There is a saying that a fool with a tool is still a fool. But how to use a tool most efficiently is not always obvious to me. Because of this I typically spend some time to check out new playgrounds1 that promise to increase my work speed without impairing quality. This way I came across EclEmma, a code coverage tool for the Eclipse IDE, which can be quite useful to achieve comprehensive test cases.
Coverage
In general ‘Test coverage is a useful tool for finding untested parts of a codebase‘ because ‘Test Driven Development is a very useful, but certainly not sufficient, tool to help you get good tests‘ as Martin Fowler puts it2. Given this, the usual way to analyse a codebase for untested parts is either to run an appropriate tool every now and then or having a report automatically generated e.g. by a nightly build.
However the first approach seems to be a bit non-committal and the second one involves the danger of focusing on high numbers3 instead of test quality. Let alone the cost of context switches, expanding coverage on blank spots you have written a couple of days or weeks ago.
Hence Paul Johnson suggests ‘to use it as early as possible in the development process‘ and ‘ to run tests regularly with code coverage‘4. But when exactly is as early as possible? On second thought it occured to me that the very moment just before finishing the work on a certain unit under test should be ideal. Since at that point in time all the unit’s tests should be written and all its refactorings should be done, a quick coverage check might reveal an overlooked passage. And closing the gap at that time would come at a minimal expense as no context switch would be involved.
Certainly the most important word in the last paragraph is quick, which means that this approach is only viable if the coverage data can be collected fast and the results are easy to check. Luckily EclEmma integrates seamlessly in Eclipse by providing launch configurations, appropriate shortcuts and editor highlighting to meet exactly these requirements, without burden any code instrumentation handling onto the developer.
EclEmma
In Eclipse there are several ways to execute a test case quickly5. And EclEmma makes it very easy to re-run the latest test launch e.g. by the shortcut keys Ctrl+Shift+F11. As Test Driven Development demands that test cases run very fast, the related data collection runs also very fast. This means one can check the coverage of the unit under test really in a kind of fly-by mode.
Once data collection has been finished the coverage statistic is shown in a result view. But running only a single or a few test cases, the over all numbers will be pretty bad. Much more interesting is the highlighting in the code editor:
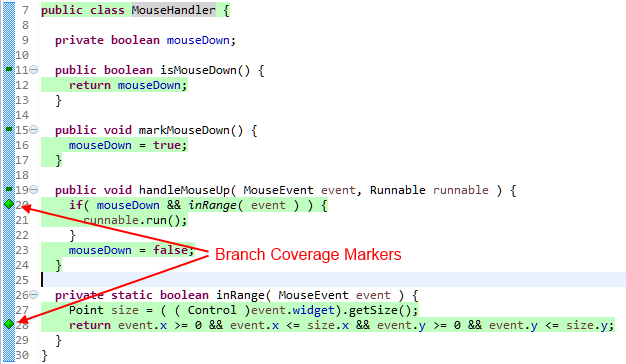
The image shows the alleged pleasant case if full instruction and branch coverage has been reached. But it cannot be stressed enough that full coverage alone testifies nothing about the quality of the underlying test!6 The only reasonable conclusion to draw is, that there are obviously no uncovered spots and if the tests are written thorough and thoughtful, development of the unit might be declared as completed.
If we however get a result like the following picture, we are definitely not done:
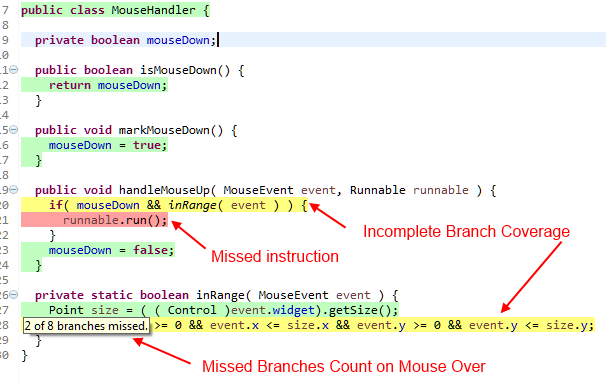
As you can see the tests do not cover several branches and misses a statement entirely, which means that there is still work to do. The obvious solution would be to add a few tests to close the gaps. But according to Brian Marick such gaps may be an indication of a more fundamental problem in your test case, called faults of omission7. So it might be advisable to reconsider the test case completely.
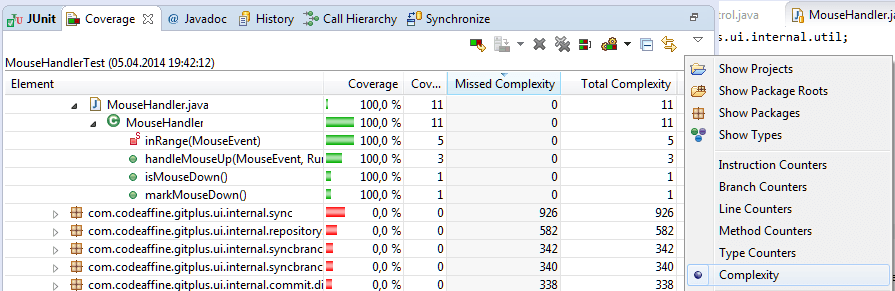
Occasionally you may need other metrics than instruction and branch counters. In this case you can drill down in the report view to the class you are currently working on and select an appropriate one as shown below:
Conclusion
While there could be said much more about coverage in general and how to interpret the reports, I leave this to more called upon people like those mentioned in the footnotes of this post. Summarizing one can say that full coverage is a necessary but not sufficient criteria for good tests. But note that full coverage is not always achievable or would be unreasonably expensive to achieve. So be careful not to overdo things – or to quote Martin Fowler again: ‘ I would be suspicious of anything like 100% – it would smell of someone writing tests to make the coverage numbers happy, but not thinking about what they are doing‘2.
Working with the approach described in this post, the numbers usually end up in the lower 90s of project wide coverage8, given that your co-workers follow the same pattern and principles, which mine usually do – at least after a while…!
- Regarding to software development such playgrounds may be methodologies, development techniques, frameworks, libraries and of course – the usage of tools
- TestCoverage, Martin Fowler, 4/17/2012
- See Dashboards promote ingnorance, Sriram Narayan, 4/11/2011
- Testing and Code Coverage, Paul Johnson 2002
- See also Working Efficiently with JUnit in Eclipse
- To make this point clear, simply comment out every assert and verification in a test case that produces full coverage like shown above. Doing so should usually not change the coverage report at all, although the test case is now pretty useless
- How to Misuse Code Coverage by Brian Marick
- Keep in mind the numbers depend on the metric that was selected. Path Coverage numbers are usually smaller than those of branch coverage and those of branch coverage can be smaller than the statement coverage’s ones
| Reference: | Efficient Code Coverage with Eclipse from our JCG partner Frank Appel at the Code Affine blog. |
