Hadoop is a framework written in Java for running applications on large clusters of commodity hardware and incorporates features similar to those of the Google File System and of MapReduce. HDFSis a highly fault-tolerant distributed file system and like Hadoop designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications that have large data sets.
Hadoop is mainly used by the companies which deal with large amount of data. They may need to Process the data, Perform Analysis or Generate Reports. Currently all leading organizations including Facebook, Yahoo, Amazon, IBM, Joost, PowerSet, New York Times, Veoh etc are using Hadoop. For more information check the PoweredBy Hadoop page.

Why Hadoop:
MapReduce is Google’s secret weapon: A way of breaking complicated problems apart, and spreading them across many computers. Hadoop is an open source implementation of MapReduce, and its own filesystem HDFS (Hadoop distributed file system).
Hadoop has defeated Super Computer in tera sort:
Hadoop clusters sorted 1 terabyte of data in 209 seconds, which beat the previous record of 297 seconds in the annual general purpose (daytona) terabyte sort benchmark. The sort benchmark, which was created in 1998 by Jim Gray, specifies the input data (10 billion 100 byte records), which must be completely sorted and written to disk. This is the first time that either a Java or an open source program has won. For more Information click here.
Europe’s Largest Ad Targeting Platform Uses Hadoop:
Europe’s Largest Ad Company get over 100GB of data daily, Now using classical solution like RDBMS they need 5 days to for analysis and generate reports. So they were running 1 weak behind. After lots of research they started using hadoop. Now Interesting fact is “Tey are able to process data and generate reports with in 1 Hour” Thats the beauty of Hadoop. For more Information click here.
Leading Distributions of Hadoop:
1. Apache Hadoop:
The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing.
Apache Hadoop Offers:
- Hadoop Common: The common utilities that support the other Hadoop subprojects.
- HDFS: A distributed file system that provides high throughput access to application data.
- MapReduce: A software framework for distributed processing of large data sets on compute clusters.
- Avro: A data serialization system.
- Chukwa: A data collection system for managing large distributed systems.
- HBase: A scalable, distributed database that supports structured data storage for large tables.
- Hive: A data warehouse infrastructure that provides data summarization and ad hoc querying.
- Mahout: A Scalable machine learning and data mining library.
- Pig: A high-level data-flow language and execution framework for parallel computation.
- ZooKeeper: A high-performance coordination service for distributed applications.
2. Cloudera Hadoop:
Cloudera’s Distribution for Apache Hadoop (CDH) sets a new standard for Hadoop-based data management platforms. It is the most comprehensive platform available today and significantly accelerates deployment of Apache Hadoop in your organization. CDH is based on the most recent stable version of Apache Hadoop. It includes some useful patches backported from future releases, as well as improvements we have developed for our customers
Cloudera Hadoop Offers:
- HDFS – Self healing distributed file system
- MapReduce – Powerful, parallel data processing framework
- Hadoop Common – a set of utilities that support the Hadoop subprojects
- HBase – Hadoop database for random read/write access
- Hive – SQL-like queries and tables on large datasets
- Pig – Dataflow language and compiler
- Oozie – Workflow for interdependent Hadoop jobs
- Sqoop – Integrate databases and data warehouses with Hadoop
- Flume – Highly reliable, configurable streaming data collection
- Zookeeper – Coordination service for distributed applications
- Hue – User interface framework and SDK for visual Hadoop applications
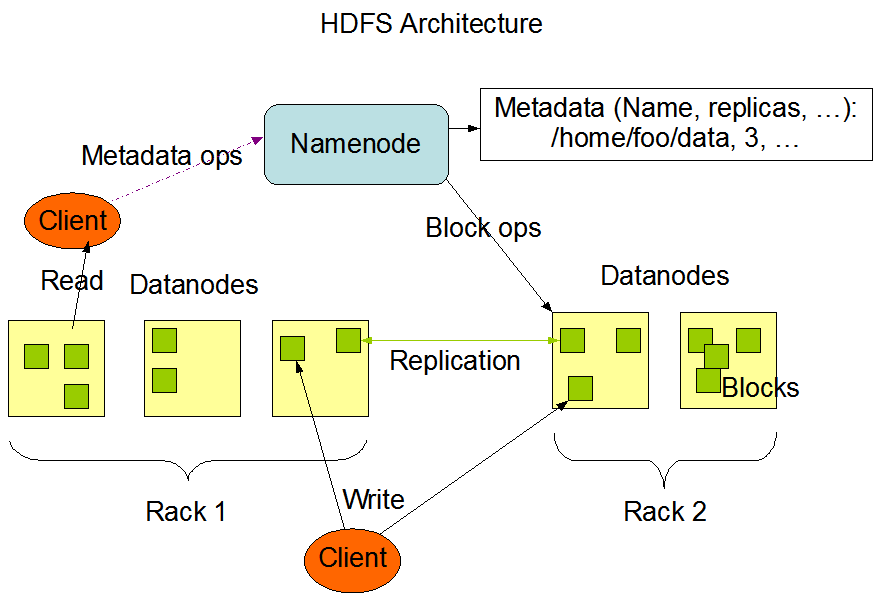
Hadoop can be installed in 3 modes
To deploy Hadoop in standalone mode, we just need to set path of JAVA_HOME. In this mode there is no need to start the daemons and no need of name node format as data save in local disk.
In this mode all the daemons (nameNode, dataNode, secondaryNameNode, jobTracker, taskTracker) run on a single machine.
In this mode, daemons (nameNode, jobTracker, secondaryNameNode(Optionally)) run on master (NameNode) and daemons (dataNode and taskTracker) run on slave (DataNode).Stay tuned for an article on the three Hadoop modes/configurations.
Related Articles :
- MapReduce: A Soft Introduction
- Cajo, the easiest way to accomplish distributed computing in Java
- Hibernate mapped collections performance problems
- Java Code Geeks Andygene Web Archetype
- Servlet 3.0 Async Processing for Tenfold Increase in Server Throughput
Reference: Understanding What is Hadoop from our JCG partner at High Performance Computing blog.

is hadoop would give a competition to the existing ETL(data mining & warehousing) platforms ?