Search engines are all about looking up strings. The user enters a query term that is then retrieved from the inverted index. Sometimes a user is looking for a value that is only a substring of values in the index and the user might be interested in those matches as well. This is especially important for languages like German that contain compound words like Semmelknödel where Knödel means dumpling and Semmel specializes the kind.
Wildcards
For demoing the approaches I am using a very simple schema. Documents consist of a text field and an id. The configuration as well as a unit test is also vailable on Github.
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="text" type="text_general" indexed="true" stored="false"/>
</fields>
<uniqueKey>id</uniqueKey>
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</types>One approach that is quite popular when doing prefix or suffix matches is to use wildcards when querying. This can be done programmatically but you need to take care that any user input is then escaped correctly. Suppose you have the term dumpling in the index and a user enters the term dump. If you want to make sure that the query term matches the document in the index you can just add a wildcard to the user query in the code of your application so the resulting query then would be dump*.
Generally you should be careful when doing too much magic like this: if a user is in fact looking for documents containing the word dump she might not be interested in documents containing dumpling. You need to decide for yourself if you would like to have only matches the user is interested in (precision) or show the user as many probable matches as possible (recall). This heavily depends on the use cases for your application.
You can increase the user experience a bit by boosting exact matches for your term. You need to create a more complicated query but this way documents containing an exact match will score higher:
dump^2 OR dump*
When creating a query like this you should also take care that the user can’t add terms that will make the query invalid. The SolrJ method escapeQueryChars of the class ClientUtils can be used to escape the user input.
If you are now taking suffix matches into account the query can get quite complicated and creating a query like this on the client side is not for everyone. Depending on your application another approach can be the better solution: You can create another field containing NGrams during indexing.
Prefix Matches with NGrams
NGrams are substrings of your indexed terms that you can put in an additional field. Those substrings can then be used for lookups so there is no need for any wildcards. Using the (e)dismax handler you can automatically set a boost on your field that is used for exact matches so you get the same behaviour we have seen above.
For prefix matches we can use the EdgeNGramFilter that is configured for an additional field:
...
<field name="text_prefix" type="text_prefix" indexed="true" stored="false"/>
...
<copyField source="text" dest="text_prefix"/>
...
<fieldType name="text_prefix" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
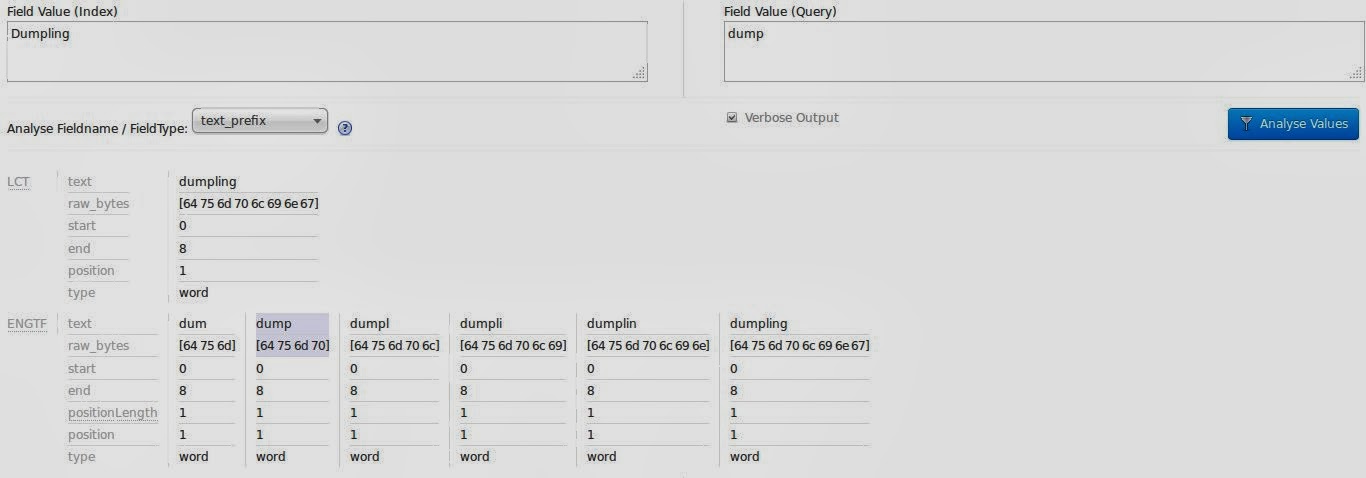
</fieldType>During indexing time the text field value is copied to the text_prefix field and analyzed using the EdgeNGramFilter. Grams are created for any length between 3 and 15, starting from the front of the string. When indexing the term dumpling this would be:
- dum
- dump
- dumpl
- dumpli
- dumplin
- dumpling
During query time the term is not split again so that the exact match for the substring can be used. As usual, the analyze view of the Solr admin backend can be a great help for seeing the analyzing process in action.
Using the dismax handler you can now pass in the user query as it is and just advice it to search on your fields by adding the parameter qf=text^2,text_prefix.
Suffix Matches
With languages that have compound words it’s a common requirement to also do suffix matches. If a user queries for the term Knödel (dumpling) it is expected that documents that contain the termSemmelknödel also match.
Using Solr versions up to 4.3 this is no problem. You can use the EdgeNGramFilterFactory to create grams starting from the back of the string.
...
<field name="text_suffix" type="text_suffix" indexed="true" stored="false"/>
...
<copyField source="text" dest="text_suffix"/>
...
<fieldType name="text_suffix" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="back"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
...This creates suffixes of the indexed term that also contains the term knödel so our query works.
But, using more recent versions of Solr you will encounter a problem during indexing time:
java.lang.IllegalArgumentException: Side.BACK is not supported anymore as of Lucene 4.4, use ReverseStringFilter up-front and afterward
at org.apache.lucene.analysis.ngram.EdgeNGramTokenFilter.(EdgeNGramTokenFilter.java:114)
at org.apache.lucene.analysis.ngram.EdgeNGramTokenFilter.(EdgeNGramTokenFilter.java:149)
at org.apache.lucene.analysis.ngram.EdgeNGramFilterFactory.create(EdgeNGramFilterFactory.java:52)
at org.apache.lucene.analysis.ngram.EdgeNGramFilterFactory.create(EdgeNGramFilterFactory.java:34)You can’t use the EdgeNGramFilterFactory anymore for suffix ngrams. But fortunately the stack trace also advices us how to fix the problem. We have to combine it with ReverseStringFilter:
<fieldType name="text_suffix" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.ReverseStringFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="3" maxGramSize="15" side="front"/>
<filter class="solr.ReverseStringFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
</fieldType>This will now yield the same results as before.
Conclusion
Whether you are going for manipulating your query by adding wildcards or if you should be using the NGram approach heavily depends on your use case and is also a matter of taste. Personally I am using NGrams most of the time as disk space normally isn’t a concern for the kind of projects I am working on. Wildcard search has become a lot faster in Lucene 4 so I doubt there is a real benefit there anymore. Nevertheless I tend to do as much processing I can during indexing time.
| Reference: | Prefix and Suffix Matches in Solr from our JCG partner Florian Hopf at the Dev Time blog. |
