What do you mean by Map-Reduce programming?
MapReduce is a programming model designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks.
The MapReduce programming model is inspired by functional languages and targets data-intensive computations. The input data format is application-specific, and is specified by the user. The output is a set of <key,value> pairs. The user expresses an algorithm using two functions, Map and Reduce. The Map function is applied on the input data and produces a list of intermediate <key,value> pairs. The Reduce function is applied to all intermediate pairs with the same key. It typically performs some kind of merging operation and produces zero or more output pairs. Finally, the output pairs are sorted by their key value. In the simplest form of MapReduce programs, the programmer provides just the Map function. All other functionality, including the grouping of the intermediate pairs which have the same key and the final sorting, is provided by the runtime.
Phases of MapReduce model
The top level unit of work in MapReduce is a job. A job usually has a map and a reduce phase, though the reduce phase can be omitted. For example, consider a MapReduce job that counts the number of times each word is used across a set of documents. The map phase counts the words in each document, then the reduce phase aggregates the per-document data into word counts spanning the entire collection.
During the map phase, the input data is divided into input splits for analysis by map tasks running in parallel across the Hadoop cluster. By default, the MapReduce framework gets input data from the Hadoop Distributed File System (HDFS).
The reduce phase uses results from map tasks as input to a set of parallel reduce tasks. The reduce tasks consolidate the data into final results. By default, the MapReduce framework stores results in HDFS.
Although the reduce phase depends on output from the map phase, map and reduce processing is not necessarily sequential. That is, reduce tasks can begin as soon as any map task completes. It is not necessary for all map tasks to complete before any reduce task can begin.
MapReduce operates on key-value pairs. Conceptually, a MapReduce job takes a set of input key-value pairs and produces a set of output key-value pairs by passing the data through map and reduces functions. The map tasks produce an intermediate set of key-value pairs that the reduce tasks uses as input.
The keys in the map output pairs need not be unique. Between the map processing and the reduce processing, a shuffle step sorts all map output values with the same key into a single reduce input (key, value-list) pair, where the ‘value’ is a list of all values sharing the same key. Thus, the input to a reduce task is actually a set of (key, value-list) pairs.

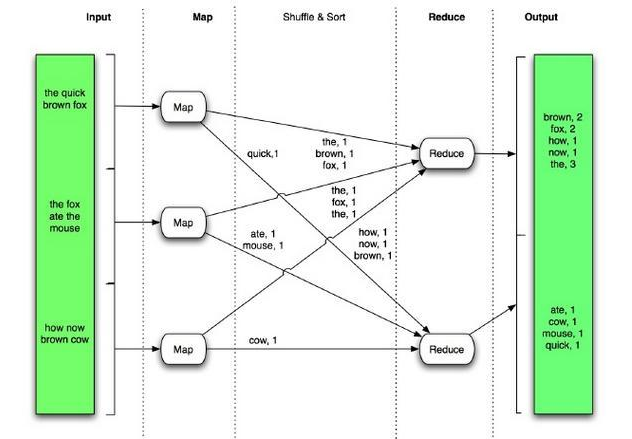
Though each set of key-value pairs is homogeneous, the key-value pairs in each step need not have the same type. For example, the key-value pairs in the input set (KV1) can be (string, string) pairs, with the map phase producing (string, integer) pairs as intermediate results (KV2), and the reduce phase producing (integer, string) pairs for the final results (KV3).
The keys in the map output pairs need not be unique. Between the map processing and the reduce processing, a shuffle step sorts all map output values with the same key into a single reduce input (key, value-list) pair, where the ‘value’ is a list of all values sharing the same key. Thus, the input to a reduce task is actually a set of (key, value-list) pairs.
Example demonstrating MapReduce concepts
The example demonstrates basic MapReduce concept by calculating the number of occurrence of each word in a set of text files.
The MapReduce input data is divided into input splits, and the splits are further divided into input key-value pairs. In this example, the input data set is the two documents, document1 and document2. The InputFormat subclass divides the data set into one split per document, for a total of 2 splits:


Note: The MapReduce framework divides the input data set into chunks called splits using the org.apache.hadoop.mapreduce.InputFormat subclass supplied in the job configuration. Splits are created by the local Job Client and included in the job information made available to the Job Tracker. The JobTracker creates a map task for each split. Each map task uses a RecordReader provided by the InputFormat subclass to transform the split into input key-value pairs.
A (line number, text) key-value pair is generated for each line in an input document. The map function discards the line number and produces a per-line (word, count) pair for each word in the input line. The reduce phase produces (word, count) pairs representing aggregated word counts across all the input documents. Given the input data shown the map-reduce progression for the example job is:
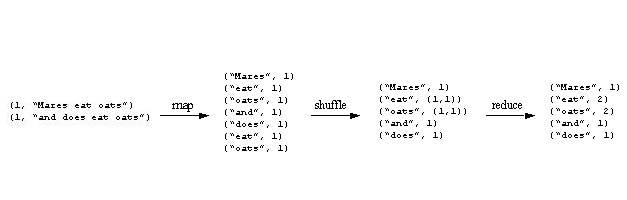
The output from the map phase contains multiple key-value pairs with the same key: The ‘oats’ and ‘eat’ keys appear twice. Recall that the MapReduce framework consolidates all values with the same key before entering the reduce phase, so the input to reduce is actually (key, values) pairs. Therefore, the full progression from map output, through reduce, to final results is shown above.
MapReduce Job Life Cycle
Following is the life cycle of a typical MapReduce job and the roles of the primary actors.The full life cycle are more complex so here we will concentrate on the primary components.
The Hadoop configuration can be done in different ways but the basic configuration consists of the following.
- Single master node running Job Tracker
- Multiple worker nodes running Task Tracker
Following are the life cycle components of MapReduce job.
- Local Job client: The local job Client prepares the job for submission and hands it off to the Job Tracker.
- Job Tracker: The Job Tracker schedules the job and distributes the map work among the Task Trackers for parallel processing.
- Task Tracker: Each Task Tracker spawns a Map Task. The Job Tracker receives progress information from the Task Trackers.
Once map results are available, the Job Tracker distributes the reduce work among the Task Trackers for parallel processing.
Each Task Tracker spawns a Reduce Task to perform the work. The Job Tracker receives progress information from the Task Trackers.
All map tasks do not have to complete before reduce tasks begin running. Reduce tasks can begin as soon as map tasks begin completing. Thus, the map and reduce steps often overlap.
Functionality of different components in MapReduce job
Job Client: Job client performs the following tasks
- Validates the job configuration
- Generates the input splits. This is basically splitting the input job into chunks
- Copies the job resources (configuration, job JAR file, input splits) to a shared location, such as an HDFS directory, where it is accessible to the Job Tracker and Task Trackers
- Submits the job to the Job Tracker
Job Tracker: Job Tracker performs the following tasks
- Fetches input splits from the shared location where the Job Client placed the information
- Creates a map task for each split
- Assigns each map task to a Task Tracker (worker node)
After the map task is complete, Job Tracker does the following tasks
- Creates reduce tasks up to the maximum enabled by the job configuration.
- Assigns each map result partition to a reduce task.
- Assigns each reduce task to a Task Tracker.
Task Tracker: A Task Tracker manages the tasks of one worker node and reports status to the Job Tracker.
Task Tracker does the following tasks when map or reduce task is assigned to it
- Fetches job resources locally
- Spawns a child JVM on the worker node to execute the map or reduce task
- Reports status to the Job Tracker
Debugging Map Reduce
Hadoop keeps logs of important events during program execution. By default, these are stored in the logs/ subdirectory of the hadoop-version/ directory where you run Hadoop from. Log files are named hadoop-username-service-hostname.log. The most recent data is in the .log file; older logs have their date appended to them. The username in the log filename refers to the username under which Hadoop was started — this is not necessarily the same username you are using to run programs. The service name refers to which of the several Hadoop programs are writing the log; these can be jobtracker, namenode, datanode, secondarynamenode, or tasktracker. All of these are important for debugging a whole Hadoop installation. But for individual programs, the tasktracker logs will be the most relevant. Any exceptions thrown by your program will be recorded in the tasktracker logs.
The log directory will also have a subdirectory called userlogs. Here there is another subdirectory for every task run. Each task records its stdout and stderr to two files in this directory. Note that on a multi-node Hadoop cluster, these logs are not centrally aggregated — you should check each TaskNode’s logs/userlogs/ directory for their output.
Debugging in the distributed setting is complicated and requires logging into several machines to access log data. If possible, programs should be unit tested by running Hadoop locally. The default configuration deployed by Hadoop runs in “single instance” mode, where the entire MapReduce program is run in the same instance of Java as called JobClient.runJob(). Using a debugger like Eclipse, you can then set breakpoints inside the map() or reduce() methods to discover your bugs.
Is reduce job mandatory?
Some jobs can complete all their work during the map phase. SO the Job can be map only job. To stop a job after the map completes, set the number of reduce tasks to zero.
Conclusion
This module described the MapReduce execution platform at the heart of the Hadoop system. By using MapReduce, a high degree of parallelism can be achieved by applications. The MapReduce framework provides a high degree of fault tolerance for applications running on it by limiting the communication which can occur between nodes.
| Reference: | Hadoop MapReduce Concepts from our JCG partner Kaushik Pal at the TechAlpine – The Technology world blog. |
