25)
As for the Fold, since we want to have sum of elements we need to set initial value of accumulator as 0 and we can pass + as a function.
(fold (+) 0 '(1 2 3 4 5)) → 15
Combination of map and fold for sum of squares would look like this:
(define (sum-of-squares v)
(fold (+) 0 (map (lambda (x) (* x x)) v)))
(sum-of-squares '(1 2 3 4 5)) → 55If we think about TF-IDF calculation for URLs, we need to apply given function for each URL and fold calculated results by predefined formulas using MapReduce. In order to calculate Term Frequencies and Inverse Document Frequencies we need to generate data for several intermediate steps such as word count in each URL, total number of words in the collection of URLs and etc.
Therefore calculating everything in a single MapReduce task can be overwhelming with respect to algorithm design and implementation. To address this issue we can split the task into four interdependent MapReduce iterations, this will give us possibility to perform step-by-step analysis on the dataset and during final iteration we will have a possibility to calculate score for each URL part in the dataset.
First MapReduce Iteration
During first MapReduce iteration we need to split each URL into parts and output each URL part separately, where URL identifier and a part itself will be defined as keys. This will give possibility to the reducer to calculate total occurrence of the specific URL part in the dataset.
The implementation would be similar to:
Map:
- Input: (raw URL)
- Function: Split the URL into parts and output each pert.
- Output: (urlPart;urlCollectionId, 1)
Reduce:
- Input: (urlPart;urlCollectionId, [counts])
- Function: Sum all the counts as n
- Output: (urlPart;urlCollectionId, n)
Second MapReduce Iteration
For the second iteration input for the map function is the output of the first iteration. The purpose of the map function is to modify key values of the first iteration so that we can collect number of times each URL part appeared in a given collection. This will give possibility to the reducer to calculate number of total terms in each collection.
The implementation would be roughly as:
Map:
- Input – (urlPart;urlCollectionId, n)
- Function – We need to change the key to be only collection identifier and move the URL part name into the value field.
- Output – (urlCollectionId, urlPart;n)
Reduce:
- Input – (urlCollectionId, [urlPart;n])
- Function – We need to sum all the n’s in the collection of URLs as N and output every URL part again.
- Output – (urlPart;urlCollectionId, n;N)
Third MapReduce Iteration
The goal of the third iteration is to calculate URL part frequency in the collections. To do so we need to send to the reducer calculated data for the concrete URL part, therefore map function should move urlCollectionId to the value field and the key should only contain urlPart value. After such modification reducer can calculate how many times urlPart appeared across different collections.
The implementation would be similar to:
Map:
- Input – (urlPart;urlCollectionId, n;N)
- Function – Move urlCollectionId to value field
- Output – (urlPart, urlCollectionId;n;N;1)
Reduce:
- Input – (urlPart, [urlCollectionId;n;N;1])
- Function – Calculate total number of urlParts in a collection as m. Move urlCollectionId back to the key field
- Output – (urlPart;urlCollectionId, n;N;m)
Fourth MapReduce iteration
At this point we will have all required data to calculate Term Frequency and Invert Document Frequency for each URL part, such as:
- n – How many times given URL part appeared in the collection
- N – Number of occurrences of the given URL part across different URL collections.
- m – Total number of URL parts in a collection.
For the TF we will use following formula:
![]()
Where f represents number of times given word appeared in a document. Now we can calculate Inverse Document Frequency using following formula:
![]()
Where N is total number of documents and nt – number of terms in a document. We do not need reduce function for this final stage, since TF-IDF calculation done for each URL part in a given collection.
The Implementation should look something like this:
Map:
- Input – (urlPart;urlCollectionId, n;N;m)
- Function – calculate TF-IDF based on n;N;m and D. Where D is the total number of url collections.
![]()
- Output – (urlPart;urlCollectionId, score)
Results
To give you an idea whether or not the approach picked really worked, let us look at two examples with completely different URL design. Account A used “.” as the delimiter and account B – “/”. Number of services detected by the naive approach was bad on both cases: 105,000 services in account A and 275,000 services in account B.
The solution was able to successfully detect delimiter for each of the account and calculate TF-IDF score for each of the URL part. Identified dynamic parts were replaced with static content, similar to the example illustrated below:
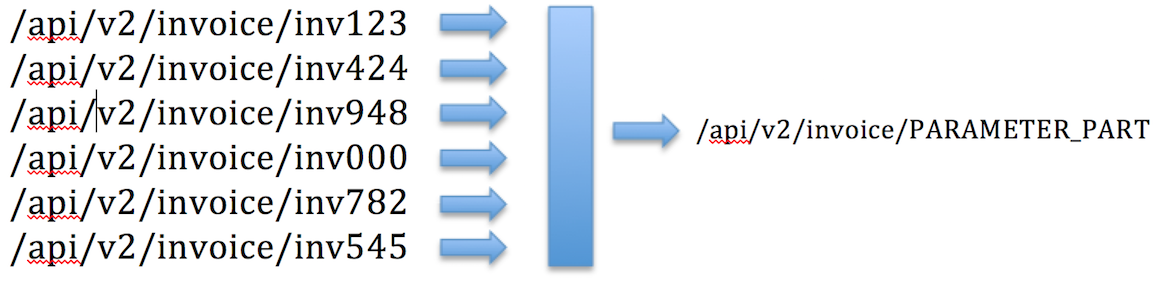
Categorization was improved by more than 99% for both accounts, resulting in just 320 services for account A and 195 services for account B.
The quality of the results was also confirmed by the actual application owners, so on both cases the approach used played out really well.
Final remarks
To be fair, the current Plumbr is not basing its current service detection in plain string comparison as described in the intro sections of this post. Instead, it applies many different techniques to mitigate the problem. These include framework-specific (Spring MVC, Struts, JSF, etc) service detection and pattern matching for simple repeating tokens.
However, the results I received with the algorithm described justified the actual deployment of the algorithm. Already in July I will start embedding the approach to our actual product deployment.
| Reference: | Applying TF-IDF algorithm in practice from our JCG partner Levani Kokhreidze at the Plumbr Blog blog. |

what and what will mathematics need in java?