I’ll be giving an introductory talk about Elasticsearch twice in July, first at Developer Week Nürnberg, then at Java Forum Stuttgart. I am showing some of the features of Elasticsearch by looking at certain use cases. To prepare for the talks I will try to describe each of the use cases in a blog post as well. When it comes to Elasticsearch the first thing to look at often is the search part. But in this post I would like to start with its capabilities as a distributed document store.
Getting Started
Before we start we need to install Elasticsearch which fortunately is very easy. You can just download the archive, unpack it and use a script to start it. As it is a Java based application you of course need to have a Java runtime installed.
# download archive wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.2.1.zip # zip is for windows and linux unzip elasticsearch-1.2.1.zip # on windows: elasticsearch.bat elasticsearch-1.2.1/bin/elasticsearch
Elasticsearch can be talked to using HTTP and JSON.When looking around at examples you will often see curl being used because it is widely available. (See this post on querying Elasticsearch using plugins for alternatives). To see if it is up and running you can issue a GET request on port 9200: curl -XGET http://localhost:9200. If everything is set up correctly Elasticsearch will respond with something like this:
{
"status" : 200,"name" : "Hawkeye",
"version" : {
"number" : "1.2.1",
"build_hash" : "6c95b759f9e7ef0f8e17f77d850da43ce8a4b364",
"build_timestamp" : "2014-06-03T15:02:52Z",
"build_snapshot" : false,
"lucene_version" : "4.8"
},
"tagline" : "You Know, for Search"
}Storing Documents
When I say document this means two things. First, Elasticsearch stores JSON documents and even uses JSON internally a lot. This is an example of a simple document that describes talks for conferences.
{
"title" : "Anwendungsfälle für Elasticsearch",
"speaker" : "Florian Hopf",
"date" : "2014-07-17T15:35:00.000Z",
"tags" : ["Java", "Lucene"],
"conference" : {
"name" : "Java Forum Stuttgart",
"city" : "Stuttgart"
}
}There are fields and values, arrays and nested documents. Each of those features is supported by Elasticsearch. Besides the JSON documents that are used for storing data in Elasticsearch, document refers to the underlying library Lucene, that is used to persist the data and handles data as documents consisting of fields. So this is a perfect match: Elasticsearch uses JSON, which is very popular and supported from lots of technologies. But the underlying data structures also use documents. When indexing a document we can issue a post request to a certain URL. The body of the request contains the document to be stored, the file we are passing contains the content we have seen above.
curl -XPOST http://localhost:9200/conferences/talk/ --data-binary @talk-example-jfs.json
When started Elasticsearch listens on port 9200 by default. For storing information we need to provide some additional information in the URL. The first segment after the port is the index name. An index name is a logical grouping of documents. If you want to compare it to the relational world this can be thought of as the database. The next segment that needs to be provided is the type. A type can describe the structure of the doucments that are stored in it. You can again compare this to the relational world, this could be a table, but that is only slightly correct. Documents of any kind can be stored in Elasticsearch, that is why it is often called schema free. We will look at this behaviour in the next post where you will see that schema free isn’t the most appropriate term for it. For now it is enough to know that you can store documents with completely different structure in Elasticsearch. This also means you can evolve your documents and add new fields as appropriate. Note that neither index nor type need to exist when starting indexing documents. They will be created automatically, one of the many features that makes it so easy to start with Elasticsearch. When you are storing a document in Elasticsearch it will automatically generate an id for you that is also returned in the result.
{
"_index":"conferences",
"_type":"talk",
"_id":"GqjY7l8sTxa3jLaFx67_aw",
"_version":1,
"created":true
}In case you want to determine the id yourself you can also use a PUT on the same URL we have seen above plus the id. I don’t want to get into trouble by calling this RESTful but did you notice that Elasticsearch makes good use of the HTTP verbs? Either way how you stored the document you can always retrieve it by specifying the index, type and id.
curl -XGET http://localhost:9200/conferences/talk/GqjY7l8sTxa3jLaFx67_aw?pretty=true
which will respond with something like this:
{
"_index" : "conferences",
[...]
"_source":{
"title" : "Anwendungsfälle für Elasticsearch",
"speaker" : "Florian Hopf",
"date" : "2014-07-17T15:35:00.000Z",
"tags" : ["Java", "Lucene"],
"conference" : {
"name" : "Java Forum Stuttgart",
"city" : "Stuttgart"
}
}
}You can see that the source in the response contains exactly the document we have indexed before.
Distributed Storage
So far we have seen how Elasticsearch stores and retrieves documents and we have learned that you can evolve the schema of your documents. The huge benefit we haven’t touched so far is that it is distributed. Each index can be split into several shards that can then be distributed across several machines. To see the distributed nature in action fortunately we don’t need several machines. First, let’s see the state of our currently running instance in the plugin elasticsearch-kopf (See this post on details how to install and use it):
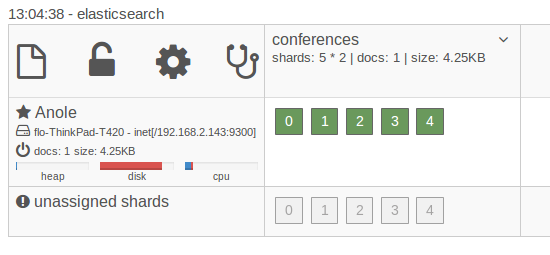
On the left you can see that there is one machine running. The row on top shows that it contains our index conferences. Even though we didn’t explicitly tell Elasticsearch it created 5 shards for our index that are currently all on the instance we started. As each of the shards is a Lucene index in itself even if you are running your index on one instance the documents you are storing are already distributed across several Lucene indexes. We can now use the same installation to start another node. After a short time we should see the instance in the dashboard as well.
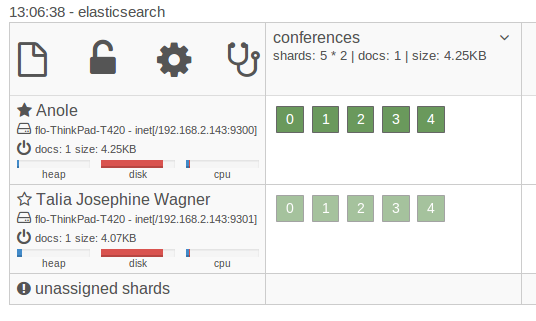
As the new node joins the cluster (which by default happens automatically) Elasticsearch will automatically copy the shards to the new node. This is because by default it not only uses 5 shards but also 1 replica, which is a copy of a shard. Replicas are always placed on different nodes than their shards and are used for distributing the load and for fault tolerance. If one of the nodes crashes the data is still available on the other node. Now, if we start another node something else will happen. Elasticsearch will rebalance the shards. It will copy and move shards to the new node so that the shards are distributed evenly across the machines.
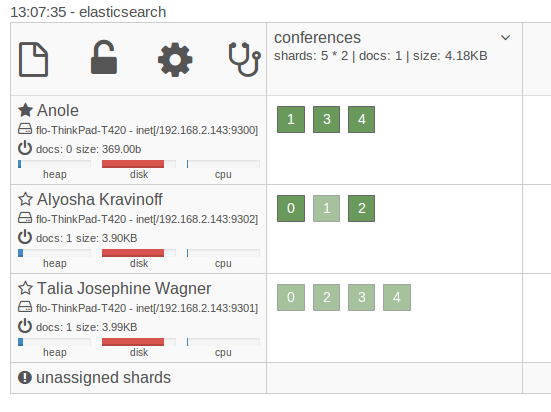
Once defined when creating an index the number of shards can’t be changed. That’s why you normally overallocate (create more shards than you need right now) or if your data allows it you can create time based indices. Just be aware that sharding comes with some cost and think carefully about what you need. Designing your distribution setup can still be difficult even with Elasticsearch does a lot for you out of the box.
Conclusion
In this post we have seen how easy it is to store and retrieve documents using Elasticsearch. JSON and HTTP are technologies that are available in lots of programming environments. The schema of your documents can be evolved as your requirements change. Elasticsearch distributes the data by default and lets you scale across several machines so it is suited well even for very large data sets. Though using Elasticsearch as a document store is a real use case it is hard to find users that are only using it that way. Nobody retrieves the documents only by id as we have seen in this post but uses the rich query facilities we will look at next week. Nevertheless you can read about how Hipchat uses Elasticsearch to store billions of messages and how Engagor uses Elasticsearch here and here. Both of them are using Elasticsearch as their primary storage. Though it sounds more drastic than it probably is: If you are considering using Elasticsearch as your primary storage you should also read this analysis of Elasticsearchs behaviour in case of network partitions. Next week we will be looking at using Elasticsearch for something obvious: Search.
| Reference: | Use Cases for Elasticsearch: Document Store from our JCG partner Florian Hopf at the Dev Time blog. |
