Wow, it’s been a while since I’ve written anything here. Between changing jobs, working on my PhD and moving to a new country I guess you could say I’ve been pretty busy.
But at the same time, together with all these changes in my life there’s a ton of new things that I’m learning almost every day. And, as many others, I feel that writing about them in a way that is easy for others to understand is one of the best ways to consolidate my own learning. So I’ll try to write here more often from now on.
So with that covered lets move to the important stuff. For some reason, lately I’ve been very interested in refreshing old concepts from algorithms and data structures that were a little rusty. Together with these old concepts also came some new concepts and techniques which I’ve never heard about before. But I will address them on separate posts.
On this post I wanted to talk about Dynamic Programming. If you ever took an algorithms university course then you have probably heard about it. If you haven’t, here’s a good chance to learn something extremely useful, easy and intuitive (at least when you understand it properly).
So what exactly is Dynamic Programming? I won’t go into much theory because you can already find all that if you do a simple google search. I will define it as “smart recursion” and, as usual I’ll clarify this with an example.
The classic example to explain dynamic programming is the fibonacci computation, so I’ll also go with that. The definition of the fibonacci number of a number is clearly a recursive one:
F(n) = F(n-1) + F(n-2) and F(1) = F(2) = 1
This means that the sequence of the first 10 fibonacci numbers would go:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55
You might also find it defined as:
F(0) = F(1) = 1
And so the sequence would be:
0,1, 1, 2, 3, 5, 8, 13, 21, 34, 55
For the purposes of this post this difference is irrelevant but I’ll stick to the first one.
Now, this recursive definition translates naturally and quite neatly into the following recursive method:
public static long fibonacci(int n) {
if (n < 3) return 1;
return fibonacci(n-2) + fibonacci(n-1);
}You can even make that a one liner:
public static long fibonacci(int n) {
return (n < 3) ? 1 : fibonacci(n-2) + fibonacci(n-1);
}Now that method works and it is certainly elegant but, what happens with the execution time as you start increasing the parameter n. Well, in my laptop it returns almost immediately for any value between 0 and 30. For an n of 40 it takes a bit longer: 0.5 seconds. But for an n equal to 50, it takes almost a full minute to compute the correct value.
You might think that a full minute is not a lot, but any value greater that 70 kills the application for me and any value between 50 and 70 takes too much to finish. How much? I don’t really know because I don’t have the patience to wait and see, but it is certainly more than 30 minutes.
So what is wrong with this method? Well, I haven’t talked about algorithms time and space complexity yet (I probably will in another post) so for now I’ll just say that the execution time of the algorithm grows exponentially as n increases. That’s why there’s such a big difference in time when you execute that method with n = 40 and with n = 50, because there’s a huge difference between 2^40 and 2^50.
The reason why this algorithm behaves like that is also rather easy to see by just following its execution stack for any value of n. Let’s do that for n = 6 to keep it short. The following image shows the sequence of calls that get made.
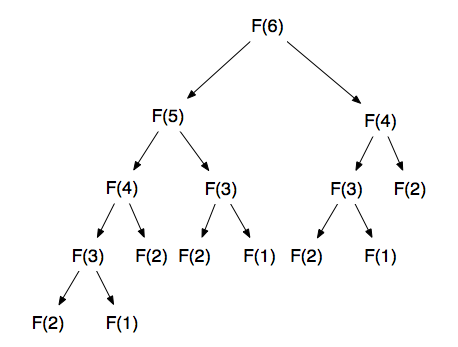
Looking at the code, we can clearly see that to compute the value for 6, we first compute the values for 5 and 4. But, similarly, to compute the value of 5 we need the values for 4 and 3 and to compute the values for 4 we need the values for 3 and 2. Once we get to 2 we can end the recursion because we know the result (which is 1).
And here is the problem with this method, notice how many times we are calling fibonacci(4) and how many times we are calling fibonacci(3). This is completely duplicated work that we are doing. Why calculate the same results over and over again if they are never going to change? Once we calculated fibonacci(3) or fibonacci(4) for the first time, we can save that result and reuse it whenever we need to.
And this is exactly what I meant by smart recursion. You can have the natural and simple recursive solution but you need to identify these situations where you are repeating work and avoid them. For n = 6 it wasn’t such a big deal, but as n grows the amount of duplicated work also grows exponentially until it renders the application useless.
So how can we go about improving this? We only need to store previously computed values and we can use any structure that we want for that. In this case, I’ll just use a map:
public static long fibonacci(int n) {
if (n < 3) return 1;
//Map to store the previous results
Map<Integer,Long> computedValues = new HashMap<Integer, Long>();
//The two edge cases
computedValues.put(1, 1L);
computedValues.put(2, 1L);
return fibonacci(n,computedValues);
}
private static long fibonacci(int n, Map<Integer, Long> computedValues) {
if (computedValues.containsKey(n)) return computedValues.get(n);
computedValues.put(n-1, fibonacci(n-1,computedValues));
computedValues.put(n-2, fibonacci(n-2,computedValues));
long newValue = computedValues.get(n-1) + computedValues.get(n-2);
computedValues.put(n, newValue);
return newValue;
}This version is obviously a bit longer that the first one-liner but it is still pretty easy to understand. We now have 2 methods, the main public one that clients call with just the n parameter and a private one that makes the recursive calls. The first method is a useful place to initialize all the necessary information we need to call the second one. This is a pretty common pattern when working with recursive algorithms.
In this case we use a Map to hold the already computed results. We initialize this map with the 2 base cases in the first method and then call the second method with this map. Now, instead of always computing the value we first check if it already is on the map. If it is then we just return that value, otherwise we compute and store the fibonacci number for n-1 and n-2. Before returning their sum, we make sure to store the final value of n.
Notice that we are still following the same structure as the first method we saw. That is, we start from n and we compute smaller results as we need them in order to solve the original problem. That’s why this approach is called top-down. Later we will see a bottom-up approach and compare both. This technique of following a top-down approach and saving previously computed resulted is also known as memoization.
How much better is this version? Well, while the first version took almost a minute to compute the value for n = 50 and never ended for values higher than that, the second memoized version gives an instant answer for any n up to 7000. That is a huge improvement but, as usual, we can do better.
The problem with this new memoized version is that, even when we are saving the results to reuse them later, we still need to go all the way down to the base case with the recursion the first time (when we haven’t computed any values yet and so we don’t have anything stored). So, imagine that we call the method with n = 10000. Because we don’t have that result yet we call the method recursively with 9999, 9998, 9997,…,2. After we start coming back from the recursion, all the n-2 values that we need will be already there so that part is pretty fast.
As with any recursive algorithm, each recursive call takes up some space on the stack. And, if we have enough of those recursive calls, the stack will eventually blow up throwing a StackOverflowException. And this is precisely what happens with our second method when we use values over 10000.
So, what’s the alternative? I mentioned before that the memoized version followed a top-down approach. The obvious thing to do is to go in the opposite direction in a bottom-up fashion. Starting from the small values of n and building the results up to our goal. We’ll still save the already computed values to use them in later stages and avoid duplication of work. This solution looks something like:
public static long fibonacciDP(int n) {
long[] results = new long[n+1];
results[1] = 1;
results[2] = 1;
for (int i = 3; i <= n; i++) {
results[i] = results[i-1] + results[i-2];
}
return results[n];
}That actually looks simpler that our memoized version. We just create an array to hold the results, initialize it with the 2 base cases and then start iterating from 3 up to n. At each step, we use the 2 previously computed values to compute the current one. In the end, we return the correct value for n.
In terms of complexity and number of computations, this version is exactly the same as the second one. The difference here is that the last version is iterative and, therefore, doesn’t take space on the stack as the recursive one. We can now compute the fibonacci sequence up to n = 500000 or more and the response time is almost instantaneous.
But we are not entirely over yet, there’s one more thing we can improve. Even though we went from exponential to linear time complexity, we also increased the amount of space required. In the 2 last versions of the algorithm, the space required to store the previous solutions is proportional to n. This is probably pretty clear in our last method, were we create an array of length n. The bigger the n the more space we need.
But you can actually see that the only two values we ever need are the last two (n-1 and n-2). So we don’t really need to keep track of all the previous solutions, just the last two. We can modify the last method to do this:
public static long fibonacciDP(int n) {
long n1 = 1;
long n2 = 1;
long current = 2;
for (int i = 3; i <= n; i++) {
current = n1 + n2;
n2 = n1;
n1 = current;
}
return current;
}Here, we replaced the array of length n by just 3 variables: the current and the 2 previous values. And so, this last method has a linear time complexity and a constant space complexity, because the number of variables we need to declare doesn’t depend on the size of n.
And that’s as good as we can get with dynamic programming. There’s actually a logarithmic complexity algorithm but I won’t be discussing that one here.
So as we were able to see from these examples, there’s nothing mysterious or inherently hard about dynamic programming. It only requires you to analyze your initial solution, identify places where you are doing duplicated work and avoid that by storing already computed results. This very simple optimization allows you to go from an exponential solution that is inviable for most practical input values to a polynomial solution. Specifically, you want to look for 2 distinctive characteristics of problems that might be solved by dynamic programming: overlapping subproblems and optimal substructure.
Overlapping subproblems refers to the nature of problems like the fibonacci sequence that we saw here, where the main problem (computing fibonacci of n) can be solved by having the solutions to smaller sub-problems and the solutions of these smaller sub-problems are needed again and again. Is in those cases where it makes sense to store the results and re-use them later.
If, however, the sub-problems are completely independent and we only need their results once then it doesn’t make any sense to save them. An example of a problem that can be divided in sub-problems but where those sub-problems are not overlapping is Binary Search. Once we discard the half that we don’t care about, we never visit it again.
Optimal substructure is closely related and it basically means that the optimal solution can be constructed efficiently from optimal solutions of its subproblems. This property wasn’t so obvious in the fibonacci example because there’s only 1 solution for any given n. But this will be more evident in future examples involving optimization of some sort.
I’ll conclude this post with some hints that I use when trying to decide whether or not to use dynamic programming for a given problem:
- Can the problem be divided into subproblems of the same kind?
- Can I define the previous division by a recurrence definition? That is, define F(n) as a function of F(n-1)
- Will I need the results to the sub-problems multiple times or just once?
- Does it make more sense to use a top-down or a bottom-up approach?
- Do I need to worry about the stack if I use a memoized recursive approach?
- Do I need to keep all previous results or can I optimize the space and keep just some of them?
On the next posts I’ll address some classic and pretty interesting problems that can be efficiently solved using dynamic programming.
Cheers!

Last version of fibonacciDP does not handle n <= 2 correctly.
This is why unit tests are great to have when refactoring the difficult parts as it reminds you of the simple cases.
long current = 1;
Great post, thanks!
Your memoized version doesn’t need “computedValues.put(n-2, fibonacci(n-2,computedValues));” since the previous line, “computedValues.put(n-1, fibonacci(n-1,computedValues));” will put it in on its way down, too.
That is completely true. But if you only leave the “n-1” part then when you first look at the code you have to actually think about the fact that the recursive implementations are filling up the map and so on.
I like the visual clarity of explicitly having the two cases there, considering that the second one will return immediately (you only get a little bit of overhead from the method call and the extra put but I think this is negligible).
Thanks for the feedback.
hellow.i have big problem.i must create a program with android but im amator but i should do it.please help me.
hamidpour91.itsu@yahoo.com
Do you have a Dynamic Programming code in java?
The examples on the article are all Java code
Great post. Thanks
Hi
Thanks for your post.
Can you give us links for your next post, where you have said you will address some classic examples which can be solved using Dynamic programming.
Nice post.
One could also do this for shorter code where everything is done in one method and with equal run-time:
static Map memory = new HashMap();
public static long fibonacci(int n) {
if (memory.containsKey(n)) return memory.get(n);
if (n <= 2) return 1;
else {
Long f = fibonacci(n – 1) + fibonacci(n – 2);
memory.put(n, f);
return f;
}
}
Great post. Thanks for the clarity.
Thanks for the post
Thanks for the article. I’ve been working on the cutting stock problem for about a year now. And you’ve just answered all my questions.
I’m a math major so coding is not one of my strengths (as of yet).
Thanks again.
That’s a very good article.
Explains dynamic programming with a very good example.
Great Article !
However, I don’t quite understand the last solution.
I think it should be
for (int i = 3; i <= n; i++) {
current = n1 + n2;
n1 = n2; // rather than n2 = n1;
n2 = current; // rather than n1 = current;
}
Thank you a lot for your explanation!
Simple and Concise explanation of Dynamic programming… Cheers !!