MongoDB aggregation framework is designed for grouping documents and transforming them into an aggregated result. The aggregation query consists in defining several stages that will be executed in a pipeline. If you are interested in more in-depth details about the framework, then
mongodb docs are a good point to start.
The point of this post is to write a web application for querying mongodb in order to get aggregated results from the database. We will do it in a very easy way thanks to Spring Boot and Spring Data. Actually it is really fast to implement the application, since Spring Boot will take care of all the necessary setup and Spring Data will help us configure the repositories.
The source code can be found on my Github repository.
1 The application
Before going through the code let’s see what we want to do with our application.
Our domain is a collection of products we have distributed across several warehouses:
@Document
public class Product {
@Id
private final String id;
private final String warehouse;
private final float price;
public Product(String id, String warehouse, float price) {
this.id = id;
this.warehouse = warehouse;
this.price = price;
}
public String getId() {
return id;
}
public String getWarehouse() {
return warehouse;
}
public float getPrice() {
return price;
}
}
Our target is to collect all the products within a price range, grouped by warehouse and collecting the total revenue and the average price of each grouping.
In this example, our warehouses are storing the following products:
new Product("NW1", "Norwich", 3.0f);
new Product("LN1", "London", 25.0f);
new Product("LN2", "London", 35.0f);
new Product("LV1", "Liverpool", 15.2f);
new Product("MN1", "Manchester", 45.5f);
new Product("LV2", "Liverpool", 23.9f);
new Product("LN3", "London", 55.5f);
new Product("LD1", "Leeds", 87.0f);
The application will query for products with a price between 5.0 and 70.0. The required aggregation pipeline steps will be as follows:
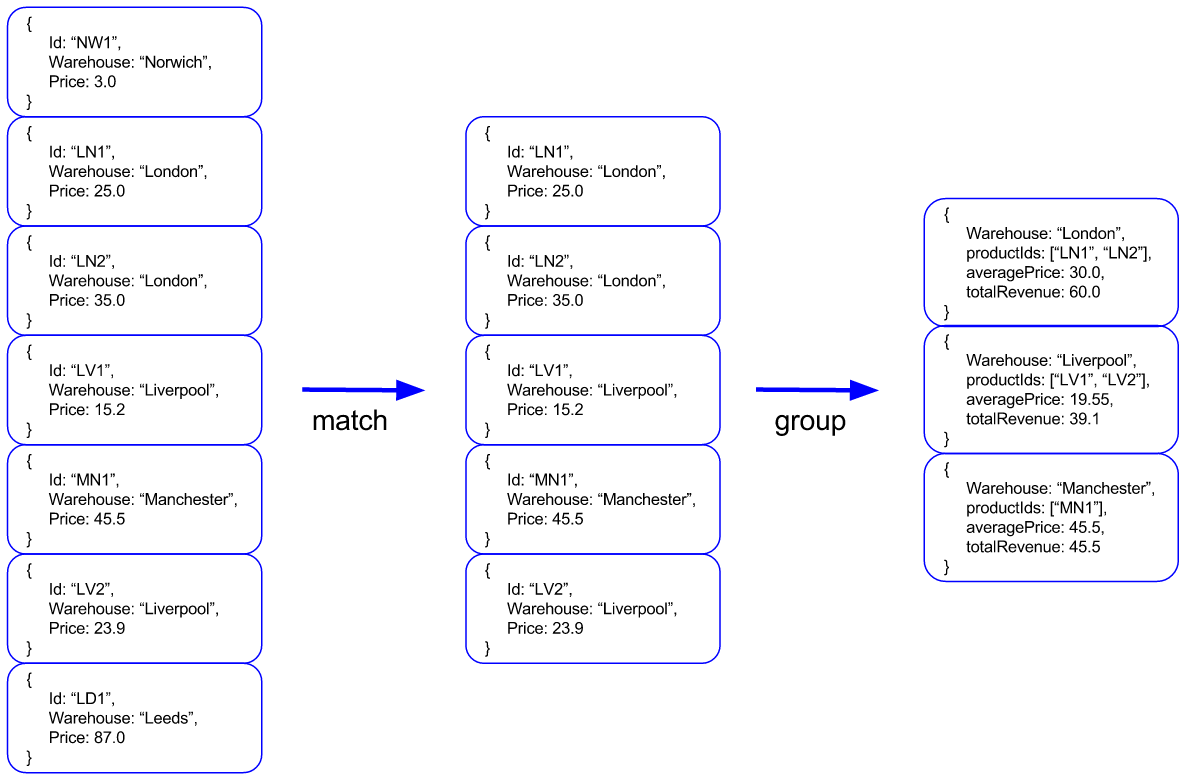
We will end up with aggregated results grouped by warehouse. Each group will contain the list of products of each warehouse, the average product price and the total revenue, which actually is the sum of the prices.
2 Maven dependencies
As you can see, we have a short pom.xml with Spring Boot dependencies:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.3.RELEASE</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
By defining spring-boot-starter-parent as our parent pom, we set the default settings of Spring Boot. Mainly it sets the versions of a bunch of libraries it may use, like Spring or Apache Commons. For example, Spring Boot 1.3.3, which is the one we are using, sets 4.2.5.RELEASE as the Spring framework version. Like stated in previous posts, it is not adding libraries to our application, it only sets versions.
Once the parent is defined, we only need to add three dependencies:
- spring-boot-starter-web: Mainly includes Spring MVC libraries and an embedded Tomcat server.
- spring-boot-starter-test: Includes testing libraries like JUnit, Mockito, Hamcrest and Spring Test.
- spring-boot-starter-data-mongodb: This dependency includes the MongoDB Java driver, and the Spring Data Mongo libraries.
3 Application setup
Thanks to Spring Boot, the application setup is as simple as the dependencies setup:
@SpringBootApplication
public class AggregationApplication {
public static void main(String[] args) {
SpringApplication.run(AggregationApplication.class, args);
}
}
When running the main method, we will start our web application listening to the 8080 port.
4 The repository
Now that we have the application properly configured, we implement the repository. This isn’t difficult neither since Spring Data takes care of all the wiring.
@Repository
public interface ProductRepository extends MongoRepository<Product, String> {
}
The following test proves that our application is correctly set up.
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = AggregationApplication.class)
@WebAppConfiguration
public class AggregationApplicationTests {
@Autowired
private ProductRepository productRepository;
@Before
public void setUp() {
productRepository.deleteAll();
}
@Test
public void contextLoads() {
}
@Test
public void findById() {
Product product = new Product("LN1", "London", 5.0f);
productRepository.save(product);
Product foundProduct = productRepository.findOne("LN1");
assertNotNull(foundProduct);
}
}
We didn’t implement save and findOne methods. They are already defined since our repository is extending MongoRepository.
5 The aggregation query
Finally, we set up the application and explained all the steps. Now we can focus on the aggregation query.
Since our aggregation query is not a basic query, we need to implement a custom repository. The steps are:
Create the custom repository with the method we need:
public interface ProductRepositoryCustom {
List<WarehouseSummary> aggregate(float minPrice, float maxPrice);
}
Modify the first repository in order to also extend our custom repository:
@Repository
public interface ProductRepository extends MongoRepository<Product, String>, ProductRepositoryCustom {
}
Create an implementation to write the aggregation query:
public class ProductRepositoryImpl implements ProductRepositoryCustom {
private final MongoTemplate mongoTemplate;
@Autowired
public ProductRepositoryImpl(MongoTemplate mongoTemplate) {
this.mongoTemplate = mongoTemplate;
}
@Override
public List<WarehouseSummary> aggregate(float minPrice, float maxPrice) {
...
}
}
Now we are going to implement the stages of the mongodb pipeline as explained in the beginning of the post.
Our first operation is the match operation. We will filter out all product documents that are beyond our price range:
private MatchOperation getMatchOperation(float minPrice, float maxPrice) {
Criteria priceCriteria = where("price").gt(minPrice).andOperator(where("price").lt(maxPrice));
return match(priceCriteria);
}
The next stage of the pipeline is the group operation. In addition to grouping documents by warehouse, in this stage we are also doing the following calculations:
- last: Returns the warehouse of the last document in the group.
- addToSet: Collects all the unique product Ids of all the grouped documents, resulting in an array.
- avg: Calculates the average of all prices in the group.
- sum: Sums all prices in the group.
private GroupOperation getGroupOperation() {
return group("warehouse")
.last("warehouse").as("warehouse")
.addToSet("id").as("productIds")
.avg("price").as("averagePrice")
.sum("price").as("totalRevenue");
}
The last stage of the pipeline is the project operation. Here we specify the resulting fields of the aggregation:
private ProjectionOperation getProjectOperation() {
return project("productIds", "averagePrice", "totalRevenue")
.and("warehouse").previousOperation();
}
The query is built as follows:
public List<WarehouseSummary> aggregate(float minPrice, float maxPrice) {
MatchOperation matchOperation = getMatchOperation(minPrice, maxPrice);
GroupOperation groupOperation = getGroupOperation();
ProjectionOperation projectionOperation = getProjectOperation();
return mongoTemplate.aggregate(Aggregation.newAggregation(
matchOperation,
groupOperation,
projectionOperation
), Product.class, WarehouseSummary.class).getMappedResults();
}
In the aggregate method, we indicate the input class, which is our Product document. The next argument is the output class, which is a DTO to store the resulting aggregation:
public class WarehouseSummary {
private String warehouse;
private List<String> productIds;
private float averagePrice;
private float totalRevenue;
We should end the post with a test proving that results are what we expect:
@Test
public void aggregateProducts() {
saveProducts();
List<WarehouseSummary> warehouseSummaries = productRepository.aggregate(5.0f, 70.0f);
assertEquals(3, warehouseSummaries.size());
WarehouseSummary liverpoolProducts = getLiverpoolProducts(warehouseSummaries);
assertEquals(39.1, liverpoolProducts.getTotalRevenue(), 0.01);
assertEquals(19.55, liverpoolProducts.getAveragePrice(), 0.01);
}
private void saveProducts() {
productRepository.save(new Product("NW1", "Norwich", 3.0f));
productRepository.save(new Product("LN1", "London", 25.0f));
productRepository.save(new Product("LN2", "London", 35.0f));
productRepository.save(new Product("LV1", "Liverpool", 15.2f));
productRepository.save(new Product("MN1", "Manchester", 45.5f));
productRepository.save(new Product("LV2", "Liverpool", 23.9f));
productRepository.save(new Product("LN3", "London", 55.5f));
productRepository.save(new Product("LD1", "Leeds", 87.0f));
}
private WarehouseSummary getLiverpoolProducts(List<WarehouseSummary> warehouseSummaries) {
return warehouseSummaries.stream().filter(product -> "Liverpool".equals(product.getWarehouse())).findAny().get();
}
6 Conclusion
Spring Data has a good integration with MongoDB aggregation framework. Adding Spring Boot to configure the application let’s us focus on building the query. For the building process, Aggregation class has several static methods that help us implement the different pipeline stages.
I’m publishing my new posts on Google plus and Twitter. Follow me if you want to be updated with new content.
| Reference: | Data aggregation with Spring Data MongoDB and Spring Boot from our JCG partner Xavier Padro at the Xavier Padró’s Blog blog. |

Why the need for the final projection? It looks like the group creates the output required? Thanks for all info
Hey from where this match method of getMatchOperation() return type is comming from dude.. plz explani me