A graph database and its ecosystem of technologies can yield elegant, efficient solutions to problems in knowledge representation and reasoning. To get a taste of this argument, we must first understand what a graph is. A graph is a data structure. There are numerous types of graph data structures, but for the purpose of this post, we will focus on a type that has come to be known as a property graph. A property graph denotes vertices (nodes, dots) and edges (arcs, lines). Edges in a property graph are directed and labeled/typed (e.g. “marko knows peter”). Both vertices and edges (known generally as elements) can have any number of key/value pairs associated with them. These key/value pairs are called properties. From this foundational structure, a suite of questions can be answered and problems solved.
Object Modeling
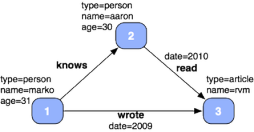
The property graph data structure is nearly identical in form to the object graphs of object oriented programming. Take a collection of objects, remove their methods, and you are left with a property graph. An object’s fields are either primitive and in which cases serve as properties or they are complex and in which case serve as references to other objects. For example, in Java:
class Person {
String name;
Integer age;
Collection<Person> knows;
}The name and age properties are vertex properties of the particular person instance and the knows property refer to knows-labeled edges to other people. Emil Eifrem of Neo Technology espouses the view that property graphs are “whiteboard friendly” as they are aligned with the semantics of modern object oriented languages and the diagramming techniques used by developers. A testament to this idea is the jo4neo project by Taylor Cowan. With jo4neo, Java annotations are elegantly used to allow for the backing of a Java object graph by the Neo4j graph database. Beyond the technological benefits, the human mind tends to think in terms of objects and their relations. Thus, graphs may be considered “human brain friendly” as well.
Given an object graph, questions can be answered about the domain. In the graph traversal DSL known as Gremlin, we can ask questions of the object graph:
// Who does Marko know?
marko.outE('knows').inV
// What are the names of the people that Marko knows?
marko.outE('knows').inV.name
// What are the names and ages of the people that Marko knows?
marko.outE('knows').inV.emit{[it.name, it.age]}
// Who does Marko know that are 30+ years old?
marko.outE('knows').inV{it.age > 30}Concept Modeling

From the instances that compose a model, there may exist abstract concepts. For example, while there may be book instances, there may also be categories for which those books fall–e.g. science fiction, technical, romance, etc. The graph is a flexible structure in that it allows one to express that something is related to something else in some way. These somethings may be real or ethereal. As such, ontological concepts can be represented along with their instances and queried appropriately to answer questions.
// What are the parent categories of history?
x = []; history.inE('subCategory').outV.aggregate(x).loop(3){!it.equals(literature)}; x
// How many descendant categories does fiction have?
c = 0; fiction.outE('subCategory').inV.foreach{c++}.loop(3){true}; c
// Is romance at the same depth as history?
c = 0; romance.inE('subCategory').outV.loop(2){c++; !it.equals(literature)}.outE('subCategory').inV.loop(2){c--; !it.equals(history)}; c == 0Automated Reasoning
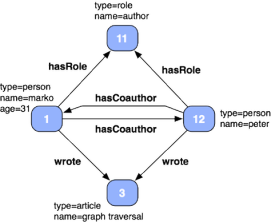
From the explicit objects, their relationships, and their abstract categories, reasoning processes can be enacted. A tension that exists in graph modeling is what to make explicit (structure) and what to infer through traversal (process). The trade-off is between, like much of computing, space and time. If there exists an edge from a person to their coauthors, then its a single hop to get from that person to his or her coauthors. If, on the other hand, coauthors must be inferred through shared writings, then a multi-hop step is computed to determine coauthors. Reasoning is the process of making what is implicit explicit. A couple simple reasoning examples are presented below using Gremlin.
// Two people who wrote the same book/article/etc. are coauthors
g.V{x = it}.outE('wrote').inV.inE('wrote').outV.except([x])[0].foreach{g.addEdge(null, x, it, 'hasCoauthor')}
// People who write literature are authors
author = g.addVertex(); author.type='role'; author.name='author'
g.V.foreach{it.outE('wrote').inV[0].foreach{g.addEdge(null, it, author, 'hasRole')} >> -1}In the examples above, a full graph analysis is computed to determine all coauthors and author roles. However, nothing prevents the evaluation of local inference algorithms.
// Marko's coauthors are those people who wrote the same books/articles/etc. as him
marko.outE('wrote').inV.inE('wrote').outV.except([marko])[0].foreach{g.addEdge(null, x, it, 'hasCoauthor')}Conclusion
Graphs are useful for modeling objects, their relationships to each other, and the conceptual structures wherein which they lie. From this explicit information, graph query and inference algorithms can be evaluated to answer questions on the graph and to increase the density of the explicit knowledge contained within the graph (i.e. increase the number of vertices and edges). This particular graph usage pattern has been exploited to a great extent in the world of RDF (knowledge representation) and RDFS/OWL (reasoning). The world of RDF/RDFS/OWL is primarily constrained to description logics (see an argument to the contrary here). Description logics are but one piece of the larger field of knowledge representation and reasoning. There are numerous logics that can be taken advantage of. In the emerging space of graph databases, the necessary building blocks exist to support the exploitation of other logics. Moreover, these logics, in some instances, may be used concurrently within the same graphical structure. To this point, the reading list below provides a collection of books that explicate different logics and ideas regarding heterogeneous reasoning. Graph databases provide a green field by which these ideas can be realized.
Further Reading
- Brachman, R., Levesque, H., “Knowledge Representation and Reasoning,” Morgan Kaufmann, 2004.
- Wang, P., “Rigid Flexibility: The Logic of Intelligence,” Springer, 2006.
- Mueller, E.T., “Commonsense Reasoning,” Morgan Kaufmann, 2006.
- Minsky, M., “The Society of Mind,” Simon & Schuster, 1988.
| Reference: | Knowledge Representation and Reasoning with Graph Databases from our JCG partner Marko Rodriguez at the Marko A. Rodriguez’s blog blog. |

Knowledge representation