In the last post of this series on use cases for Elasticsearch we looked at the features Elasticsearch provides for storing even large amounts of documents. In this post we will look at another one of its core features: Search. I am building on some of the information in the previous post so if you haven’t read it you should do so now.
As we have seen we can use Elasticsearch to store JSON documents that can even be distributed across several machine. Indexes are used to group documents and each document is stored using a certain type. Shards are used to distribute parts of an index across several nodes and replicas are copies of shards that are used for distributing load as well as for fault tolerance.
Full Text Search
Everybody uses full text search. The amount of information has just become too much to access it using navigation and categories alone. Google is the most prominent example offering instant keyword search across a huge amount of information.
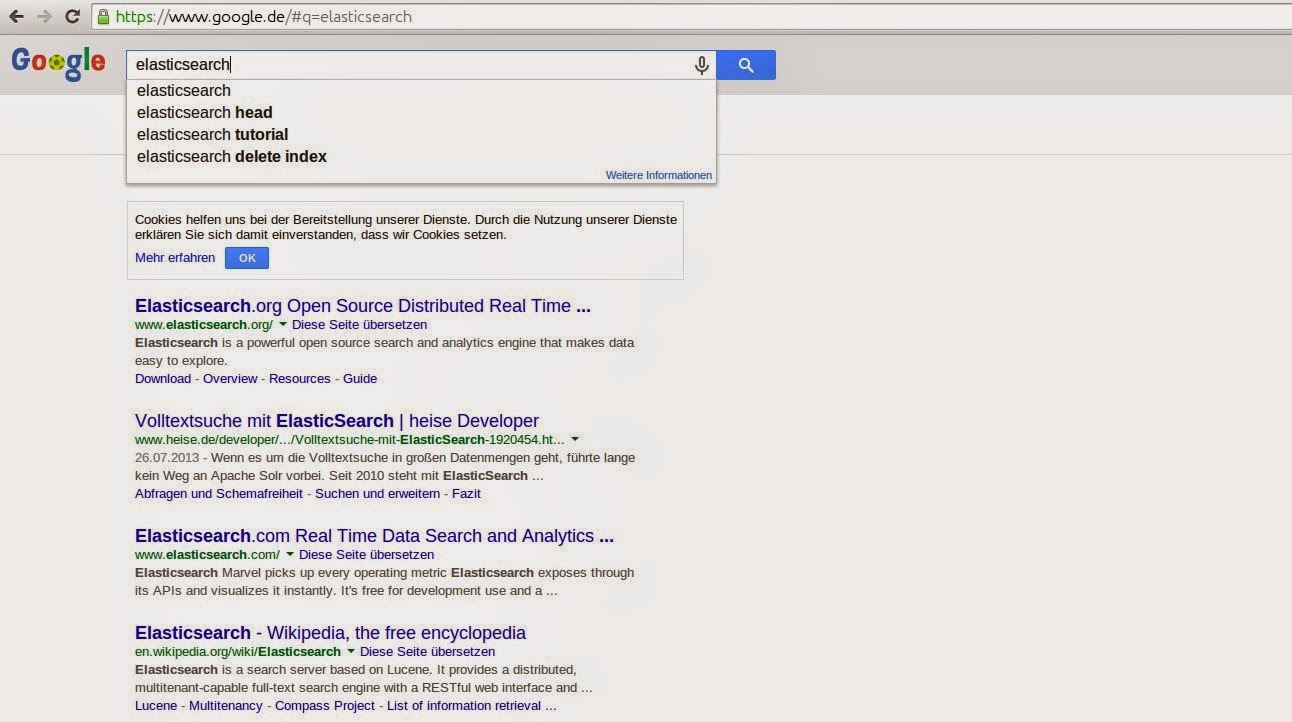
Looking at what Google does we can already see some common features of full text search. Users only provide keywords and expect the search engine to provide good results. Relevancy of documents is expected to be good and users want the results they are looking for on the first page. How relevant a document is can be influenced by different factors like h the queried term exists in a document. Besides getting the best results the user wants to be supported during the search process. Features like suggestions and highlighting on the result excerpt can help with this.
Another area where search is important is E-Commerce with Amazon being one of the dominant players.
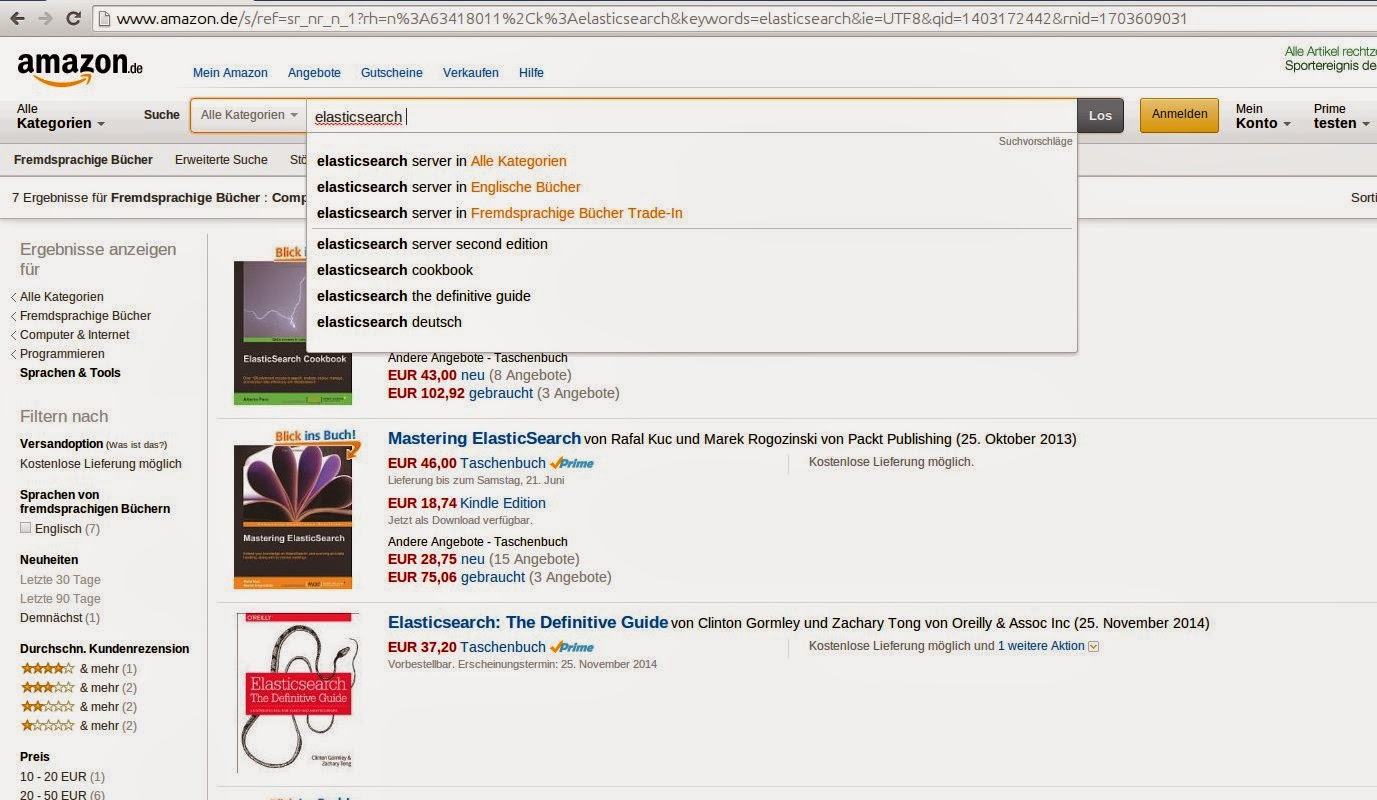
The interface looks similar to the Google one. The user can enter keywords that are then searched for. But there are also slight differences. The suggestions Amazon provides are more advanced, also hinting at categories a term might be found in. Also the result display is different, consisting of a more structured view. The structure of the documents being searched is also used for determining the facets on the left that can be used to filter the current result based on certain criteria, e.g. all results that cost between 10 and 20 €. Finally, relevance might mean something completely different when it comes to something like an online store. Often the order of the result listing is influenced by the vendor or the user can sort the results by criteria like price or release date.
Though neither Google nor Amazon are using Elasticsearch you can use it to build similar solutions.
Searching in Elasticsearch
As with everything else, Elasticsearch can be searched using HTTP. In the most simple case you can append the _search endpoint to the url and add a parameter: curl -XGET "http://localhost:9200/conferences/talk/_search?q=elasticsearch⪯tty=true". Elasticsearch will then respond with the results, ordered by relevancy.
{
"took" : 81,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.067124054,
"hits" : [ {
"_index" : "conferences",
"_type" : "talk",
"_id" : "iqxb7rDoTj64aiJg55KEvA",
"_score" : 0.067124054,
"_source":{
"title" : "Anwendungsfälle für Elasticsearch",
"speaker" : "Florian Hopf",
"date" : "2014-07-17T15:35:00.000Z",
"tags" : ["Java", "Lucene"],
"conference" : {
"name" : "Java Forum Stuttgart",
"city" : "Stuttgart"
}
}
} ]
}
}Though we have searched on a certain type now you can also search multiple types or multiple indices.
Adding a parameter is easy but search requests can become more complex. We might request highlighting or filter the documents according to a criteria. Instead of using parameters for everything Elasticsearch offers the so called Query DSL, a search API that is passed in the body of the request and is expressed using JSON.
This query could be the result of a user trying to search for elasticsearch but mistyping parts of it. The results are filtered so that only talks for conferences in the city of Stuttgart are returned.
curl -XPOST "http://localhost:9200/conferences/_search " -d'
{
"query": {
"match": {
"title" : {
"query": "elasticsaerch",
"fuzziness": 2
}
}
},
"filter": {
"term": {
"conference.city": "stuttgart"
}
}
}'This time we are querying all documents of all types in the index conferences. The query object requests one of the common queries, a match query on the title field of the document. The query attribute contains the search term that would be passed in by the user. The fuzziness attribute requests that we should also find documents that contain terms that are similar to the term requested. This will take care of the misspelled term and also return results containing elasticsearch. The filter object requests that all results should be filtered according to the city of the conference. Filters should be used whenever possible as they can be cached and do not calculate the relevancy which should make them faster.
Normalizing Text
As search is used everywhere users also have some expectations of how it should work. Instead of issuing exact keyword matches they might use terms that are only similar to the ones that are in the document. For example a user might be querying for the term Anwendungsfall which is the singular of the contained term Anwendungsfälle, meaning use cases in German: curl -XGET "http://localhost:9200/conferences/talk/_search?q=title:anwendungsfall⪯tty=true"
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : null,
"hits" : [ ]
}
}No results. We could try to solve this using the fuzzy search we have seen above but there is a better way. We can normalize the text during indexing so that both keywords point to the same term in the document.
Lucene, the library search and storage in Elasticsearch is implemented with provides the underlying data structure for search, the inverted index. Terms are mapped to the documents they are contained in. A process called analyzing is used to split the incoming text and add, remove or modify terms.

On the left we can see two documents that are indexed, on the right we can see the inverted index that maps terms to the documents they are contained in. During the analyzing process the content of the documents is split and transformed in an application specific way so it can be put in the index. Here the text is first split on whitespace or punctuation. Then all the characters are lowercased. In a final step the language dependent stemming is employed that tries to find the base form of terms. This is what transforms our Anwendungsfälle to Anwendungsfall.
What kind of logic is executed during analyzing depends on the data of your application. The analyzing process is one of the main factors for determining the quality of your search and you can spend quite some time with it. For more details you might want to look at my post on the absolute basics of indexing data.
In Elasticsearch, how fields are analyzed is determined by the mapping of the type. Last week we have seen that we can index documents of different structure in Elasticsearch but as we can see now Elasticsearch is not exactly schema free. The analyzing process for a certain field is determined once and cannot be changed easily. You can add additional fields but you normally don’t change how existing fields are stored.
If you don’t supply a mapping Elasticsearch will do some educated guessing for the documents you are indexing. It will look at any new field it sees during indexing and do what it thinks is best. In the case of our title it uses the StandardAnalyzer because it is a string. Elasticsearch does not know what language our string is in so it doesn’t do any stemming which is a good default.
To tell Elasticsearch to use the GermanAnalyzer instead we need to add a custom mapping. We first delete the index and create it again:
curl -XDELETE "http://localhost:9200/conferences/" curl -XPUT "http://localhost:9200/conferences/“
We can then use the PUT mapping API to pass in the mapping for our type.
curl -XPUT "http://localhost:9200/conferences/talk/_mapping" -d'
{
"properties": {
"tags": {
"type": "string",
"index": "not_analyzed"
},
"title": {
"type": "string",
"analyzer": "german"
}
}
}'We have only supplied a custom mapping for two fields. The rest of the fields will again be guessed by Elasticsearch. When creating a production app you will most likely map all of your fields in advance but the ones that are not that relevant can also be mapped automatically. Now, if we index the document again and search for the singular, the document will be found.
Advanced Search
Besides the features we have seen here Elasticsearch provides a lot more. You can automatically gather facets for the results using aggregations which we will look at in a later post. The suggesters can be used to perform autosuggestion for the user, terms can be highlighted, results can be sorted according to fields, you get pagination with each request, …. As Elasticsearch builds on Lucene all the goodies for building an advanced search application are available.
Conclusion
Search is a core part of Elasticsearch that can be combined with its distributed storage capabilities. You can use to Query DSL to build expressive queries. Analyzing is a core part of search and can be influenced by adding a custom mapping for a type. Lucene and Elasticsearch provide lots of advanced features for adding search to your application.
Of course there are lots of users that are building on Elasticsearch because of its search features and its distributed nature. GitHub uses it to let users search the repositories, StackOverflow indexes all of its questions and answers in Elasticsearch and SoundCloud offers search in the metadata of the songs.
In the next post we will look at another aspect of Elasticsearch: Using it to index geodata, which lets you filter and sort results by postition and distance.
| Reference: | Use Cases for Elasticsearch: Full Text Search from our JCG partner Florian Hopf at the Dev Time blog. |
