ElasticSearch-Hadoop: Indexing product views count and customer top search query from Hadoop to ElasticSearch
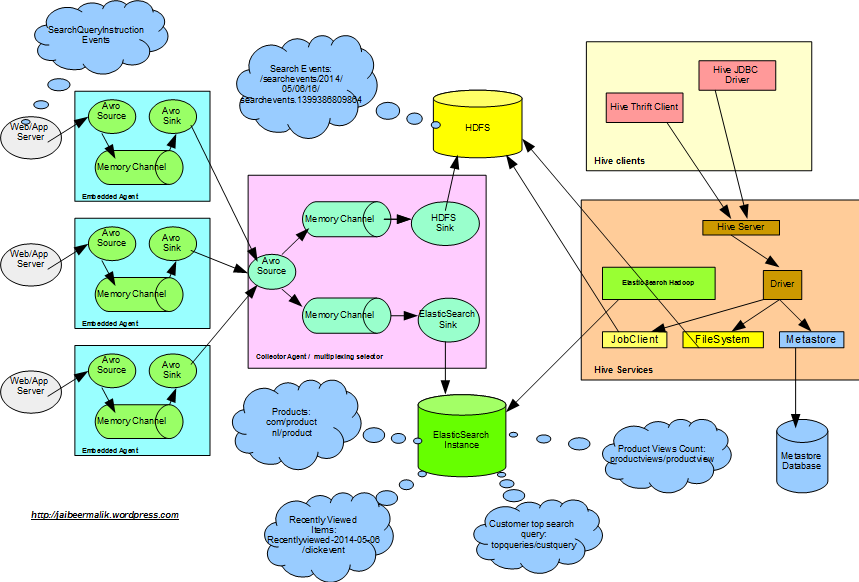
This post covers to use ElasticSearch-Hadoop to read data from Hadoop system and index that in ElasticSearch. The functionality it covers is to index product views count and top search query per customer in last n number of days. The analyzed data can further be used on website to display customer recently viewed, product views count and top search query string.
In continuation to the previous posts on
- Customer product search clicks analytics using big data,
- Flume: Gathering customer product search clicks data using Apache Flume,
- Hive: Query customer top search query and product views count using Apache Hive.
We already have customer search clicks data gathered using Flume and stored in Hadoop HDFS and ElasticSearch, and how to analyze same data using Hive and generate statistical data. Here we will further see how to use the analyzed data to enhance customer experience on website and make it relevant for the end customers.
Recently Viewed Items
We already have covered in first part, how we can use flume ElasticSearch sink to index the recently viewed items directory to ElasticSearch instance and the data can be used to display real time clicked items for the customer.
ElasticSearch-Hadoop
Elasticsearch for Apache Hadoop allows Hadoop jobs to interact with ElasticSearch with small library and easy setup.
Elasticsearch-hadoop-hive, allows to access ElasticSearch using Hive. As shared in previous post, we have product views count and also customer top search query data extracted in Hive tables. We will read and index the same data to ElasticSearch so that it can be used for display purpose on website.
Product views count functionality
Take a scenario to display each product total views by customer in the last n number of days. For better user experience, you can use the same functionality to display to end customer how other customer perceive the same product.
Hive Data for product views
Select sample data from hive table:
# search.search_productviews : id, productid, viewcount 61, 61, 15 48, 48, 8 16, 16, 40 85, 85, 7
Product Views Count Indexing
Create Hive external table “search_productviews_to_es” to index data to ElasticSearch instance.
Use search;
DROP TABLE IF EXISTS search_productviews_to_es;
CREATE EXTERNAL TABLE search_productviews_to_es (id STRING, productid BIGINT, viewcount INT) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'productviews/productview', 'es.nodes' = 'localhost', 'es.port' = '9210', 'es.input.json' = 'false', 'es.write.operation' = 'index', 'es.mapping.id' = 'id', 'es.index.auto.create' = 'yes');
INSERT OVERWRITE TABLE search_productviews_to_es SELECT qcust.id, qcust.productid, qcust.viewcount FROM search_productviews qcust;- External table search_productviews_to_es is created points to ES instance
- ElasticSearch instance configration used is localhost:9210
- Index “productviews” and document type “productview” will be used to index data
- Index and mappins will automatically created if it does not exist
- Insert overwrite will override the data if it already exists based on id field.
- Data is inserting by selecting data from another hive table “search_productviews” storing analytic/statistical data.
Execute the hive script in java to index product views data, HiveSearchClicksServiceImpl.java
Collection<HiveScript> scripts = new ArrayList<>();
HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_productviews_to_es.q"));
scripts.add(script);
hiveRunner.setScripts(scripts);
hiveRunner.call();productviews index sample data
The sample data in ElasticSearch index is stored as below:
{id=48, productid=48, viewcount=10}
{id=49, productid=49, viewcount=20}
{id=5, productid=5, viewcount=18}
{id=6, productid=6, viewcount=9}Customer top search query string functionality
Take a scenario, where you may want to display top search query string by a single customer or all the customers on the website. You can use the same to display top search query cloud on the website.
Hive Data for customer top search queries
Select sample data from hive table:
# search.search_customerquery : id, querystring, count, customerid 61_queryString59, queryString59, 5, 61 298_queryString48, queryString48, 3, 298 440_queryString16, queryString16, 1, 440 47_queryString85, queryString85, 1, 47
Customer Top search queries Indexing
Create Hive external table “search_customerquery_to_es” to index data to ElasticSearch instance.
Use search;
DROP TABLE IF EXISTS search_customerquery_to_es;
CREATE EXTERNAL TABLE search_customerquery_to_es (id String, customerid BIGINT, querystring String, querycount INT) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'topqueries/custquery', 'es.nodes' = 'localhost', 'es.port' = '9210', 'es.input.json' = 'false', 'es.write.operation' = 'index', 'es.mapping.id' = 'id', 'es.index.auto.create' = 'yes');
INSERT OVERWRITE TABLE search_customerquery_to_es SELECT qcust.id, qcust.customerid, qcust.queryString, qcust.querycount FROM search_customerquery qcust;- External table search_customerquery_to_es is created points to ES instance
- ElasticSearch instance configration used is localhost:9210
- Index “topqueries” and document type “custquery” will be used to index data
- Index and mappins will automatically created if it does not exist
- Insert overwrite will override the data if it already exists based on id field.
- Data is inserting by selecting data from another hive table “search_customerquery” storing analytic/statistical data.
Execute the hive script in java to index data HiveSearchClicksServiceImpl.java
Collection<HiveScript> scripts = new ArrayList<>();
HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_customerquery_to_es.q"));
scripts.add(script);
hiveRunner.setScripts(scripts);
hiveRunner.call();topqueries index sample data
The topqueries index data on ElasticSearch instance is as shown below:
{id=474_queryString95, querystring=queryString95, querycount=10, customerid=474}
{id=482_queryString43, querystring=queryString43, querycount=5, customerid=482}
{id=482_queryString64, querystring=queryString64, querycount=7, customerid=482}
{id=483_queryString6, querystring=queryString6, querycount=2, customerid=483}
{id=487_queryString86, querystring=queryString86, querycount=111, customerid=487}
{id=494_queryString67, querystring=queryString67, querycount=1, customerid=494}The functionality described above is only sample functionality and ofcourse need to be extended to map to specific business scenario. This may cover business scenario of displaying search query cloud to customers on website or for further Business Intelligence analytics.
Spring Data
Spring ElasticSearch for testing purpose has also been included to create ESRepository to count total records and delete All.
Check the service for details, ElasticSearchRepoServiceImpl.java
Total product views:
@Document(indexName = "productviews", type = "productview", indexStoreType = "fs", shards = 1, replicas = 0, refreshInterval = "-1")
public class ProductView {
@Id
private String id;
@Version
private Long version;
private Long productId;
private int viewCount;
...
...
}
public interface ProductViewElasticsearchRepository extends ElasticsearchCrudRepository<ProductView, String> { }
long count = productViewElasticsearchRepository.count();Customer top search queries:
@Document(indexName = "topqueries", type = "custquery", indexStoreType = "fs", shards = 1, replicas = 0, refreshInterval = "-1")
public class CustomerTopQuery {
@Id
private String id;
@Version
private Long version;
private Long customerId;
private String queryString;
private int count;
...
...
}
public interface TopQueryElasticsearchRepository extends ElasticsearchCrudRepository<CustomerTopQuery, String> { }
long count = topQueryElasticsearchRepository.count();In later posts we will cover to analyze the data further using scheduled jobs,
- Using Oozie to schedule coordinated jobs for hive partition and bundle job to index data to ElasticSearch.
- Using Pig to count total number of unique customers etc.
| Reference: | ElasticSearch-Hadoop: Indexing product views count and customer top search query from Hadoop to ElasticSearch from our JCG partner Jaibeer Malik at the Jai’s Weblog blog. |
