In a previous post I had mentioned that the trio of Logstash, Kibana and Elasticsearch (ELK stack) is one of the most popular open source solutions for not only logs management but also data analysis. In this post I will demonstrate how ELK can be used to effectively and efficiently perform big data analysis. As a reference let’s take some huge mailbox data. Mail archives are arguably one of the most interesting kind of social web data. It is omnipresent and each message throws light on the communication which people are having. As a CXO of an organization you may want to analyze corporate mails for trends and patterns.
As a reference, I will take the well-known Enron corpus as it has a huge collection of mails and there is no risk of any legal or privacy concerns. This data will be standardized into Unix mailbox (mbox) format. From the mbox format it will be again transformed into a single json file.
Getting the Enron corpus data
The full Enron dataset in a raw form is available for download in various formats. I will start with the original raw form of the data set that is essentially a set of folders that organizes a collection of mailboxes by person and folder. The following snippet would illustrate the basic structure of the corpus after you have downloaded and unarchived it. Go ahead and play with it a little bit so that you become familiar with it.
C:\> cd enron_mail_20110402\maildir # Go into the mail directory C:\enron_mail_20110402\maildir>dir # Show folders/files in the current directory</pre> allen-p crandell-s gay-r horton-s lokey-t nemec-g rogers-b slinger-r tycholiz-b arnold-j cuilla-m geaccone-t <pre> ...directory listing truncated...</pre> neal-s rodrique-r skilling-j townsend-j <pre>C:\enron_mail_20110402\maildir> cd allen-p/ # Go into the allen-p folder C:\enron_mail_20110402\maildir\allen-p> dir # Show files in the current directory</pre> _sent_mail contacts discussion_threads notes_inbox sent_items all_documents deleted_items inbox <pre>sent straw C:\enron_mail_20110402\maildir\allen-p> cd inbox/ # Go into the inbox for allen-p C:\enron_mail_20110402\maildir\allen-p\inbox> dir # Show the files in the inbox for allen-p</pre> <ol> <li>11. 13. 15. 17. 19. 20. 22. 24. 26. 28. 3. 31. 33. 35. 37. 39. 40.</li> <li>44. 5. 62. 64. 66. 68. 7. 71. 73. 75. 79. 83. 85. 87. 10. 12. 14.</li> <li>18. 2. 21. 23. 25. 27. 29. 30. 32. 34. 36. 38. 4. 41. 43. 45. 6.</li> </ol> <pre> 63. 65. 67. 69. 70. 72. 74. 78. 8. 84. 86. 9. C:\enron_mail_20110402\maildir\allen-p\inbox> cat 1. # Show contents of the file named "1." Message-ID: <16159836.1075855377439.JavaMail.evans@thyme> Date: Fri, 7 Dec 2001 10:06:42 -0800 (PST) From: heather.dunton@enron.com To: k..allen@enron.com Subject: RE: West Position Mime-Version: 1.0 Content-Type: text/plain; charset=us-ascii Content-Transfer-Encoding: 7bit X-From: Dunton, Heather </O=ENRON/OU=NA/CN=RECIPIENTS/CN=HDUNTON> X-To: Allen, Phillip K. </O=ENRON/OU=NA/CN=RECIPIENTS/CN=Pallen> X-cc: X-bcc: X-Folder: \Phillip_Allen_Jan2002_1\Allen, Phillip K.\Inbox X-Origin: Allen-P X-FileName: pallen (Non-Privileged).pst Please let me know if you still need Curve Shift. Thanks,
Now the next step is to convert the mail data into Unix mbox format. An mbox is in fact just a large text file of concatenated mail messages that are easily accessible by text-based tools. I have used python script to convert it into mbox format. Thereafter, this mbox file would be converted into ELK compatible JSON format. The json file can be found here. A snippet of json file can be found below:
{"index":{"_index":"enron","_type":"inbox"}}
[{"X-cc": "", "From": "r-3-728402-1640008-2-359-us2-982d4478@xmr3.com", "X-Folder": "\\jskillin\\Inbox", "Content-Transfer-Encoding": "7bit", "X-bcc": "", "X-Origin": "SKILLING-J", "To": ["jeff.skilling@enron.com"], "parts": [{"content": "\n[IMAGE]\n[IMAGE]\nJoin us June 26th for an on-line seminar featuring Steven J. Kafka, Senior Analyst at Forrester Research, as he discusses how technology can create more effective collaboration in today's virtualized enterprise. Also featuring Mike Hager, VP, OppenheimerFunds, offering insights into implementing these technologies through real-world experiences. Brian Anderson, CMO, Access360 will share techniques and provide tips on how to successfully deploy resources across the virtualized enterprise. \nDon't miss this important event. Register now at http://www.access360.com/webinar/ . For a sneak preview, check out our one-minute animation that illustrates the challenges of provisioning access rights across the \"virtualized\" enterprise.\nAbout Access360\nAccess360 provides the software and services needed for deploying policy-based provisioning solutions. Our solutions help companies automate the process of provisioning employees, contractors and business partners with access rights to the applications they need. With Access360, companies can react instantaneously to changing business environments and relationships and operate with confidence, whether in a closed enterprise environment or across a virtual or extended enterprise.\n \nAccess360 \n\nIf you would prefer not to receive further messages from this sender:\n1. Click on the Reply button.\n2. Replace the Subject field with the word REMOVE.\n3. Click the Send button.\nYou will receive one additional e-mail message confirming your removal.\n\n", "contentType": "text/plain"}], "X-FileName": "jskillin.pst", "Mime-Version": "1.0", "X-From": "Access360 <R-3-728402-1640008-2-359-US2-982D4478@xmr3.com>@ENRON", "Date": {"$date": 991326029000}, "X-To": "Skilling, Jeff </o=ENRON/ou=NA/cn=Recipients/cn=JSKILLIN>", "Message-ID": "<14649554.1075840159275.JavaMail.evans@thyme>", "Content-Type": "text/plain; charset=us-ascii", "Subject": "Forrester Research on Best Practices for the \"Virtualized\" Enterprise"}
When you have huge amount of data to be pushed into Elasticsearch then it is better to do bulk import by specifying the data file. Each mail message is in a line of its own associated with an entry specifying the index (enron) and document (inbox). There is no need to specify the id as Elasticsearch would automatically specify the id.
Data in Elasticsearch can be broadly divided into two types – exact values and full text. Exact values are exactly what they sound like. Examples are a date or a user ID, but can also include exact strings such as a username or an email address. For e.g., the exact value Foo is not the same as the exact value foo. The exact value 2014 is not the same as the exact value 2014-09-15. On the other hand Full text refers to textual data – usually written in some human language – like the text of a tweet or the body of an email. For the purpose of this exercise, it is better to treat Email addresses (To, CC, BCC) as exact values. Hence, we first need to specify the mapping, which can be done in the following manner.
curl -XPUT “localhost:9200/enron” -d "{
"settings":
{
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings":
{
"inbox":
{
"_all":
{
"enabled": false
},
"properties":
{
"To":
{
"type": "string",
"index": "not_analyzed"
},
"From":
{
"type": "string",
"index": "not_analyzed"
},
"CC":
{
"type": "string",
"index": "not_analyzed"
},
"BCC":
{
"type": "string",
"index": "not_analyzed"
}
}
}
}
}"
You can verify that the mapping has indeed been set.
curl -XGET "http://localhost:9200/_mapping?pretty"
{
"enron" :
{
"mappings" :
{
"inbox" :
{
"_all" :
{
"enabled" : false
},
"properties" :
{
"BCC" :
{
"type" : "string",
"index" : "not_analyzed"
},
"CC" :
{
"type" : "string",
"index" : "not_analyzed"
},
"From" :
{
"type" : "string",
"index" : "not_analyzed"
},
"To" :
{
"type" : "string",
"index" : "not_analyzed"
}
}
}
}
}
}
Now let’s load all the mailbox data by using the json file, in the following manner:
curl -XPOST "http://localhost:9200/_bulk" --data-binary @enron.json
We can check if all the data has been uploaded successfully.
curl "localhost:9200/enron/inbox/_count?pretty"
{
"count" : 41299,
"_shards" :
{
"total" : 5,
"successful" : 5,
"failed" : 0
}
}
You can see that 41299 records each corresponding to a different message, have been uploaded. Now lets start the fun part by doing some analysis on this data. Kibana provides awesome analytic capability and associated charts. Lets try to see how many messages are circulated on a weekly basis.
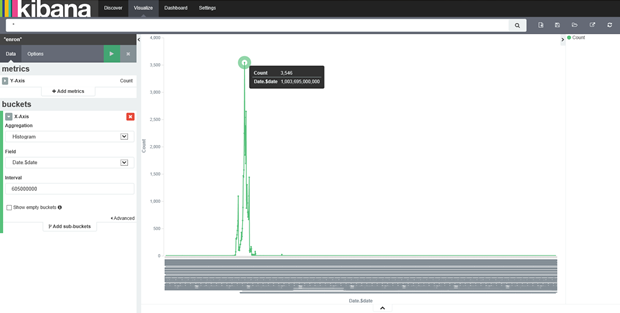
The above histogram shows the message spread on a weekly basis. The date value is in terms of milliseconds past the epoch. You can see that one particular week has a peak of 3546 messages. Something interesting must be happening that week. Now lets see who are the top recipients of messages
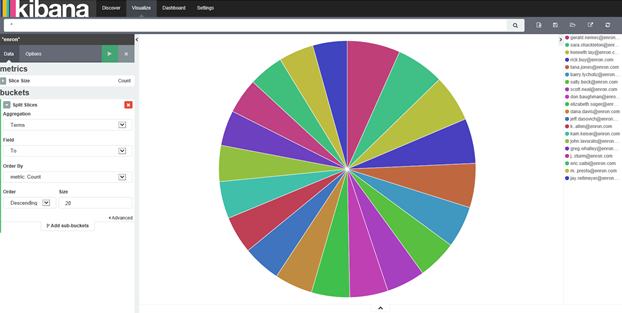
You can see that Gerald, Sara, Kenneth are some of the top recipients of messages. How about checking out the top senders?
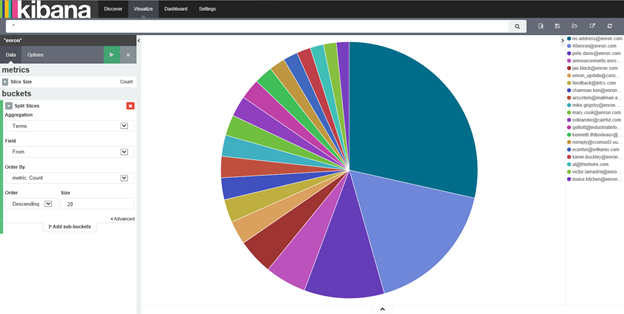
You can see that Pete, Jae and Ken are the top senders of messages. In case you are wondering what exactly Enron employees used to discuss, let’s check out top keywords from message subjects.
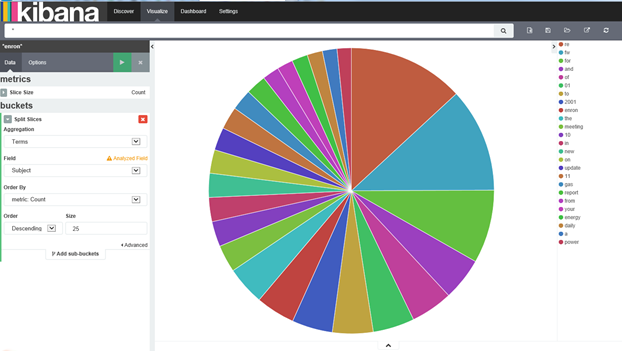
It seems most interesting discussions centered on enron, gas, energy, power. There can be a lot more interesting analysis done with the Enron mail data. I would recommend you try the following:
- Counting sent/received messages for particular email addresses
- What was the maximum number of recipients on a message?
- Which two people exchanged the most messages amongst one another?
- How many messages were person-to-person messages?
| Reference: | Mining Mailboxes with Elasticsearch and Kibana from our JCG partner Gurpreet Sachdeva at the gssachdeva blog. |

Expeciaally for email miling it might be veeeery interesting to join sender/receiver, join on domain names, join on keywords. Kibi (kibana + relational joins) http://siren.solutions/kibi can be extramely useful for this. (it also has graph visualization e.g. sender receiver)
Agreed, there can be lot more interesting combinations of sender/receiver.