Being mostly a techie, I’ve recently and admittedly been deceived by my own Dilbertesque attitude when I stumbled upon this buzzword-filled TechCrunch article about Espresso Logic. Ever concerned about my social media reputation (e.g. reddit and hackernews karma), I thought it would be witty to put a link on those platforms titled:
Just found this article on TechCrunch. Reads like a markov-chain-generated series of buzzwords.
With such a catchy headline, the post quickly skyrocketed – and like many other redditors, my thoughts were with Geek and Poke:

But like a few other redditors, I couldn’t resist clicking through to the actual product that claims to implement “reactive programming” through a REST and JSON API. And I’m frankly impressed by the ideas behind this product. For once, the buzzwords are backed by software implementing them very nicely! Let’s first delve into…
Reactive Programming
Reactive programming is a term that has gained quite some traction recently around Typesafe, the company behind Akka. It has also gained additional traction since Erik Meijer (creator of LINQ) has left Microsoft to fully dedicate his time to his new company Applied Duality. With those brilliant minds sharply on the topic, we’ll certainly hear more about the Reactive Manifesto in the near future.
 But in fact, every manager knows the merits of “reactive programming” already as they’re working with the most reactive and probably the most awesome software on the planet: Microsoft Excel, a device whose mystery is only exceeded by its power. Think about how awesome Excel is. You have hundreds of rules, formulas, cell-interdependencies. And any time you change a value, the whole spreadsheet magically updates itself. That’s Reactive Programming.
But in fact, every manager knows the merits of “reactive programming” already as they’re working with the most reactive and probably the most awesome software on the planet: Microsoft Excel, a device whose mystery is only exceeded by its power. Think about how awesome Excel is. You have hundreds of rules, formulas, cell-interdependencies. And any time you change a value, the whole spreadsheet magically updates itself. That’s Reactive Programming.
The power of reactive programming lies in its expressiveness. With only very little expressive logic, you can express what otherwise needs dozens of lines of SQL, or hundreds of lines of Java.
Espresso Logic
With this in mind, I started to delve into Espresso Logic’s free trial. Note, that I’m the kind of impatient person who wants quick results without reading the docs. In case you work the other way round, there are some interesting resources to get you started:
Anyway, the demo ships with a pre-installed MySQL database containing what looks like a typical E-Commerce schema containing customer, employee, lineitem, product, purchaseorder, and purchaseorder_audit tables:
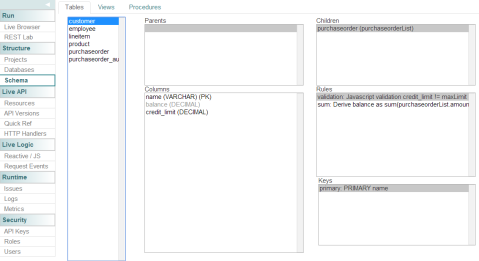
So I get schema navigation information (such as parent / child relationships) and an overview of rules. These rules look like triggers calculating sums or validating things. We’ll get to these rules later on.
Live API
So far, things are as expected. The UI is maybe a bit edgy, as the product only exists since late 2013. But what struck me as quite interesting is what Espresso Logic calls the Live API. With a couple of clicks, I can assemble a REST Resource tree structure from various types of resources, such as database tables. The Espresso Designer will then almost automatically join tables to produce trees like this one:
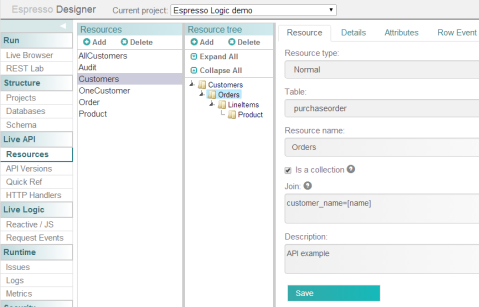
Notice how I can connect child entities to their parents quite easily. Now, this API is still a bit limited. For instance, I couldn’t figure out how to drag-and-drop a reporting relationship where I calculate the order amount per customer and product. However, I can switch the Resource Type from “Normal” to “SQL” to achieve just that with a plain old GROUP BY and aggregate function.
I started to grasp that I’m actually managing and developing a RESTful API based on the available database resources! A little further down the menu, I then found the “Quick Ref” item, which helped me understand how to call this API:
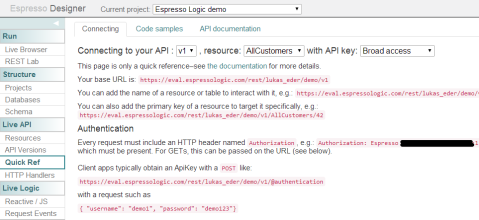
So, each of the previously defined resources is exposed through a URL as I’d expect from any RESTful API. What looks really nice is that I have built-in API versioning and an API key. Note, it is strongly discouraged from an OWASP point of view to pass API keys around in GET requests. This is just a use-case for a quick-start demo and for the odd developer test. Do not use this in production!
Anyway, I called the URL in my browser with the API key as parameter (going against my own rules):
https://eval.espressologic.com/rest/[my-user]/demo/v1/AllCustomers?auth=[my-key]:1
And I got a JSON document like this:
[
{
"@metadata": {
"href": "https://eval.espressologic.com/rest/[my-user]/demo/v1/Customers/Alpha%20and%20Sons",
"checksum": "A:cf1f4fb79e8e7142"
},
"Name": "Alpha and Sons",
"Balance": 105,
"CreditLimit": 900,
"links": [
],
"Orders": [
{
"@metadata": {
"href": "https://eval.espressologic.com/rest/[my-user]/demo/v1/Customers.Orders/6",
"checksum": "A:0bf14e2d58cc97b5"
},
"OrderNumber": 6,
"TotalAmount": 70,
"Paid": false,
"Notes": "Pack with care - fragile merchandise",
"links": [
], ...Notice how each resource has a link and a checksum. The checksum is needed for optimistic locking, which is built-in, should you choose to concurrently update any of the above resources. Notice also, how the nested resource Orders is referenced as Customers.Orders. I can also access it directly by calling the above URL.
Live Logic / Reactive Programming
So far so good. Similar things have been implemented in a variety of software. For instance, Adobe Experience Manager / Apache Sling intuitively exposes the JCR repository through REST as well. But where the idea behind Espresso Logic really started fascinating me is when I clicked on “Live Logic”, and I was exposed to a preconfigured set of rules that are applied to the data:
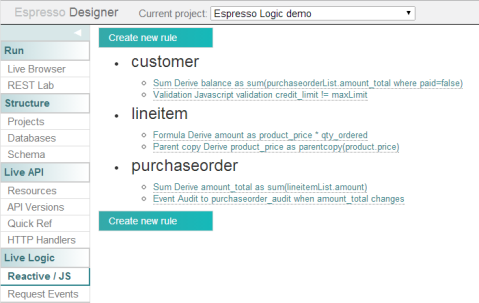
I’ve quickly skimmed through the manual to see if I understood correctly. These rules actually resemble the kind of rules that I can enter in any spreadsheet software. For instance, it appears as though the customer.balance column is calculated as the sum of all purchaseorder.amount_total having a paid value of false, and so on.
So, if I continue through this rule-chain I’ll wind up with lineitem.product_price being the shared dependency of all other calculated values. When changing that value, a whole set of updates should run through my rule set to finally change the customer.balance:
changing lineitem.product_price
-> changes lineitem.amount
-> changes purchaseorder.amount_total
-> changes customer.balanceDepending how much of a console hacker you are, you might want to write your own PUT call using curl, or you can leverage the REST Lab from the Espresso Designer, which helps you get all the parameters right. So, assuming we want to change a line item from the previous call:
{
"@metadata": {
"href": "https://eval.espressologic.com/rest/[my_user]/demo/v1/Customers.Orders.LineItems/11",
"checksum": "A:2e3d8cb0bff42763"
},
"lineitem_id": 11,
"ProductNumber": 2,
"OrderNumber": 6,
"Quantity": 2,
"Price": 25,
...Let’s just try to update that to have a price of 30:
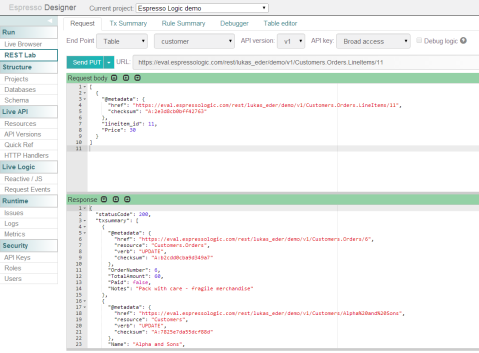
And you can see in the response, there is a transaction summary, which shows that the Customers.Orders.TotalAmount has changed from 50 to 60, the Customers.Balance has changed from 105 to 95, and an audit record has been written. The audit record itself is also defined by a rule like any other rule. But there’s also an ordinary log file that shows what really happened when I ran this PUT request:
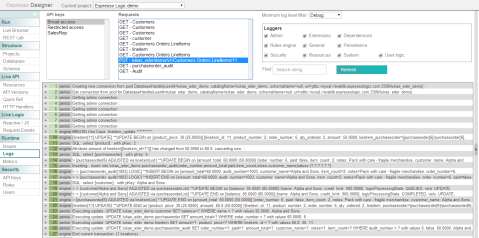
Imagine having to put all those INSERT and UPDATE statements into a correct order yourself, and correctly manage caching, and transactions! Instead, all we have done is define some rules. For a complete overview of what rule types are available, consider this page of the Live Logic manual
Out of scope features for this post
… So far, we’ve had a look at the most obvious features of Espresso Logic. There are more, though. A couple of examples:
Server-side JavaScript
If rules cannot express it, JavaScript can. There are various points of the application where you can inject your JavaScript snippets, e.g. for validation, more complex rule expressions, request and response transformation, etc. Although we haven’t tried it, it reads like row-based triggers written in JavaScript.
Stored procedure support
The people behind Espresso Logic are “legacy-embracing” people, just like us at Data Geekery. Their target audience might already have thousands of complex stored procedures with lots of business logic in them. Those should not be rewritten in JavaScript. But just like tables, views, and REST resources, they are exposed through the REST API, taking GET parameters for IN parameters and returning JSON for OUT parameters and cursors.
From a jOOQ perspective, it’s pretty awesome to see that someone else is taking stored procedures as seriously as we do.
Row / column level security
There is a built-in user and role management module that allows you to provide centrally-managed, fine-grained access control to your data. Not many databases support row-level security like the Oracle database, for instance. So having this kind of feature in your platform really adds value to many RDBMS integrations. Some further resources on that topic:
Conclusion: Querying vs. updating vs. rule-based persistence
On our jOOQ blog and our marketing websites (e.g. hibernate-alternative.com), we always advocate two main use-cases when operating on databases:
- Querying: You have very complex queries to calculate things like reports. For this, SQL (e.g. through jOOQ) is perfect
- Updating: You have a very complex domain model with lots of items and deltas that you want to persist in one go. For this, Hibernate / ORMs are perfect
But today, Espresso Logic has shown to us that there is yet another use-case. One that is covered by reactive programming (or “spreadsheet-programming“) techniques. And that’s:
- Rule-based persistence: You have a very complex domain model with lots of items and lots of rules which you want to validate, calculate, and keep in sync all the time. For this, both SQL and ORMs are solutions at the wrong level of abstraction.
This “new” use-case is actually quite common in a lot of enterprise applications where complex business rules are currently spelled out in millions of lines of imperative code that is very hard to decipher and even harder to validate / modify. How can you reverse-engineer your business rules from millions of lines of legacy code, written in COBOL?
At Data Geekery, we’re always looking out for brand new tech. Espresso Logic is a young startup with a new product. Yet, as originally mentioned, they’re a startup with seed funding, a very compelling and innovative idea, and a huge market of legacy COBOL applications that wants to start delving into “sexy” new technologies, such as RESTful APIs, JSON, reactive programming. It might just work! If you haven’t seen enough, go work through this tutorial, which covers advanced examples such as a “bill of materials price rollup”, “bill of materials kit explosion”, “budget rollup”, “audit salary chagnes” and more.
We’ll certainly keep an eye out for future improvements to the Espresso Logic platform!
| Reference: | The Power of Spreadsheets in a Reactive, RESTful API from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |
