This article is part of our Academy Course titled Apache Lucene Fundamentals.
In this course, you will get an introduction to Lucene. You will see why a library like this is important and then learn how searching works in Lucene. Moreover, you will learn how to integrate Lucene Search into your own applications in order to provide robust searching capabilities. Check it out here!
Table Of Contents
1. Introduction
Analysis, in Lucene, is the process of converting field text into its most fundamental indexed representation, terms. In general, the tokens are referred to as words (we are discussing this topic in reference to the English language only) to the analyzers. However, for special analyzers the token can be with more than one words, which includes spaces also. These terms are used to determine what documents match a query during searching. For example, if you indexed this sentence in a field the terms might start with for and example, and so on, as separate terms in sequence. An analyzer is an encapsulation of the analysis process. An analyzer tokenizes text by performing any number of operations on it, which could include extracting words, discarding punctuation, removing accents from characters, lowercasing (also called normalizing), removing common words, reducing words to a root form (stemming), or changing words into the basic form (lemmatization). This process is also called tokenization, and the chunks of text pulled from a stream of text are called tokens. Tokens, combined with their associated field name, are terms.
2. Using Analyzers
Lucene’s primary goal is to facilitate information retrieval. The emphasis on retrieval is important. You want to throw gobs of text at Lucene and have them be richly searchable by the individual words within that text. In order for Lucene to know what “words” are, it analyzes the text during indexing, extracting it to terms. These terms are the primitive building blocks for searching.
Choosing the right analyzer is a crucial development decision with Lucene, and one size definitely doesn’t fit all. Language is one factor, because each has its own unique features. Another factor to consider is the domain of the text being analyzed; different industries have different terminology, acronyms, and abbreviations that may deserve attention. No single analyzer will suffice for all situations. It’s possible that none of the built-in analysis options are adequate for our needs, and we’ll have to invest in creating a custom analysis solution; fortunately, Lucene‘s building blocks make this quite easy.
In general Lucene Analyzers are designed using the following steps:
Actual Text –> Basic Token Preparation –> lower case filtering –> stop word filtering (negation of not so useful words, which comprise in the 40-50% of words in a content) –> Filtering by Custom Logic –> Final Token preparation for indexing in lucene, which will be referenced in the searching of lucene.
Different analyzers use different tokenizers and on the basis of that, the output token streams – sequences of group of text will be different.
Stemmers are used to get the root of a word in question. For example, for the words running, ran, run etc. the root word will be run. This feature is used in analyzers to make the search scope higher in the content by the search api. If the root word is referred in the index then may be for the exact word, we can have more than one option in the index for searching and the probability of phrase matching may be higher here. So this concept, referred to as stemmers, is often used in analyser design.
Stop words are the frequent, less useful words in written language. For English these words are “a”, “the”, “I” etc.
In different analyzers, the token streams are cleaned from Stop-words to make the index more useful for search results.
2.1. Working process of Lucene Analyzer
The analysis process has three parts. To help illustrate the process, we are going to use the following raw text as an example. (Processing an HTML or PDF document to obtain the title, main text, and other fields to be analyzed is called parsing and is beyond the scope of analysis. Let’s assume a parser has already extracted this text out of a larger document.)
<h1>Building a <em>top-notch</em> search engine</h1>
First, character filters pre-process the raw text to be analyzed. For example, the HTML Strip character filter removes HTML. We’re now left with this text:
Building a top-notch search engine
Next, a tokenizer breaks up the pre-processed text into tokens. Tokens are usually words, but different tokenizers handle corner cases, such as “top-notch”, differently. Some tokenizers, such as the Standard tokenizer, consider dashes to be word boundaries, so “top-notch” would be two tokens (“top” and “notch”). Other tokenizers such as the Whitespace tokenizer only considers whitespace to be word boundaries, so “top-notch” would be a single token. There are also some unusual tokenizers like the NGram tokenizer that generates tokens that are partial words.
Assuming a dash is considered a word boundary, we now have:
[Building] [a] [top] [notch] [search] [engine]
Finally, token filters perform additional processing on tokens, such as removing suffixes (called stemming) and converting characters to lower case. The final sequence of tokens might end up looking like this:
[build] [a] [top] [notch] [search] [engine]
The combination of a tokenizer and zero or more filters makes up an analyzer. The Standard analyzer, which consists of a Standard tokenizer and the Standard, Lowercase, and Stop token filters, is used by default.
Analyzers can do more complex manipulations to achieve better results. For example, an analyzer might use a token filter to spell check words or introduce synonyms so that searching for “saerch” or “find” will both return the document that contained “Searching”. There are also different implementations of similar features to choose from.
In addition to choosing between the included analyzers, we can create our own custom analyzer by chaining together an existing tokenizer and zero or more filters. The Standard analyzer doesn’t do stemming, so you might want to create a custom analyzer that includes a stemming token filter.
With so many possibilities, we can test out different combinations and see what works best for our situation.
3. Types of Analyzers
In Lucene, some of different analyzers are:
a. Whitespace analyzer
The Whitespace analyzer processes text into tokens based on whitespaces. All characters between whitespaces are indexed. Here, stop words are not used for analyzing and the letter cases are not changed. Whitespace analyzer is built using a Whitespace Tokenizer (a tokenizer of type whitespace that divides text at whitespace).
b. SimpleAnalyser
SimpleAnalyser uses letter tokenizer and lower case filtering to extract tokens from the contents and put it in lucene indexing. Simple analyzer is built using a Lower Case Tokenizer. A lower case tokenizer performs the function of Letter Tokenizer and Lower Case Token Filter together. It divides text at non-letters and converts them to lower case. While it is functionally equivalent to the combination of Letter Tokenizer and Lower Case Token Filter, there is a performance advantage to doing the two tasks at once, hence this (redundant) implementation.
c. StopAnalyzer
StopAnalyser removes common English words that are not so useful for indexing. These are accomplished by providing the analyzer a list of STOP_WORDS lists.
Stop analyzer is built using lower case tokenizer with Stop token filter (A token filter of type stop that removes stop words from token streams)
The following are settings that can be set for a stop analyzer type:
- stopwords -> A list of stopwords to initialize the stop filter with. Defaults to the english stop words.
- stopwords_path -> A path (either relative to config location, or absolute) to a stopwords file configuration.
d. StandardAnalyzer
StandardAnalyser is a general purpose analyser. It generally converts tokens to lowercase, taking help of standard stop words to analyze the texts and is also governed by other rules. StandardAnalyzer is built using the Standard Tokenizer with the Standard Token Filter (a token filter of type standard that normalizes tokens extracted with the Standard Tokenizer), Lower Case Token Filter and Stop Token Filter.
e. ClassicAnalyzer
An Analyzer that filters ClassicTokenizer with ClassicFilter, LowerCaseFilter and StopFilter, using a list of English stop words.
f. UAX29URLEmailAnalyzer
An Analyzer that filters UAX29URLEmailTokenizer with StandardFilter, LowerCaseFilter and StopFilter, using a list of English stop words.
g. Keyword Analyzer
An analyzer of type keyword that “tokenizes” an entire stream as a single token. This is useful for data like zip codes, ids and so on. Note, when using mapping definitions, it might make more sense to simply mark the field as not_analyzed.
h. Snowball Analyzer
An analyzer of type snowball that uses the standard tokenizer, with standard filter, lowercase filter, stop filter, and snowball filter.
The Snowball Analyzer is a stemming analyzer from Lucene that is originally based on the snowball project from snowball.tartarus.org.
Sample usage:
{
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"type" : "snowball",
"language" : "English"
}
}
}
}
}
i. Pattern Analyzer
An analyzer of type pattern that can flexibly separate text into terms via a regular expression. Accepts the following settings:
Example of pattern analyzer:
whitespace tokenizer:
curl -XPUT 'localhost:9200/test' -d '
{
"settings":{
"analysis": {
"analyzer": {
"whitespace":{
"type": "pattern",
"pattern":"\\\\\\\\s+"
}
}
}
}
}
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=whitespace' -d 'foo,bar baz'
# "foo,bar", "baz"
non-word character tokenizer:
curl -XPUT 'localhost:9200/test' -d '
{
"settings":{
"analysis": {
"analyzer": {
"nonword":{
"type": "pattern",
"pattern":"[^\\\\\\\\w]+"
}
}
}
}
}
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=nonword' -d 'foo,bar baz'</strong> # "foo,bar baz" becomes "foo", "bar", "baz"
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=nonword' -d 'type_1-type_4'</strong> # "type_1","type_4"
camelcase tokenizer:
curl -XPUT 'localhost:9200/test?pretty=1' -d '
{
"settings":{
"analysis": {
"analyzer": {
"camel":{
"type": "pattern",
"pattern":"([^\\\\\\\\p{L}\\\\\\\\d]+)|(?<=\\\\\\\\D)(?=\\\\\\\\d)|(?<=\\\\\\\\d)(?=\\\\\\\\D)|(?<=[\\\\\\\\p{L}&&[^\\\\\\\\p{Lu}]])(?=\\\\\\\\p{Lu})|(?<=\\\\\\\\p{Lu})(?=\\\\\\\\p{Lu}[\\\\\\\\p{L}&&[^\\\\\\\\p{Lu}]])"
}
}
}
}
}
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=camel' -d '
MooseX::FTPClass2_beta
'
# "moose","x","ftp","class","2","beta"
The regex above is easier to understand as:
| ([^\\p{L}\\d]+) | # swallow non letters and numbers, |
| | (?<=\\D)(?=\\d) | # or non-number followed by number, |
| | (?<=\\d)(?=\\D) | # or number followed by non-number, |
| | (?<=[ \\p{L} && [^\\p{Lu}]]) | # or lower case |
| (?=\\p{Lu}) | # followed by upper case, |
| | (?<=\\p{Lu}) | # or upper case |
| (?=\\p{Lu} | # followed by upper case |
| [\\p{L}&&[^\\p{Lu}]] | # then lower case |
Table 1
j. Custom Analyzer
An analyzer of type custom that allows to combine a Tokenizer with zero or more Token Filters, and zero or more Char Filters. The custom analyzer accepts a logical/registered name of the tokenizer to use, and a list of logical/registered names of token filters.
Here is example of a custom analyzer:
index :
analysis :
analyzer :
myAnalyzer2 :
type : custom
tokenizer : myTokenizer1
filter : [myTokenFilter1, myTokenFilter2]
char_filter : [my_html]
tokenizer :
myTokenizer1 :
type : standard
max_token_length : 900
filter :
myTokenFilter1 :
type : stop
stopwords : [stop1, stop2, stop3, stop4]
myTokenFilter2 :
type : length
min : 0
max : 2000
char_filter :
my_html :
type : html_strip
escaped_tags : [xxx, yyy]
read_ahead : 1024
The language parameter can have the same values as the snowball filter and defaults to English. Note that not all the language analyzers have a default set of stopwords provided.
The stopwords parameter can be used to provide stopwords for the languages that have no defaults, or to simply replace the default set with your custom list. Check Stop Analyzer for more details. A default set of stopwords for many of these languages is available from for instance here and here.
A sample configuration (in YAML format) specifying Swedish with stopwords:
index :
analysis :
analyzer :
my_analyzer:
type: snowball
language: Swedish
stopwords: "och,det,att,i,en,jag,hon,som,han,på,den,med,var,sig,för,så,till,är,men,ett,om,hade,de,av,icke,mig,du,henne,då,sin,nu,har,inte,hans,honom,skulle,hennes,där,min,man,ej,vid,kunde,något,från,ut,när,efter,upp,vi,dem,vara,vad,över,än,dig,kan,sina,här,ha,mot,alla,under,någon,allt,mycket,sedan,ju,denna,själv,detta,åt,utan,varit,hur,ingen,mitt,ni,bli,blev,oss,din,dessa,några,deras,blir,mina,samma,vilken,er,sådan,vår,blivit,dess,inom,mellan,sådant,varför,varje,vilka,ditt,vem,vilket,sitta,sådana,vart,dina,vars,vårt,våra,ert,era,vilkas"
Here is an example of a custom string analyzer, which is built by extending Lucene’s abstract Analyzer class. The following listing shows the SampleStringAnalyzer, which implements the tokenStream(String,Reader) method. The SampleStringAnalyzer defines a set of stop words that can be discarded in the process of indexing, using a StopFilter provided by Lucene. The tokenStream method checks the field that is being indexed. If the field is a comment, it first tokenizes and lower-cases input using the LowerCaseTokenizer, eliminates stop words of English (a limited set of English stop words) using the StopFilter, and uses the PorterStemFilter to remove common morphological and inflectional endings. If the content to be indexed is not a comment, the analyzer tokenizes and lower-cases input using LowerCaseTokenizer and eliminates the Java keywords using the StopFilter.
public class SampleStringAnalyzer extends Analyzer {
private Set specialStopSet;
private Set englishStopSet;
private static final String[] SPECIALWORD_STOP_WORDS = {
"abstract","implements","extends","null""new",
"switch","case", "default" ,"synchronized" ,
"do", "if", "else", "break","continue","this",
"assert" ,"for", "transient",
"final", "static","catch","try",
"throws","throw","class", "finally","return",
"const" , "native", "super","while", "import",
"package" ,"true", "false" };
private static final String[] ENGLISH_STOP_WORDS ={
"a", "an", "and", "are","as","at","be" "but",
"by", "for", "if", "in", "into", "is", "it",
"no", "not", "of", "on", "or", "s", "such",
"that", "the", "their", "then", "there","these",
"they", "this", "to", "was", "will", "with" };
public SourceCodeAnalyzer(){
super();
specialStopSet = StopFilter.makeStopSet(SPECIALWORD_STOP_WORDS);
englishStopSet = StopFilter.makeStopSet(ENGLISH_STOP_WORDS);
}
public TokenStream tokenStream(String fieldName,
Reader reader) {
if (fieldName.equals("comment"))
return new PorterStemFilter(
new StopFilter(
new LowerCaseTokenizer(reader),englishStopSet));
else
return new StopFilter(
new LowerCaseTokenizer(reader),specialStopSet);
}
}
}
What’s inside an Analyzer?
Analyzers need to return a TokenStream
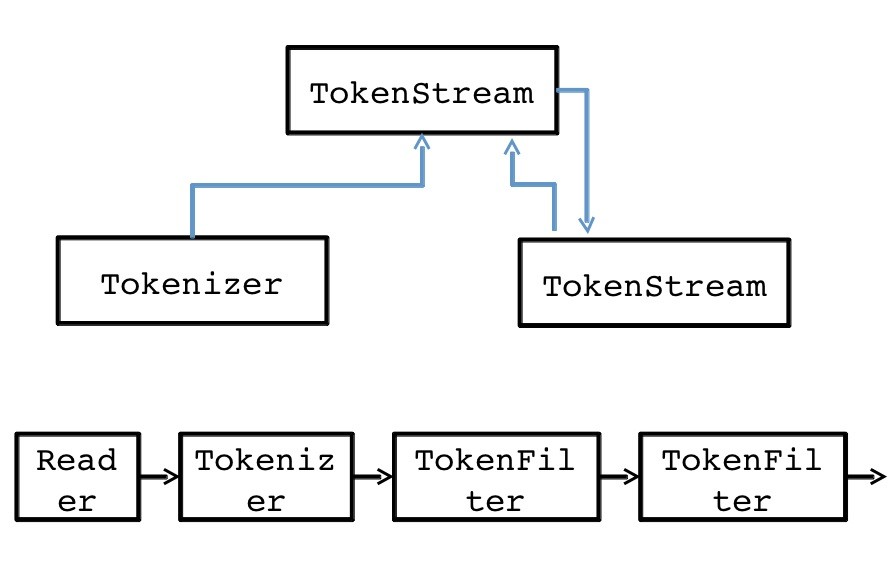
Analyzing Text into Tokens:
Search and indexing over text fields require processing text data into tokens. The package oal.analysis contains the base classes for tokenizing and indexing text. Processing may consist of a sequence of transformations , e.g., whitespace tokenization, case normalization, stop-listing, and stemming.
The abstract class oal.analysis.TokenStream breaks the incoming text into a sequence of tokens that are retrieved using an iterator-like pattern. TokenStream has two subclasses: oal.analysis.Tokenizer and oal.analysis.TokenFilter. A Tokenizer takes a java.io.Reader as input whereas a TokenFilter takes another oal.analysis.TokenStream as input. This allows us to chain together tokenizers such that the initial tokenizer gets its input from a reader and the others operate on tokens from the preceding TokenStream in the chain.
An oal.analysis.Analyzer supplies the indexing and searching processes with TokenStreams on a per-field basis. It maps field names to tokenizers and may also supply a default analyzer for unknown field names. Lucene includes many analysis modules that provide concrete implementations of different kinds of analyzers. As of Lucene 4, these modules are bundled into separate jar files. There are several dozen language-specific analysis packages, from oal.analysis.ar for Arabic to oal.analysis.tr for Turkish. The package oal.analysis.core provides several general-purpose analyzers, tokenizers, and tokenizer factory classes.
The abstract class oal.analysis.Analyzer contains methods used to extract terms from input text. Concrete subclasses of Analyzer must override the method createComponents, which returns an object of the nested class TokenStreamComponents that defines the tokenization process and provides access to initial and file components of the processing pipeline. The initial component is a Tokenizer that handles the input source. The final component is an instance of TokenFilter and it is the TokenStream returned by the method Analyzer.tokenStream(String,Reader). Here is an example of a custom Analyzer that tokenizes its inputs into individual words with all letters lowercase.
Analyzer analyzer = new Analyzer() {
@Override
protected TokenStreamComponents createComponents(String fieldName, Reader reader) {
Tokenizer source =
new StandardTokenizer(VERSION,reader);
TokenStream filter =
new LowerCaseFilter(VERSION,source);
return new TokenStreamComponents(source, filter);
}
};
The constructors for the oal.analysis.standard.StandardTokenizer and oal.analysis.core.LowerCaseFilter objects require a Version argument. Further note that package oal.analysis.standard is distributed in the jarfile lucene-analyzers-common-4.x.y.jar, where x and y are the minor version and release number.
Which core analyzer should we use?
We’ve now seen the substantial differences in how each of the four core Lucene analyzers works. To choose the right one for our application surprise us: most applications don’t use any of the built-in analyzers, and instead opt to create their own analyzer chain. For those applications that do use a core analyzer, StandardAnalyzer is likely the most common choice. The remaining core analyzers are usually far too simplistic for most applications, except perhaps for specific use cases (for example, a field that contains a list of part numbers might use Whitespace-Analyzer). But these analyzers are great for test cases and are indeed used heavily by Lucene‘s unit tests.
Typically an application has specific needs, such as customizing the stop-words list, performing special tokenization for application-specific tokens like part numbers or for synonym expansion, preserving case for certain tokens, or choosing a specific stemming algorithm.
