In this post I’ll mention RDD paper, Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. If you didn’t check my post about Spark, I strongly advice you to read it from here: Spark: Cluster Computing with Working Sets.
RDD Abstraction
RDDs is a distributed memory abstraction which leverages applications performance due to it is suitable for iterative algorithms and interactive data mining tools in a fault-tolerant manner. Other cluster computing frameworks such as MapReduce and Dryad lack abstractions for leveraging distributed memory. So, it makes them inefficient for operations which requires reuse of intermediate results. Data reuse is common for many iterative machine learning and graph algorithms i.e. K means clustering, logistic regression and PageRank.
An RDD is a read only, immutable, partitioned collection of records. RDDs provides an interface based on coarse-grained transformations (e.g., map, filter and join) to provide efficiency for fault-tolerance and it is implemented in Spark. To use Spark, developers writes a driver program and it connects to a cluster of workers. The driver defines one or more RDDs and invokes actions on them and Spark code on the driver tracks the lineage of RDDs.
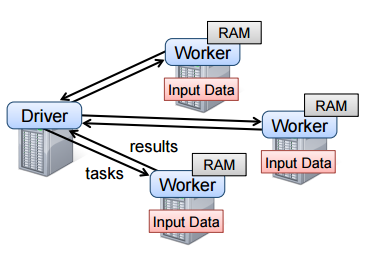
Advantages of RDD Model
RDDs can be compared to DSM (Distributed Shared Memory) systems due to it is a distributed memory abstraction. RDDs have enough information how it was derived from other datasets so a program cannot reference an RDD that it can not reconstruct after a failure. RDDs do not have a mechanism like checkpointing as DSM systems have and only the lost partitions of an RDD need to be recomputed due to a failure which can be done parallel on different nodes.
A runtime schedule tasks based on data locality in bulk operations to improve performance. Also, when there is not enough memory at RAM they can be stored on disk which will provide similar performance to current data-parallel systems.
Applications Not Suitable for RDDs
RDDs are best suited for batch applications that apply same operation to all elements of a dataset. RDDs would be less suitable for applications which makes asynchronous fine-grained updates to a shared state i.e. an incremental web crawler or storage system for a web application.
Evaluation
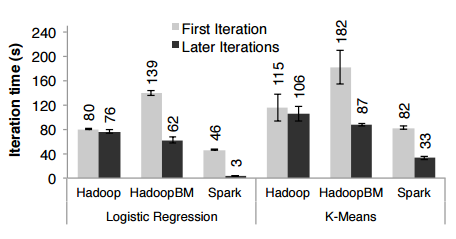
Performance comparison result for iterative machine learning applications:
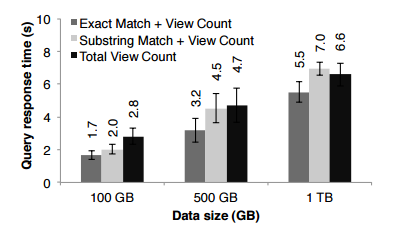
Interactive queries response time comparison:
Conclusion
RDDs is an efficient, general purpose and fault-tolerant data sharing abstraction in cluster computing and is suitable for iterative machine learning algorithms. RDDs offer anAPI based on coarse-grained transformations which can recover data using lienage. RDDs implemented in Spark and outperforms Hadoop by up to 20x in iterative applications and can be used interactively to query large volume of data.
| Reference: | Resilient Distributed Datasets (RDDs) from our JCG partner Furkan Kamaci at the FURKAN KAMACI blog. |
